
欢迎来到视觉组#
欢迎大家来到视觉组,在这里简单的介绍一下视觉组的情况。
众所周知,在 RoboMaster 中存在着若干的组别,其中比较关键的是机械组以及电控组,比较不关键的是视觉组。RoboMaster 作为一个机器人比赛,机器人的稳定性往往大于功能性,而在此基础之上,由于机器人的设计十分的复杂,加之以场上的频繁碰撞,即使是最坚固的机器人也面临着 Robust 的考验,因此比起让机器人开着自瞄在场上大杀四方,机器人能够活着走下赛场明显更为重要。
很不幸,我们的队伍已经摆脱了机器人无法活着的难题了,因此压力有的时候会来到视觉组。
给出视觉组的一个定义:
在 RoboMaster 比赛中,在基础的车辆搭建以及控制的基础之上,为了在比赛之中起到更好的效果,计算机视觉被在车辆上使用,而视觉组(一称算法组)便是在工控机上使用计算机视觉等方法在比赛实现一些效果的组别。
目前来看,视觉组主要包括几大经典任务,如下:
- 自瞄:自瞄,也就是自动瞄准,是指视觉组通过程序获取相机图像,经过处理之后获得敌方车辆装甲板的信息(包括但不限于三维坐标、位姿、速度、击打所需的云台角度),并且将信息发送给电控,进而使得电控可以控制云台旋转而对车辆进行自动瞄准。
- 能量机关激活:识别某一种具有特定特征的标靶,并且预测其运动状态,在远距离进行击打,假如击打成功就可以获得一定的增幅(详情见规则手册)。此过程因为机械延迟等原因,操作手很难直接手动操作进行击打,所以需要视觉进行识别并将信息发送给电控进行击打。
- 哨兵导航:哨兵使用激光雷达对于比赛地图进行 SLAM 建图,进而通过导航技术在比赛场地中自动巡航,实现自动的导航/避障等功能。
- 视觉兑矿:在比赛中,工程机器人被要求将矿石通过机械臂送进一个角度刁钻的矿仓中,这一过程仅凭操作手的操作,一方面难度较大,另一方面则耗时较多。视觉的工程自动兑矿旨在通过视觉方案对矿仓的位姿进行估计,实现更加快捷且准确的兑矿流程。
- 雷达:雷达是RoboMaster比赛的特殊兵种,在赛场外的较高位置,通过识别敌对车辆在场地中的位置,为己方队员提供视野,并为敌方带来减益。视觉方案的雷达通过计算机视觉或激光雷达方案,对车辆进行识别、定位。
其中部分的知识具有较高的学习成本,在完成了统一的基础培训之后,将通过任务分流,并进行专项的培训。
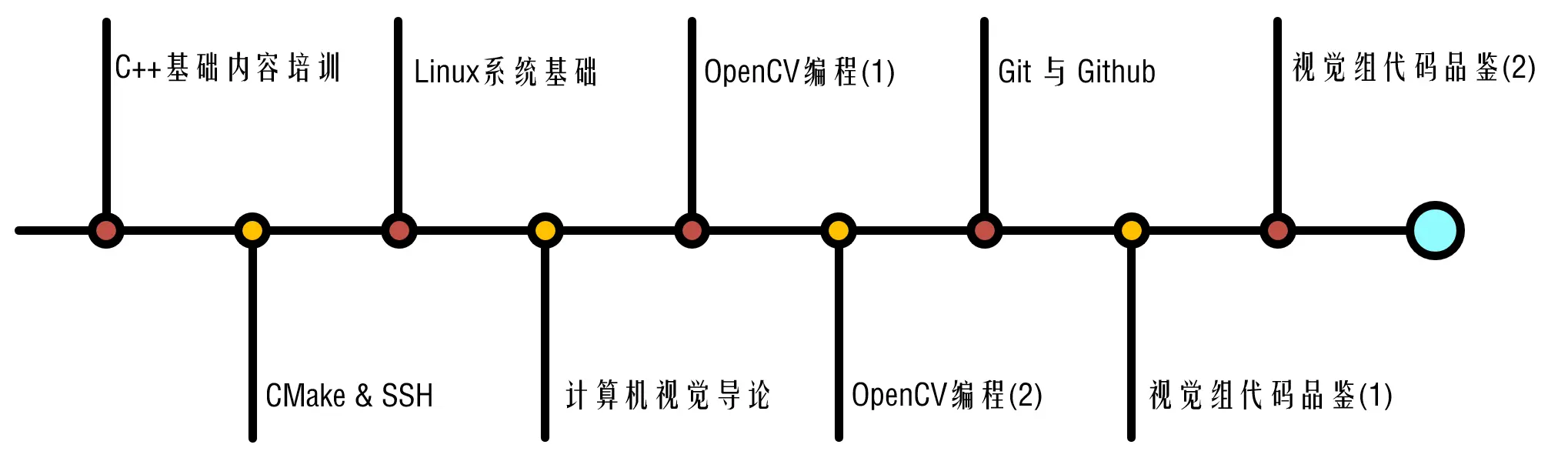
目前计划中,视觉组的基础培训主要包括以下安排:
格式#
在了解如何写文章之前,要先了解标点符号,对于编程也是如此,C++与其它语言一样,都具有其特有的格式(虽然 C++所使用的格式也被广泛用在大量语言上),在这里需要重点说明。
本段中会使用一些代码片段,你无需了解他们的含义,因为我们只需了解代码的格式,这对于代码的含义的改变至关重要。
在 C++中,两个比较关键的标点符号是空格以及 ;,同时在使用 C++进行编程的时候,需要注意除了文本、注释等内容,一切符号均要使用英文的半角符号。
其中空格起到了划分的作用,将两段字符隔开,这一点上和英语中的划分是一样的,所以并无数量限制,也就是说 int a 与 int a 的含义是一样的,不会有任何的区别。同时,需要注意的是,回车在这其中可以起到和空格一样的作用。
值得一提的是,诸如 =、+ 、-、* 等符号同样具有划分的意义。
而作为另一部分,; 的使用则重要许多,; 的唯一用法就是使用其分割不同的语句,也就是说两句话之间假如使用 ; 隔开,则意味着这是两句话而不是一个整体。
另外需要介绍的是注释,注释的意思是,注释中的内容在程序编译(一种将代码变成可以跑起来的程序的步骤)以及运行的时候都不会被看到,但是在日常的编程中,这些内容是可视的,因此可以起到解释代码的作用。
注释分为行注释 // text 与段注释 /* text */,以下给出示例:
// 这是行注释,这一行都可以作为注释,但是下一行不可以
/*这是段注释
所以只要被这两边括起来的内容都是注释
我在里面可以随意书写
这里也能写*/于是你能否理解,这两段代码的含义是一样的:
// 第一段代码
int a = 0;
std::cout<<a<<std::endl;
// 第二段代码
int a =
0
;
std::cout<<
a <<
std::endl;同时,还有一个需要提及的概念是代码块,代码块使用 {} 表示,平行的代码块之间相互独立。
{
// 代码块1
{
// 代码块2,与代码块1相关
}
}
{
// 代码块3,与1和2均无关
}变量#
程序的本质就是对于数据的处理,这句话是我说的,但是多少有一点道理。
一般来说我们粗略地区分程序,会认为程序分为两部分,也就是代码以及数据,其中代码也就是那些具备一定功能的工具,而数据则被存放在名为变量的容器中。
那么首先我们需要做的事情是选取容器。这个事情也比较好理解,比如说比较基础的字符集合,可以使用 ASCII 码表示,如下:
| 二进制 | 十进制 | 十六进制 | 字符/缩写 | 解释 |
|---|---|---|---|---|
| NUL (NULL) | 空字符 | |||
| SOH (Start Of Headling) | 标题开始 | |||
| STX (Start Of Text) | 正文开始 | |||
| ETX (End Of Text) | 正文结束 | |||
| EOT (End Of Transmission) | 传输结束 | |||
| ENQ (Enquiry) | 请求 | |||
| ACK (Acknowledge) | 回应/响应/收到通知 | |||
| BEL (Bell) | 响铃 | |||
| BS (Backspace) | 退格 | |||
| HT (Horizontal Tab) | 水平制表符 | |||
| LF/NL (Line Feed/New Line) | 换行键 | |||
| VT (Vertical Tab) | 垂直制表符 | |||
| FF/NP (Form Feed/New Page) | 换页键 | |||
| CR (Carriage Return) | 回车键 | |||
| SO (Shift Out) | 不用切换 | |||
| SI (Shift In) | 启用切换 | |||
| DLE (Data Link Escape) | 数据链路转义 | |||
| DC 1/XON (Device Control 1/Transmission On) | 设备控制 1/传输开始 | |||
| DC 2 (Device Control 2) | 设备控制 2 | |||
| DC 3/XOFF (Device Control 3/Transmission Off) | 设备控制 3/传输中断 | |||
| DC 4 (Device Control 4) | 设备控制 4 | |||
| NAK (Negative Acknowledge) | 无响应/非正常响应/拒绝接收 | |||
| SYN (Synchronous Idle) | 同步空闲 | |||
| ETB (End of Transmission Block) | 传输块结束/块传输终止 | |||
| CAN (Cancel) | 取消 | |||
| EM (End of Medium) | 已到介质末端/介质存储已满/介质中断 | |||
| SUB (Substitute) | 替补/替换 | |||
| ESC (Escape) | 逃离/取消 | |||
| FS (File Separator) | 文件分割符 | |||
| GS (Group Separator) | 组分隔符/分组符 | |||
| RS (Record Separator) | 记录分离符 | |||
| US (Unit Separator) | 单元分隔符 | |||
| (Space) | 空格 | |||
| ! | ||||
| ” | ||||
| # | ||||
| $ | ||||
| % | ||||
| & | ||||
| ’ | ||||
| ( | ||||
| ) | ||||
| * | ||||
| + | ||||
| , | ||||
| - | ||||
| . | ||||
| / | ||||
| 0 | ||||
| 1 | ||||
| 2 | ||||
| 33 | ||||
| 4 | ||||
| 5 | ||||
| 6 | ||||
| 7 | ||||
| 8 | ||||
| 9 | ||||
| : | ||||
| ; | ||||
| < | ||||
| = | ||||
| > | ||||
| ? | ||||
| @ | ||||
| A | ||||
| B | ||||
| C | ||||
| D | ||||
| E | ||||
| F | ||||
| G | ||||
| H | ||||
| I | ||||
| J | ||||
| K | ||||
| L | ||||
| M | ||||
| N | ||||
| O | ||||
| P | ||||
| Q | ||||
| R | ||||
| S | ||||
| T | ||||
| U | ||||
| V | ||||
| W | ||||
| X | ||||
| Y | ||||
| Z | ||||
| [ | ||||
| | | ||||
| ] | ||||
| ^ | ||||
| _ | ||||
| ` | ||||
| a | ||||
| b | ||||
| c | ||||
| d | ||||
| e | ||||
| f | ||||
| g | ||||
| h | ||||
| i | ||||
| j | ||||
| k | ||||
| l | ||||
| m | ||||
| n | ||||
| o | ||||
| p | ||||
| q | ||||
| r | ||||
| s | ||||
| t | ||||
| u | ||||
| v | ||||
| w | ||||
| x | ||||
| y | ||||
| z | ||||
| { | ||||
| | | ||||
| } | ||||
| ~ | ||||
| DEL (Delete) | 删除 |
这些 ASCII 码不需要背诵,但是不难理解这个 ASCII 码的集合只有 128 种。但是同理,我们不难发现,实际上的数字,比如说整数,本身的范围可以说是无限,在计算机领域,规定的整数范围(这里指 C++中的 int),则是从 。从计算机的角度来说,八组 组成一个字节,则 ASCII 码集合中的字符只需要一个字节,而整数则需要四个字节,尽管 ASCII 码构成了字符与数字的一一对应关系,使得通过数字也可以表示字符,但是假如说使用整数表示一个字符,还是会导致三个字节的空间浪费。
这种浪费无疑是需要避免的,一种在计算机语言中常用的方法就是让编程者规定容器的种类(变量类型),将这个判断交给编程者。
同时,假如说创建了一个容器(也就是变量),那么对于其他的也是存放这种类型的数据的容器,他们之间必须要有区分,这种区分通过为变量命名来实现。
// 整型,也就是整数
int a = 1;
// 单浮点数,小数
float b = 1.0F; // F 表示单浮点,但是不写也没事
// 双浮点数,小数
double c = 1.0; // 双浮点相较单浮点占用空间多但精度高
// 字符
char d = 'a'; // 字符使用''括起来,其中不能含有多个字符
// 布尔值
bool e = True; // 布尔值表示真或假
// 字符串
std::string f = "hello world"; // 字符串与前面不同,后续会讲解这里需要注意的一共有两点:
第一是命名规则,对于变量来说,明明需要满足以下规则:
- 标识符可以包含字母、数字和下划线。
- 标识符必须以字母或下划线开头,不能以数字开头。
但是更多时候,在此基础之上,我们希望每一个变量的表意明确,就像 sum 总会比 a 让人看代码的时候便于理解代码的含义。这一系列的标准我们会在后面提及。
第二是变量之间存在一种转换,分为显式转换以及隐式转换。
其中显式转换主要通过以下格式进行 value_name = (Type) value,这里面比较常见的操作是将字符以及其对应的 ASCII 码进行转换:
int a = (int)'a'; // a = 61
char b = (char)61; // b = 'a' 而隐式转换则是 C++自动实现的一种机制,约等于实现了一些默认的转换,这里给出一些例子:
double a = 1; // 自动将整型转为双浮点
float b = 1.1; // 自动将双浮点转为单浮点
double c = 3 / 2; // 此时 c 等于 1.0,整数相除保留结果的整数位
double d = 3 / 2.0; // 此时 c 等于 1.5,整数与浮点数相除结果为浮点数逻辑语句#
变量与算法在程序中缺一不可,而逻辑语句就是算法的底层固件。
我们通常使用逻辑语句进行程序的编写,实际上,基本上 C++全部的后面的特性都是建立在变量与逻辑语句的基础之上,只是对于一些功能进行了一些的拓展。
首先在这里简要说明一下运算符,一般来说我们使用的运算符主要包含两种,分别是算数运算符以及逻辑运算符,其中算术运算符就像是大家之前在日常通常会使用的,诸如 +-*/%,分别的含义是加减乘除以及取模;而逻辑运算符则是诸如大于小于之类的操作:
| 运算符 | 含义 |
|---|---|
| > | 大于 |
| < | 小于 |
| == | 等于 |
| != | 不等于 |
| >= | 大于等于 |
| <= | 小于等于 |
| ! | 非 |
| && | 与 |
| || | 或 |
一般来说算数运算符的返回值是一个数字,而逻辑运算符则是一个布尔值,但是在这里其实也没有必要完全分开这些概念,因为本质上,一个非零的数字就可以隐式转换为布尔值中的 True,而零则被转换为 False。
逻辑语句主要包含以下几种:
条件语句 - if#
条件语句 if 用于在满足给定条件时执行一段代码块。
if (条件)
{
// 如果条件成立,执行这里的代码
}示例:
int num = 10;
if (num > 5)
{
cout << "Number is greater than 5" << endl;
}条件语句 - if-else#
if-else 语句在条件成立时执行一个代码块,否则执行另一个代码块。
if (条件)
{
// 如果条件成立,执行这里的代码
}
else
{
// 如果条件不成立,执行这里的代码
}示例:
int num = 3;
if (num > 5)
{
cout << "Number is greater than 5" << endl;
}
else
{
cout << "Number is not greater than 5" << endl;
}多重条件语句 - if-(else if)-else#
if-(else if)-else 结构用于在多个条件之间做选择。
if (条件 1)
{
// 如果条件 1 成立,执行这里的代码
}
else if (条件 2)
{
// 如果条件 2 成立,执行这里的代码
}
else
{
// 如果以上条件都不成立,执行这里的代码
}示例:
int num = 7;
if (num < 5)
{
cout << "Number is less than 5" << endl;
}
else if (num == 5)
{
cout << "Number is equal to 5" << endl;
}
else
{
cout << "Number is greater than 5" << endl;
}循环语句 - while#
while 循环在满足条件时重复执行一段代码块。
while (条件)
{
// 只要条件成立,重复执行这里的代码
}示例:
int count = 0;
while (count < 5)
{
cout << "Count: " << count << endl;
count++;
}循环语句 - for#
for 循环用于指定初始值、终止条件和迭代步长,然后重复执行一段代码块。
for (初始值; 终止条件; 迭代步长)
{
// 在每次迭代中执行这里的代码
}示例:
for (int i = 0; i < 5; i++)
{
cout << "i: " << i << endl;
}循环语句 - do-while#
do-while 循环与 while 循环类似,不同之处在于它会至少执行一次代码块,然后根据条件决定是否继续执行。
do
{
// 先执行一次这里的代码
} while (条件);示例:
int num = 0;
do
{
cout << "Num: " << num << endl;
num++;
} while (num < 5);break 与 continue#
在 C++中,break 和 continue 是两种控制流程的关键字,用于在循环语句中改变程序的执行顺序。它们通常用于 for、while、do-while 等循环语句中,以便在特定条件下跳出循环或跳过当前迭代。
- break:
break 用于立即终止当前所在的循环,并跳出该循环,继续执行循环外的代码。它的主要作用是在满足某个条件时提前退出循环,从而避免不必要的迭代。
#include <iostream>
int main()
{
for (int i = 1; i <= 5; ++i)
{
if (i == 3)
{
std::cout << "Breaking the loop at i = " << i << std::endl;
break; // 当 i 等于 3 时,跳出循环
}
std::cout << "Current i: " << i << std::endl;
}
return 0;
}输出:
Current i: 1
Current i: 2
Breaking the loop at i = 3- continue:
continue 用于跳过当前循环中余下的代码,直接进入下一次迭代。它主要用于在循环中某些条件不满足时,跳过当前迭代,继续下一次迭代。
#include <iostream>
int main()
{
for (int i = 1; i <= 5; ++i)
{
if (i == 3)
{
std::cout << "Skipping iteration at i = " << i << std::endl;
continue; // 当 i 等于 3 时,跳过当前迭代
}
std::cout << "Current i: " << i << std::endl;
}
return 0;
}输出:
Current i: 1
Current i: 2
Skipping iteration at i = 3
Current i: 4
Current i: 5注意:break 和 continue 只影响最内层的循环,如果嵌套了多个循环,它们只会作用于包含它们的最近的那个循环。
地址与指针#
地址与指针#
在 C++中,地址是内存中的位置,每个变量都在内存中有一个唯一的地址。指针是一个变量,其存储的值是另一个变量的地址。通过指针,我们可以直接访问或修改其他变量的值。
定义指针#
int main()
{
int num = 42;
int *ptr; // 定义一个整型指针
ptr = # // 将ptr指向num的地址
return 0;
}在这个例子中,ptr 是一个指向整数的指针,通过 &num 可以获取 num 的地址,然后将这个地址赋值给 ptr。
使用指针#
int main()
{
int num = 42;
int *ptr;
ptr = #
// 通过指针访问变量的值
cout << "Value of num: " << *ptr << endl;
// 修改变量的值
*ptr = 100;
cout << "Updated value of num: " << num << endl;
return 0;
}通过 *ptr 可以访问指针所指向的变量的值,同时,修改 *ptr 的值也会影响到原始变量 num。
数组与指针#
数组名可以被视为指向数组首元素的指针,这使得我们可以通过指针来遍历数组。
int main()
{
int arr[5] = {1, 2, 3, 4, 5};
int *ptr = arr; // 数组名作为指针使用
for (int i = 0; i < 5; ++i)
{
cout << *ptr << " ";
ptr++; // 移动指针到下一个元素
}
return 0;
}但同时需要解释一个概念:语法糖。
语法糖(Syntactic Sugar)是编程语言中的一种特性,它指的是一些语法上的便利性或简化写法,虽然并没有引入新的功能,但却能让代码更易读、更方便编写。
其中数组的定义便是使用了语法糖,通过定义了 a[i] = *(a + i),使得对于数组这一具有连续地址的数据结构拥有了更加便捷的访问方法。
引用#
引用是 C++中的另一个重要概念,它允许我们使用变量的别名来操作该变量。引用在声明时没有自己的存储空间,它只是给已存在的变量创建了一个别名。引用一旦与变量绑定,就无法重新绑定到其他变量。
int x = 5;
int &ref = x; // ref是x的引用
ref = 10; // 修改ref也会修改x的值引用与指针的主要区别在于,引用必须在声明时被初始化,并且一旦初始化后不能再引用其他变量。
new 与 delete#
C++提供了 new 和 delete 运算符来动态分配和释放内存,这对于在程序运行时创建变量和数据结构非常有用。
int main()
{
int *ptr1 = new int; // 动态分配一个整数大小的内存
*ptr1 = 10;
cout << "Value: " << *ptr1 << endl;
delete ptr1; // 释放内存
int *ptr2 = new int[10]; // 动态分配一个整数数组的内存
delete[] ptr2; // 释放整数数组的内存
return 0;
}但务必要注意,在不再需要动态分配的内存时,使用 delete 将其释放,以防止内存泄漏。
函数#
当我们在写程序的时候,我们有的时候会发现,一些功能会被我们反复使用,但是假如说我们每一次都重写这个功能,写在 int main 中,则对于代码的可读性以及书写量都是一件不好的事情。
一种想法是将这些重复使用的功能变成一个工具,也就是函数。
什么是函数?#
函数是 C++编程中的基本构建块之一,用于执行特定任务或操作。它可以接受输入(参数)并返回输出(返回值)。函数有助于将代码分割为可重用和模块化的部分,从而使代码更易于理解和维护。
函数的声明与定义#
在使用函数之前,需要先声明(declare)它。函数声明告诉编译器函数的名称、参数类型和返回类型。函数定义(define)则提供了函数的实际实现。
// 函数声明
返回类型 函数名(参数类型 参数名);
// 函数定义
返回类型 函数名(参数类型 参数名)
{
// 函数实现
}假如没有函数的声明,函数的定义既是定义也是声明,但是不能只有声明没有定义,会出现编译错误。
函数的参数与返回值#
参数#
函数可以接受零个或多个参数,参数在函数声明和定义中指定。参数允许你向函数传递数据。
int add(int a, int b)
{
return a + b;
}返回值#
函数可以返回一个值,用于向调用者提供计算结果。返回值的类型在函数声明和定义中指定。
double divide(double numerator, double denominator)
{
return numerator / denominator;
}对于已经定义了返回值的函数,该函数必须在 return 中给出返回值,同时,存在一种返回值 void 意为无返回值,可以不写返回值 return,其等价于编译器在函数结尾自动补充 return;。
形参与实参#
实际上,在函数中,存在形参与实参这一概念,意思是形式参数与实际参数。以下给出一个经典的例子:
void swap(int a, int b)
{
int temp = a;
a = b;
b = temp;
return;
}
int main()
{
int x = 10;
int y = 20;
cout << x << " " << y << endl;
swap(x, y);
cout << x << " " << y << endl;
}执行以上的程序之后,发现 x 与 y 的值并没有变化,这就是因为此时 swap 传入的变量,其本质上意思是:
int main()
{
int x = 10;
int y = 20;
cout << x << " " << y << endl;
{
int a = x;
int b = y;
int temp = a;
a = b;
b = temp;
}
cout << x << " " << y << endl;
}这也就是为什么 x 与 y 的值均没有改变,这是因为本质的传参出现了问题。
所以根据我们之前学习的指针与引用,我们得到了两种可以修改传入变量的方法:
// 通过指针
void swap(int* a, int* b)
{
int temp = *a;
*a = *b;
*b = temp;
return;
}
// 通过引用
void swap(int& a, int& b)
{
int temp = a;
a = b;
b = temp;
return;
}具体的解释可以如上方一样将函数本身展开到 main 函数中,就易于理解了。
调用函数#
要使用函数,需要在代码中调用它。函数调用通过提供参数值来触发函数的执行,并且可以使用返回值。
int sum = add(5, 3);
double result = divide(10.0, 2.0);函数重载#
C++允许你定义具有相同名称但不同参数列表的多个函数,这称为函数重载。编译器根据提供的参数类型和数量来确定要调用的函数。
int square(int x)
{
return x * x;
}
double square(double x)
{
return x * x;
}默认参数#
函数参数可以有默认值,这使得在调用函数时可以省略这些参数。
int power(int base, int exponent = 2)
{
int result = 1;
for (int i = 0; i < exponent; ++i)
{
result *= base;
}
return result;
}
int main()
{
int square_result = power(5); // 默认使用指数为2
int cube_result = power(2, 3); // 指定指数为3
}函数返回多个值#
尽管函数只能返回一个值,但可以通过引用或指针参数实现返回多个值的效果。
void minMax(int arr[], int size, int& minValue, int& maxValue)
{
minValue = maxValue = arr[0];
for (int i = 1; i < size; ++i)
{
if (arr[i] < minValue)
{
minValue = arr[i];
}
if (arr[i] > maxValue)
{
maxValue = arr[i];
}
}
}局部变量与作用域#
函数内部声明的变量称为局部变量,它们只在函数内部可见。局部变量在函数调用结束后会被销毁。
int multiply(int x, int y)
{
int result = x * y; // result是局部变量
return result;
}结构体#
在 C++中,我们基础使用的数据结构只有诸如 int、float、double 等表述正常内容的数据内容,但是假如说我们想要统计一系列同学的身高体重,进而计算这些同学的 BMI 指数,一种想法是设置两个数组:
int main()
{
double num = 0;
cin >> num;
double* height = new double[num];
double* weight = new double[num];
for(int i = 0; i < num; i++)
cin >> height[i] >> weight[i];
}但是这种写法并不优美,于是一种想法是,我们能否创建一种变量类型来专门储存学生的身高体重以及 BMI 指数,也就是一种可以储存三个值的变量,实际上我们确实可以这么做,这种被我们人为创建的变量类型被称为结构体。
在 C++中,结构体(struct)是一种用于组合不同数据类型的用户自定义数据类型。它允许你将多个不同的变量打包成一个单一的数据结构,从而方便地管理和操作这些数据。
定义结构体#
结构体通过定义一个新的数据类型来表示,其中可以包含多个不同的数据成员。定义结构体的方式如下:
struct Person
{
std::string name;
int age;
double height;
}; // 注意这里的分号在上面的示例中,我们定义了一个名为 Person 的结构体,其中包含了 name、age 和 height 三个不同类型的成员变量。
创建结构体对象并访问结构体成员#
可以使用结构体定义的数据类型来创建结构体对象,就像创建基本数据类型的变量一样,同时,可以通过 . 来访问结构体内部的数据:
Person person1; // 创建一个Person结构体对象
person1.name = "Alice";
person1.age = 25;
person1.height = 165.5;这种访问除了赋值当然也可以输出。
std::cout << "Name: " << person1.name << std::endl;
std::cout << "Age: " << person1.age << std::endl;
std::cout << "Height: " << person1.height << std::endl;结构体作为函数参数#
结构体可以作为函数的参数传递,从而方便地将多个相关数据一起传递给函数:
void printPerson(const Person& person)
{
std::cout << "Name: " << person.name << std::endl;
std::cout << "Age: " << person.age << std::endl;
std::cout << "Height: " << person.height << std::endl;
}
int main()
{
Person person2 = {"Bob", 30, 180.0};
printPerson(person2);
return 0;
}结构体初始化#
可以使用初始化列表来初始化结构体对象:
Person person3 = {"Charlie", 22, 170.0};结构体嵌套#
结构体可以嵌套在其他结构体中,从而构建更复杂的数据结构:
struct Address
{
std::string street;
std::string city;
};
struct Contact
{
std::string name;
Address address;
std::string phone;
};结构体指针#
同样,正如正常的数据结构可以使用指针,我们人为创建的结构体也可以使用指针。
Person* personPtr = &person;在 C++中,通过使用结构体的指针来访问其成员时,可以使用箭头操作符(->)来简化操作。这种语法糖使得通过指针访问成员的代码更加清晰和简洁。
如果有一个指向 Person 结构体的指针,假设命名为 personPtr,要访问 name 成员,可以使用以下两种方式:
(*personPtr).name; // 使用括号和点号
personPtr->name; // 使用箭头操作符这里,(*personPtr).name 表示先解引用 personPtr 指针,然后使用点号访问 name 成员,而 personPtr->name 使用箭头操作符直接访问了 name 成员。
因此,personPtr->name 是对 (*personPtr).name 的一种更简洁的表达方式,它更易读、易懂,并且在处理指向结构体的指针时更方便。
类#
什么是类?#
在 C++中,类(class)是一种用户自定义的数据类型,它允许你将数据成员和成员函数组合在一起,形成一个单一的实体,以便更好地表示现实世界中的对象。类提供了一种创建自己的数据结构,以及定义操作这些数据的方法。
定义类#
定义类的方式如下:
class ClassName
{
public:
// 成员函数和成员变量声明
private:
// 私有成员声明
};public、private 等是访问控制关键字,用于定义成员的可访问性。
成员函数和成员变量#
类可以包含成员函数和成员变量。成员函数是在类中定义的函数,它们用于操作类的数据成员。成员变量是类的数据成员,用于存储对象的状态信息。
class Circle
{
public:
double radius; // 成员变量
double calculateArea() // 成员函数
{
return 3.14 * radius * radius;
}
};创建对象#
可以使用类定义的数据类型来创建对象,就像创建基本数据类型的变量一样:
Circle myCircle; // 创建Circle类的对象
myCircle.radius = 5.0; // 访问成员变量
double area = myCircle.calculateArea(); // 调用成员函数构造函数和析构函数#
构造函数在创建对象时自动调用,用于初始化对象的数据成员。析构函数在对象被销毁时自动调用,用于释放资源。
class Book
{
public:
std::string title;
Book(const std::string &t) // 构造函数
{
title = t;
std::cout << "Book " << title << " is created." << std::endl;
}
~Book()
{ // 析构函数
std::cout << "Book " << title << " is destroyed." << std::endl;
}
};访问控制#
C++中的访问控制关键字 public、private 和 protected 用于控制类成员的可访问性。
public成员可以在类的外部访问。private成员只能在类的内部访问。protected成员类似于private,但派生类可以访问。
类的声明和定义分离#
通常,类的声明(包含成员函数和成员变量的声明)会放在头文件(. h 或 .hpp),而类的定义(成员函数的实现)会放在源文件(. cpp)中。
其中,对于成员函数来说,其实现的写法为:
Typename Classname::Function(/*v*/)
{
// code
}初始化列表#
虽然类的声明以及定义可以分离,但是对于一些类中的成员来说,其必须需要一个初始值,但有的初始值在 .hpp 中无法赋值(如初始值是某一函数的返回值,.hpp 并不具备执行函数的能力),于是需要在构造函数中赋值,但是又因为构造函数开始时一切成员变量均已经创建完毕,于是会导致报错。
所以需要一种方法,在声明与定义分离的情况下,起到等效于直接在 .hpp 中赋值的效果,这种写法就是初始化列表。
在 C++中,初始化列表形式的构造函数是一种特殊类型的构造函数,用于在创建对象时对成员变量进行初始化。它在构造函数的参数列表之后使用冒号来定义,用于显式地指定成员变量的初始值。
初始化列表构造函数可以帮助避免使用构造函数体内的赋值操作,从而提高代码效率并减少可能的错误。
以下是一个示例,展示了如何使用初始化列表形式的构造函数:
class Person
{
public:
// 初始化列表形式的构造函数
Person(const std::string &n, int a) : name(n), age(a)
{
// 构造函数体内没有赋值操作
}
private:
std::string name;
int age;
};在这个示例中,构造函数的初始化列表 : name(n), age(a) 指定了成员变量 name 和 age 的初始值。使用初始化列表的好处是,它可以直接将初始值赋值给成员变量,而不需要在构造函数体内执行赋值操作。
初始化列表还可以用于初始化常量成员、引用成员和调用基类构造函数等情况。
this 指针#
在 C++中,this 是一个特殊的指针,它指向当前对象的实例。它被用来在类的成员函数中引用调用该函数的对象本身。this 指针的存在使得在类的成员函数中能够准确地访问到调用该函数的对象的成员变量和成员函数,尤其在存在同名的局部变量和成员变量时,它能够帮助解决歧义问题。
比如说在以上 Person 类中,创建构造函数:
Person::Person(std::string name, int age)
{
name = name;
age = age;
}此时函数出现了歧义,因为类中已经有名为 name 与 age 的变量,但是输入的参数中也有名为 name 与 age 的变量,此时严格来说,因为作用域问题,这里面的 name 均代表输入的变量,于是带来了表意不明。
此时我们可以如下写:
Person::Person(std::string name, int age)
{
this->name = name;
this->age = age;
}此时构造函数中的两个左值便准确地指向了类中的成员变量,而非构造函数的输入值。
也就是说,this 指针具备以下的特性:
-
隐式使用: 当你在类的成员函数内部使用成员变量或成员函数时,编译器会自动地插入
this->,即使你没有显式地写出它。例如,this->someVariable就是隐式使用this指针来访问成员变量someVariable。 -
显式使用: 在需要显式指明当前对象时,可以使用
this指针。比如,你可以在成员函数内部返回当前对象本身,例如return *this;。 -
解决歧义: 当成员函数的参数名与类的成员变量同名时,使用
this指针可以帮助解决歧义,明确地指出你想要使用成员变量而不是参数。例如:
class Example
{
private:
int value;
public:
void setValue(int value)
{
this->value = value; // 使用 this 指针明确访问成员变量
}
};- 静态成员函数: 在静态成员函数中,由于没有当前对象的实例,所以不能使用
this指针。静态成员函数是与类本身相关联,而不是与具体对象相关联的。
class Example
{
public:
static void staticFunction()
{
// 无法使用 this 指针
}
};封装、继承与多态#
封装/继承/多态是 C++ 面向对象编程的三大核心,在这里进行简短的介绍。
封装#
封装是 C++面向对象思想中最重要的一个思想。
对于类来说,或者说对象,我们对其的一个共识是,其是一个独立的个体。在程序流程中,我们往往仅关心对象在获得了输入之后能否得到我们期望的输出,于是需要我们设置为 public 的函数以及值并没有那么多。
实际上,假如暴露过多的函数接口在外部,反而会给另一位这个类的使用者(没有参与编写)以困惑,而且随意的调用往往意味着不安全。
于是就体现到了封装的思想,也就是仅暴露需要使用的接口,并且不暴露一切的变量,对于需要访问的变量来说,则使用诸如以下的写法实现:
std::string Person::getName()
{
return this->name;
}这种写法可以确保对于外界来说,大多数的内容是只读的。
进行合理封装的类会体现为其仅包含必要的接口,因此对于一个非开发者使用该类的时候,仅需要注意对象的每个方法其传参与效果即可,不需要在意类对于功能内部实现的逻辑。
继承#
成员属性#
对于对象中的变量以及方法,具有其自身的属性,决定了其调用的访问等级,分别为 public、protected 以及 private,分别意味着在类内外都可以访问、只能在类内访问且不继承给子类以及只能在类内访问但是可以继承给子类。值得一提的是,不进行声明,类中的成员属性均为 private。
父与子#
继承作为一种面向对象的高级用法,其更好的描述了面向对象对于事物抽象描述并且加以定义的流程,其中继承的语法为 class Son : 继承属性 father,实现继承操作的类被称为子类或者派生类,而被继承的则被称为父类或者基类。
其中继承属性指 public、protected 以及 private,意味着将父类中继承的比当前级别更松内容放到哪个级别中,也就是说 public 会将 public 内容放入 public,protected 内容放入 protected,protected 会将 public 和 protected 内容放入 protected,而 private 会将 public 以及 protected 内容放入 private,给出一个实例:
// 定义一个类,人,其必然拥有一些人具有的属性,如下
class Person
{
public:
int age;
int height;
int weight;
string name;
};
// 定义一个类,男性,其继承自 Person,也就是说其具备一切人具备的特征,同时还有一些作为男性的特征,比如说自己是一名男性
class man : public Person
{
public:
void speak ()
{
cout << "I'm a man, my age is" << this->age; // this 指针指向当前的类,使用->符号,后面填写当前类中的成员或者方法,进行调用
}
};多态#
多态是 C++乃至大多数面向对象的程序语言都拥有的一个特性,可以用来增加程序的拓展性,更加灵活的编写程序。
简单讲解一下一个最为基本的多态的使用场景:假如说有以下一个类,Animal,其提供一种方法,叫做 speak,会输出「动物 speak」,而 Animal 是 Cat 以及 Dog 两个类的父类,而我们希望 Cat 以及 Dog 类各自实现一种 speak 的方法,分别输出「猫 speak」以及「狗 speak」。假如说有这样的一个场景,希望其中输入一个动物,然后调用其 speak 方法,一种较为复杂的方法是依次实现参数列表中为 Cat 以及 Dog 的方法,进行函数的重载,但是还有另一种解决方案,如下:
class Animal
{
public:
void speak ()
{
cout << "Animal Speak";
}
};
class Cat : public Animal
{
public:
void speak ()
{
cout << "Cat Speak";
}
};
class Dog : public Animal
{
public:
void speak ()
{
cout << "Dog Speak";
}
};
void doSpeak (Animal &animal)
{
animal.speak ();
}
int main ()
{
Cat c;
doSpeak (c);
system ("pause");
}不难看出,这个程序的执行会将 doSpeak 函数中传入的 Cat 类当作 Animal 类并调用其 speak 方法,这样做的底气在于,因为 Cat 是 Animal 的子类,所以 Cat 中必然包含 Animal 的方法,但是这样做,因为其静态多态函数地址早绑定的原因,所以只会输出 Animal Speak,但是可以预见的是,假如说我们预想的,因为 Cat 中重新写了相关的 Speak 函数,假如说有一种方法可以调用子类的方法,而不是父类的方法,必然可以解决我们的需求,而且让整体的程序十分的简单。
VOB#
VOB 是多态的常见元素,一般来说多态一定会有这三个元素,来达成其多态的效果,而因为这其中的一些硬性的关键字等,主要出现在其他语言,以及 C++更加新的标准中,在 C++98 等中或许没有,但是其依然作为一种概念,规范着多态程序的书写。
VOB,也就是虚函数 (virtual)、重写 (override)以及父类 (base),是多态实现的三要素。
首先是 virtual 关键字,对于父类中的方法,添加了 virtual 关键字之后,会将其由本来的函数转化为一种函数指针,之后就可以实现,在调用的时候链接到子类之上。
对于子类中的方法,既然要进行多态操作,也就是要进行完全的对于本来方法的覆盖。不同于函数重载中,对于参数列表的不同,重写的要求更为极端,要求一切与原函数完全一致 (对于协变来说并不是如此,但是因为不在考核范围之类,请对其感兴趣的同学自行了解),对于一些语言,在子类的重写函数之前需要添加 override 关键字,而 c++11 的特性中也添加了 override 关键字,作为对于程序的规范,不过这都不在考虑范围内,override 这个单词本身并不必须,但是可以提醒我们对于重写这一点严格的遵守。
最后是 base,这一点在诸如 C# 等语言可以调用父类中本来应该被重写掉的函数,但是在 C++中这一点并没有实现,所以这里的 B,只是为了提醒我们其代表着当前子类与父类的某种覆盖关系。
虚、纯虚与抽象#
在一些项目的架构中,以及一些设计中,诸如上面的 Animal 案例,虽然我们已经使用了虚函数,对其进行了改进,但是事实上,并不存在一种没有准确名字的动物,可以用到输出的「Animal Speak」,也就是说,在某种程度上,虽然有这一句话没有问题,但是假如程序真正说出了「Animal Speak」,却恰恰意味着程序出了问题,所以对于一些更为「极端」的设计,当然,也是为了保证程序正常运行没有疏漏的常规操作,存在这样一种函数,其本质上完全没有任何的实现,所以假如不是通过虚函数链接到了别的函数,而是其本身直接执行,就会报错,甚至在编译阶段,编译器就会给出报错,这种函数就叫做纯虚函数,而包含了纯虚函数的类被称为抽象类,因为其中有一些方法是尚未被实现的,所以不能被实例化,而是只是作为一种程序框架中的抽象的概念而存在。
纯虚函数的写法是,不像一般的具有 virtual 的函数一样进行实现,而是写如 virtual void speak () = 0;,这样就是一个纯虚函数了。
给出一个完善的使用纯虚函数写的上述 Animal 案例供参考:
class Animal
{
public:
virtual void speak () = 0;
};
class Cat : public Animal
{
public:
void speak ()
{
cout << "Cat Speak";
}
};
class Dog : public Animal
{
};
void doSpeak (Animal &animal)
{
animal.speak ();
}
int main ()
{
Cat c;
// Dog d; 不能被执行,因为 Dog 没有实现 speak 方法,所以为抽象类,不能被实例化
doSpeak (c);
system ("pause");
}总结#
这一节主要讲解了 C++ 中的一些基础,以及类、继承、多态以及虚函数等,这些内容是 C++ 中最为基础的部分,也是 C++ 中最为核心的部分,希望读者能够理解并掌握。