
Paper Reading: MLLM
一些和多模态相关的论文阅读,从 CLIP 开始,向后延伸。
前言#
本文主要是关于一些 MLLM 相关的论文的阅读工作,一些浅显的 insight 分享,以及,阅读的可能大多数是领域中的主脉络,对于刚刚入门的小白来说,或许这些论文也是值得推荐的。
Noting 的是,全部的内容都是直接基于论文阅读的,参考资料中提及的内容指,这些内容或许能够帮助读者进一步理解论文里说的内容。大的基石还是论文。
CLIP#
在 large scale 下面对 Image 和 Text 的 encoder 进行余弦相似度的对齐
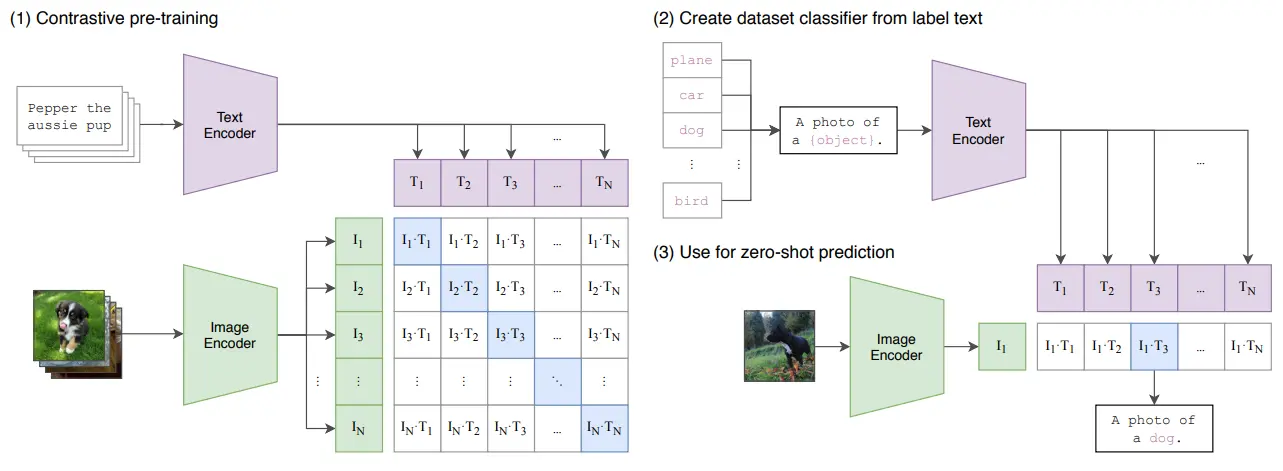
CLIP 在某种程度上也可以说是一个开山之作,虽然说对多模态的探索早在它之前就已经开始了,然而不只是数据量很大,本身对于内容处理的范式也使得 CLIP 极具拓展性,可以在很多任务中泛化。
简单理解一下 CLIP,也就是使用一个图像编码器和一个文本编码器,对于一组图像文本对进行编码,然后获得输出。接下来就是对比学习类型的工作了,需要清楚的是,相匹配的图像文本对一定是在编码之后相似度很高的,那么直接对大量输出之间的余弦相似度进行优化,是一个显然的答案。
这里面激动人心的事情,一是在进行混合,或者说再进行多模态的相似度求解的时候,可以直接使用余弦相似度这种这种方法,这证明这些编码器在经过大量数据的训练之后,确实可以将不同模态的输入投射到一个通用的 high-level 空间中。事实上由于大多数的论文都是从故事说起,因此可能会忽略,尽管在人类的概念上图像和文本可以统一于一个高层的思维中的概念,然而这种表示,在使用数学或者计算机形式的信息时是否成立,这依然是一个问号。不过从目前的实验结果来看,答案是肯定的,而后续的一系列工作也证明了,不只是图像与文本,不同的模态之间确实可以具有一种数学意义上的高维空间中的统一。
当然同时,CLIP 的 prompt template 进行 zero shot 分类的技巧也同样令人印象深刻,这本质上是对于 bert 范式在多模态领域对一种拓展。后续的工作中也涌现了一系列的对于 prompt 的应用,然而这是后话了。
参考资料:
ViLT#
双 encoder + 用于 fusion 的 transformer 的经典架构
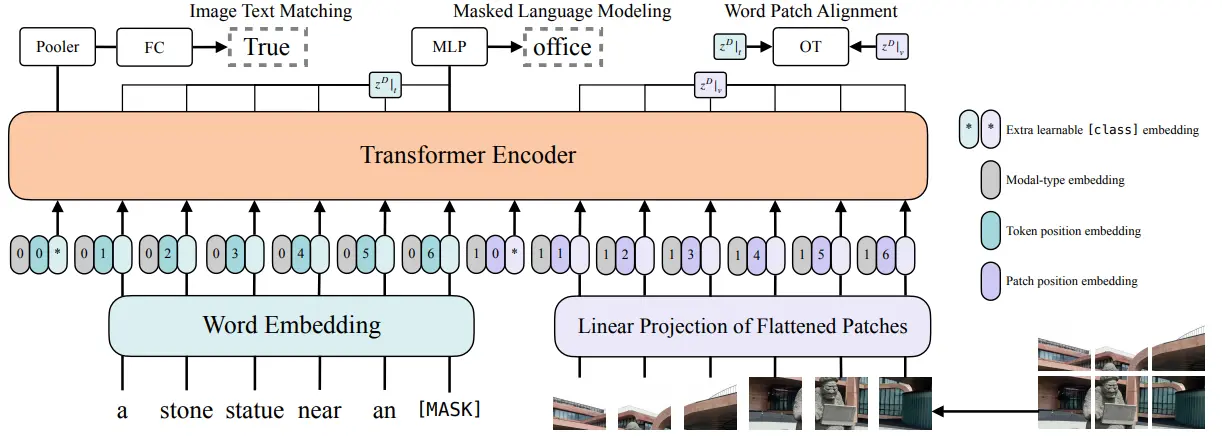
ViLT 也算是比较经典的多模态领域的工作了,这里面需要说的东西其实不多。首先需要先理清一些常规的内容,也就是 ViT 和 Transformer 在形式上究竟有什么区别。假如说我们不去关注这两个模型的输出,一个显而易见的事情是,他们的不同点仅仅在于模型的输入部分,当然对于输入的处理也有所不同。具体来说,在文本的部分使用了 tokenizer,还在图像的部分分 patch 变成 token 之后进行了一次简单的编码。借用一下后期的 insight,假如不去在意这种简单的编码的性能,已经可以理解为,视觉信息本身就是一种语言。
这篇论文首先总结了之前的工作,然后给出了一个双塔的模型的对比。具体来说,双塔的多模态模型有三个组件组成,分别是文本编码器、图像编码器和多模态编码器,这其中,这三个编码器的大小也就成了一个问题。首先需要考虑的是,当我们有固定的算力的情况下,我们应该如何分配算力给三个模型。一种最为常见的做法,是把多一些的算力分配给图像,这是由于图像本身就具有更难的编码难度,然后将两个编码器在多模态上进行简单的融合 ;之后也就是 CLIP,属于是用了一个文本和图像都很大,之后在多模态进行一个简单的编码。但是一个直觉显然是,作为多模态的任务,我们需要将多模态的进行更好地处理,给足算力,因为真正的多模态的理解,不是像 CLIP 一样进行简单的高维表征的融合,而是直接从低维信息中直接获得高维的多模态理解。所以说显而易见的,可以直接将多模态的部分变成一个 Transformer,然后将不同模态的数据进行简单的 tokenize 之后就 concat 作为输入。
在这里提供了几个 insight,其中之一是,尽管我们认为 ViLT 的这种做法比较符合直觉,但是很明显它缺乏一种泛化能力。在已经训练好的模型的基础上,假如新加入一种新模态,例如语音,ViLT 就需要重新进行一次训练,而 CLIP 将新的编码器 align 到之前的空间中即可,原来的编码器可以 frozen。虽然说这种方法并不优雅(因为三个模态同时进行训练,所获得的图像文本编码器的权重,肯定和他们两个进行训练的时候不一样,这也是因为对于三模态的输入来说,最后获得的那个高维空间,本身也会具有新模态的含义,但是尽管如此强行的对齐依然是可以的),但也能反映出来泛化能力上的不同。
另一方面的几个小技巧,包括说对于图像使用数据增强(因为没有繁重的图像编码器,所以不同于之前的方法将编码后的特征储存起来使用,ViLT 作为端到端的模型,可以直接使用图像,那么图像增强就有必要了),同时避免使用 cut 以及 color 类型的增强。
参考资料:
ALBEF#
除了在 fusion 之后添加损失,在两个 encoder 的输出上也加了损失,使得在 fusion 之前就对齐
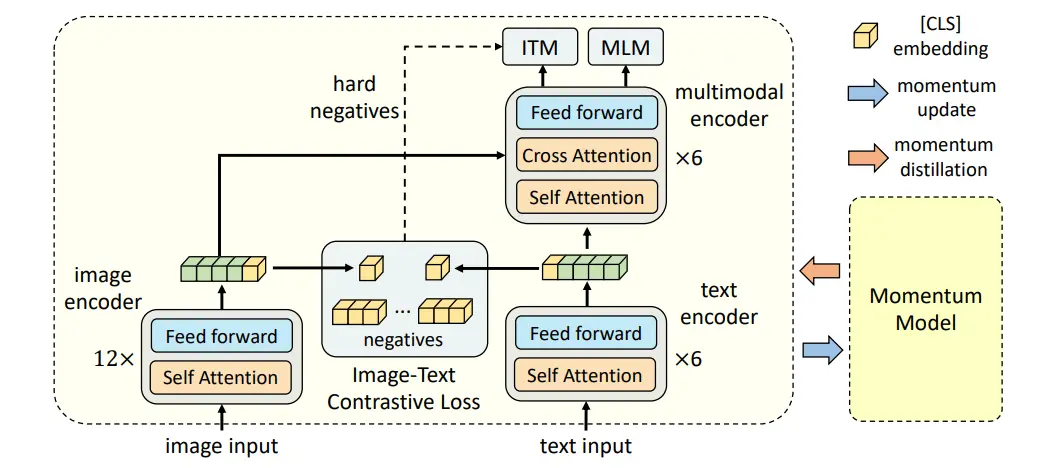
介绍一下 ALBEF,这份工作可以说也是很经典的内容了,基本来说,符合了前人工作的几个共识。首先就是,一般来说,图像编码器需要大于文本编码器,同时的话,多模态的编码器也要尽可能的大,于是使用了 12 层 Transformer 作为图像编码器,6 层文本以及 6 层多模态。同时也是用了 ITC/ITM/MLM,这几种经典的任务。
其中一个创新点在于 hard negative,也就是从 ITC 中选择最相似的难样本作为 ITM 的 negative;同时还有一个,也可以理解为是自学习或者自蒸馏,反正就是加入了一个 MT 来获得稳定表征。这里面需要注意的是,事实上在训练的过程中,数据的噪声巨大无比,而且不一定准确,因此加入一个 MT,已经不是在单模态里面的那种简单平均了,而是甚至可以生成质量远高于当前 GT 的标签,这一点在后续的 BLIP 里面也有体现,也可以说是对于数据的处理。
但是进行一个简单的拓展,之所以使用动量的方法,本质上还是因为它是 one- stage 的,假如说使用 noisy student 那种,每训练完一个模型再作为 Teacher,肯定也是没有问题的,在这里,BLIP 似乎更加出色,后续去说。
参考资料:
VLMo#
使用三个不同的 FFN 来处理不同的损失/任务,并且分阶段训练
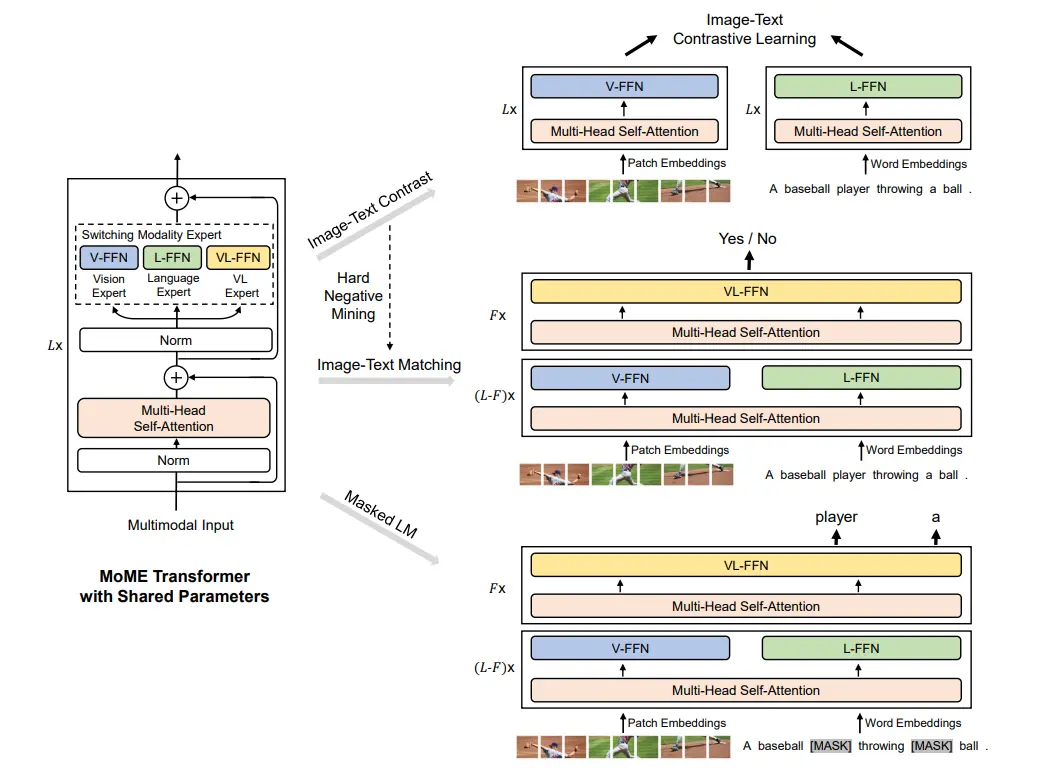
VLMo 也可以说是一个比较经典的工作,其中提出的主要就是 MoME,但是这里面,MoE 的experts 是模型自己去选择的,而在这个里面则是手动的进行切换。
大概的结构就是一个 L 层的 Transformer,但是其中的 FFN 都被换成了多个 FFN 的形式,然后在训练的过程中决定使用哪一个。
这里面的一个 insight 在于无需使用多个 attention block,而是说确实一个 attention 就可以处理完全部内容了,而且不同的 FFN 也可以接收同样的输出,并根据自己的模态进行理解。
那么对于这三个经典的 loss,ITC 可以分别激活图像和文本,最后算损失;ITM 先分别激活图像和文本若干层,之后再全交给多模态;MLM 同 ITM,从图上看起来还是十分优雅的。
最后,这个预训练的策略也比较有意思,属于是采用了分阶段训练,首先用图像数据训练图像 FFN,之后是文本,在经过了一定量的预训练之后,才是多模态。在这个里面需要注意的是,图像和文本的顺序不能换,不知道具体是因为什么。
参考资料:
BLIP#
正常的 VLMo 框架,使用 caption-filter 框架进行伪标签的生成
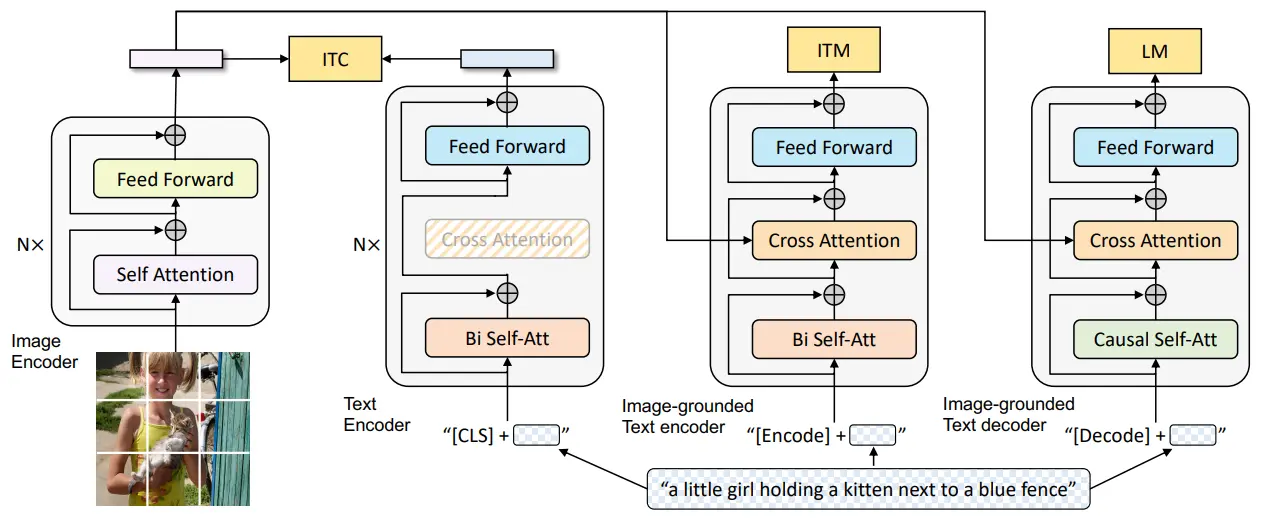
BLIP 可以说是我比较喜欢的一篇工作了,当然,基础的模型结构并没有很大的创新,本身还是 VLMo 的框架,贡献了 attention block 的参数,但是把 MLM 换成了 LM,所以这里的参数不能共享,换成了一个 casual attention。
这里面我非常喜欢的一个设计,就是它的 caption-filter 框架。这种设计其实在 ALBEF 里面已经体现出来了一些,也就是我前面说的使用 MT 的方法。但是事实上,这种方法并不完全的优雅,尽管是 one-stage,但是或许效果并不如 two-stage,更何况本身还是完全的套用之前的范式,属于是意识到了 noisy 和 pseudo label 的潜力,但是并没有完全发挥。
那么,BLIP 的这个框架就不一样了。首先是一个 two-stage,这一点无伤大雅,正如我所说的,one 和 two 的区别并不是很大,甚至说 EMA 唯一的意义在于维护一个 bank,其他情况下完全可以想象,性能应该不如 two-stage。
BLIP 的重点在于,ALBEF 只关注到了 MLM 生成的高质量,然后就直接融合进去了,这种粗糙的融合固然是可行的,但是效果不一定特别好,只能说是缓解了 noisy 的情况,因为 noisy 依然存在,只是因为 MT 的权重而被稀释了。那么一个更彻底的方案就是进行 filter,BLIP 巧妙的注意到了这种 filter 的需求和 ITM 的任务惊人的相似,于是使用 LM 进行 caption,把 caption 和 GT 一起交给 ITM 去二选一,这样最后的结果就会很好了。
参考资料:
CoCa#
只使用 Constrastive Loss 以及 Captioning Loss 来实现 One pass 以提升训练效率
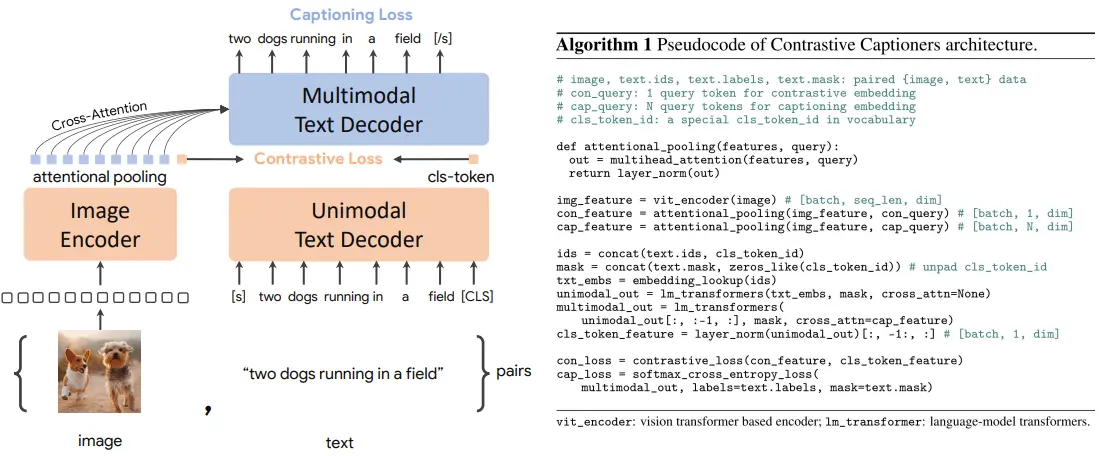
CoCa 可以说和 ALBEF 十分的相似,基本上就是和 ALBEF 一模一样,但是 CoCa 的关注点在于,之前的工作,虽然看上去从 pipeline 里面都是同时进行的输入,但是实际上在一个 iteration 里面都是经过了很多次的 forward,而 CoCa 则是希望,在同一个 iteration 里面,所有的 forward 都只进行一次,也就是所谓的 one-pass。
方法也十分简单,既然 one-pass 了,那么 scale 上去很多数据就会方便很多,毕竟计算快了很多,于是直接对文本输入直接采取 casual-attention,也不需要管数据的损失,算就完事了,于是任务也变成了一个 Co 和一个 Ca,也就是 contrast 和 caption。
所以说白了其实带来的 insight 不算多,一方面 ITC 确实有效,一方面 LM 也是一个难任务,但是在诸多 trick 之上,CoCa 的 large model 以及 scale up 的 data 显然为其性能带来的更大的影响。
参考资料:
BEiT V3#
仅使用 LM 的 VLMo
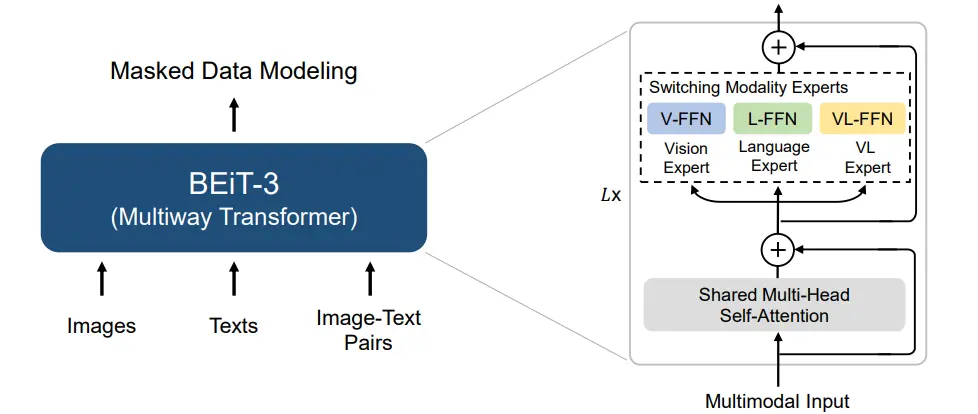
可以说 BEiT V3 本质上和之前的 VLMo 是十分类似的,但是区别在于,其只采用了一种任务,也就是 LM 任务,这自然也增加了运算的效率。之后就是通过大量的数据,以及不同 FFN 的激活,来在不同的的任务里面训练,可以说是十分的简洁。
这篇说白了也就是一个 insight,也就是阐述了 MoME 在 LM 任务下 scale up 之后确实很强,同时当然,这些 MoME 依然可以组合,再去 transfer 到不同的下游任务里。
参考资料:
BLIP2#
提出了 Q-Former,建立 bridge 并对齐模型
虽然说名字叫做 BLIP2,但是实际上感觉模型的结构上区别还是很大的,只是说任务比较类似而已。
BLIP2 的主要贡献,以及 motivation 在于,之前的模型,都是全部由自己训练的,无论是效率还是算力之类的,开销都很大,而目前领域内已经有了很多的性能很好的模型,于是直接 frozen 之后拿过来用就好。于是提出了一个 Q-former,可以对于 frozen 的图像 encoder 以及 LLM 起到桥梁的作用。
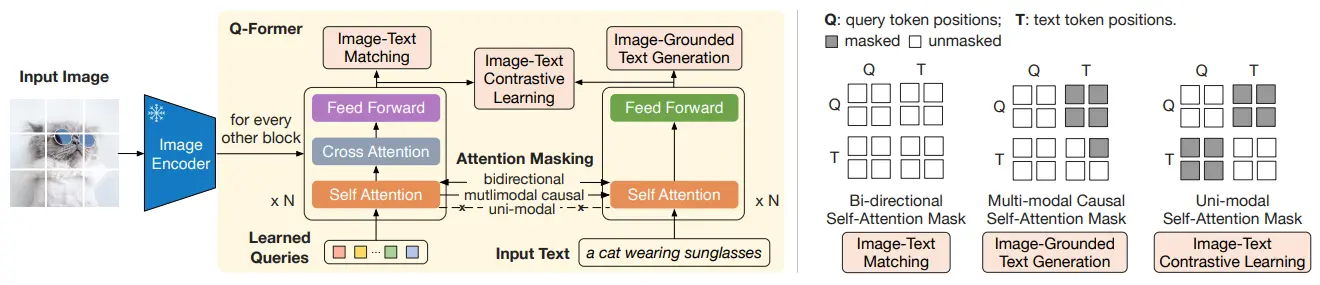
训练还是一个 two-stage,这里面 stage-1 和 stage-2 的图画的其实很迷惑,因为 Q-former 里面本质上是有两个 Transformer 的,那么后面在 stage-2 的输出,是两个 Transformer 的 concat 还是什么,就很神秘。这里一篇 csdn 的博客 的图很不错,事实上拿的是 queries 输入的那个 transformer 的输出。
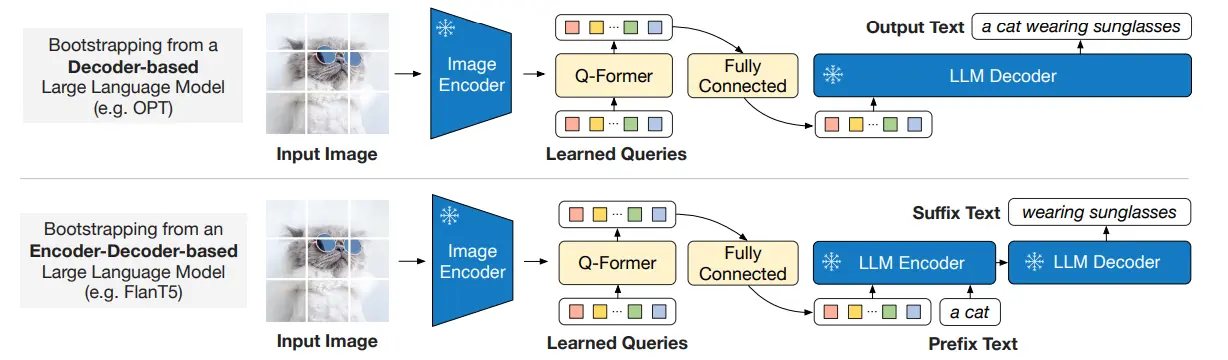
Stage-1 和正常的 ALBEF 区别不大,之后 stage-2 把输出过 MLP 送给 LLM,再进行训练。本质上假如没有 Stage-2,那么就是一个 ALBEF,而假如没有 stage-1,则是一种新的范式。那么能否抛开 stage-1 呢?毕竟 stage-2 也是一个完整的训练流程,而且也是多模态的,但是实验表明不行。一种理解是,在 Q-former 里面之所以要引入一个文本编码器,目的就是通过 stage-1 的各种任务,让图像端的 Q-former 和文本对齐,换句话说,这个 token 输入给后面的 LLM 的时候,模型说的是人话,而不是图像话,毕竟后面跟的 MLP 只是为了统一维度,本身与文本类似的语言表征,还是在 Q-former 里面进行建模的。比起来能够将两个模型拼起来,我觉得还是这个 align 的启发更大一些。
参考资料:
LLava#
使用 projector 来对齐的极简设计,简单且有效
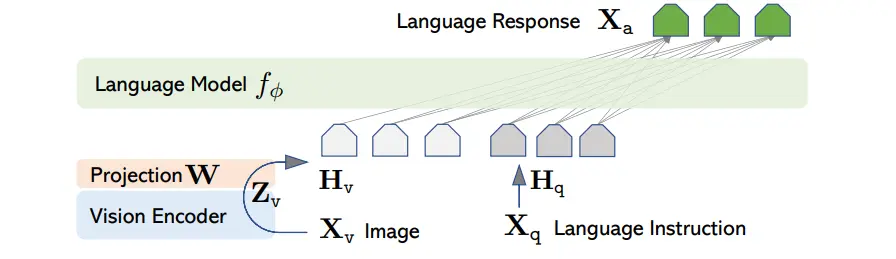
LLava 比较简单,主要是提出了一种只使用 GPT 的文字功能,就可以生成高质量 caption 的方法,简单来说,对于具有 captions 和 bounding boxes 的内容来说,其实际上具有更多的信息量可以挖掘,所以可以生成一些高质量的 hard task。
模型的结构就是一个 image encoder 之后跟一个 MLP 来映射,然后一起输入到 LLM 里面。依然训练是 two-stage 的,首先只训练 MLP 来对齐,之后训练 MLP 和 LLM 来适应具体任务。
本身的 insight 一方面对齐不需要很强的表征能力,MLP 已经足矣;另一方面高质量的数据很重要。同时 LLava 用的各种 prompt 自然也很有参考价值。
参考资料: