
具身十日谈:数据与仿真器
数据是具身智能的基石,而基于各种方案生成的数据质量,决定了模型可以走多远。从数据入手,一窥仿真以及数据合成的体系,并探讨模型在其中的变化。
前言#
伴随着具身智能的兴起,人们逐渐发现 Block 模型性能的,往往来自于数据的羸弱。早期 RT-11 以及 RT-22 的模型,均使用了大量的现实中采集的数据进行训练,但是这种方法终归效率是有限的。
在早期的探索结束之后,处于对于端到端架构的憧憬,以及大量学界业界资源的涌入,人们开始尝试使用不同的方案进行数据的 Scaling Up。事实上大家都心知肚明,尽管架构的改进可以带来性能的提升以及更高的效率,但是已有的在 LLM 和 VLM 上的经验告诉我们,数据才是泛化的关键,而一些极端人士则会这样说:「泛化即智能」。
本篇博客从数据的视角出发,简单看下目前各种类型的数据方案,学界与业界如何生产并且利用这些数据,以及笔者所看好的仿真合成数据方案的优势与 Limitations。
Web Video#
使用广泛的互联网数据是第一种路线。研究者们相信,从广大的 Web Video 数据中可以学习到动作信息,尤其比如说 EGO-4D3 等数据集,包含了人类在各种场景下的动作信息,而他们相信这些以人类为「本体」的数据,可以为具身大模型赋予抽象的动作理解能力。
包括 LAPA4, UniVLA5, GR00T6 以及 GO-17 等模型,在架构涉及中都包括一个 IDM,即 inverse dynamic model,通过学习 video prediction 来从视频数据中提取使用了 Web Video 数据进行训练。当然,另一类利用 Web Video 的方式则是训练 World Model (Video Generation Model) 来生成视频,这部分在后面会展开描述。
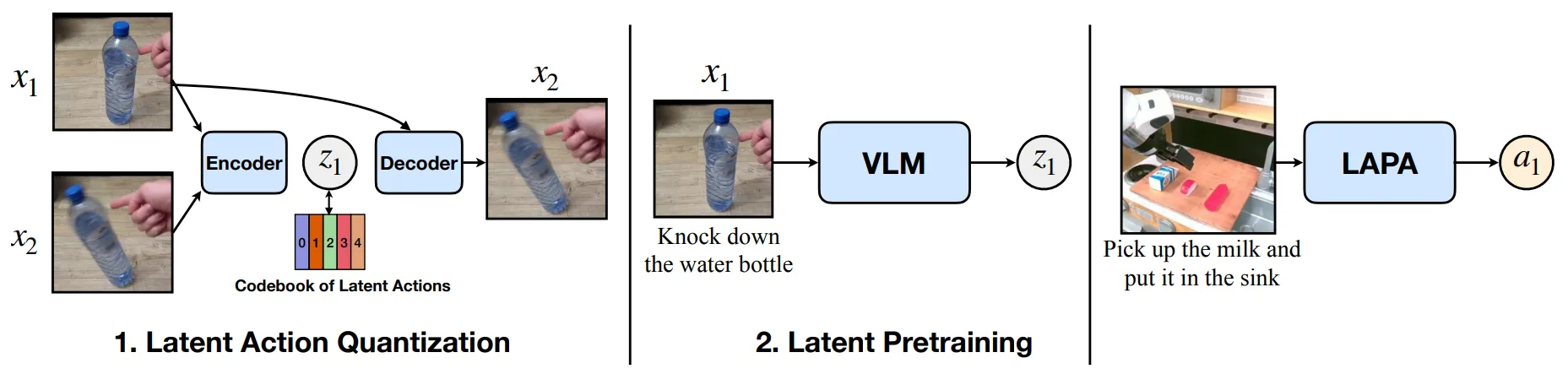
如图中所示,这类模型的本质上是通过类似 VQ-VAE 的架构,将 和 的图像进行编码,这个编码之后的结果称之为 latent action,之后通过 和 latent action 来预测 。
这个过程其实和 Robotics 里面的 FK8 以及 IK9 很类似。前者类似与 IK,从当前状态和目标求解动作,而后者类似与 FK,从当前状态和动作求解目标。因此训练处理的 Encoder 被称为 IDM,而此类型工作则使用 IDM 将 Video 数据转换为 VLA 数据。
在目前仅有 Video 的情况下,也就是一个 Image 的 Chunk,此时尚且需要 Language 以及 Action 的标注,并且这部分需要是自动化的,否则难以 scalable。Language 部分的处理相对直观,使用视频理解的 VLM 为 Video 添加语言标注即可,而对于 Action,则使用之前在 Video 数据上进行 pre-train 的 IDM。通过将视频数据输入给 IDM,IDM 可以输出 latent action 作为 A 的标注,并认为这种 A 的表征描述了前后两帧之间的变化,其中自然也含有本体的变化。因此共同组成了 VLA Data。
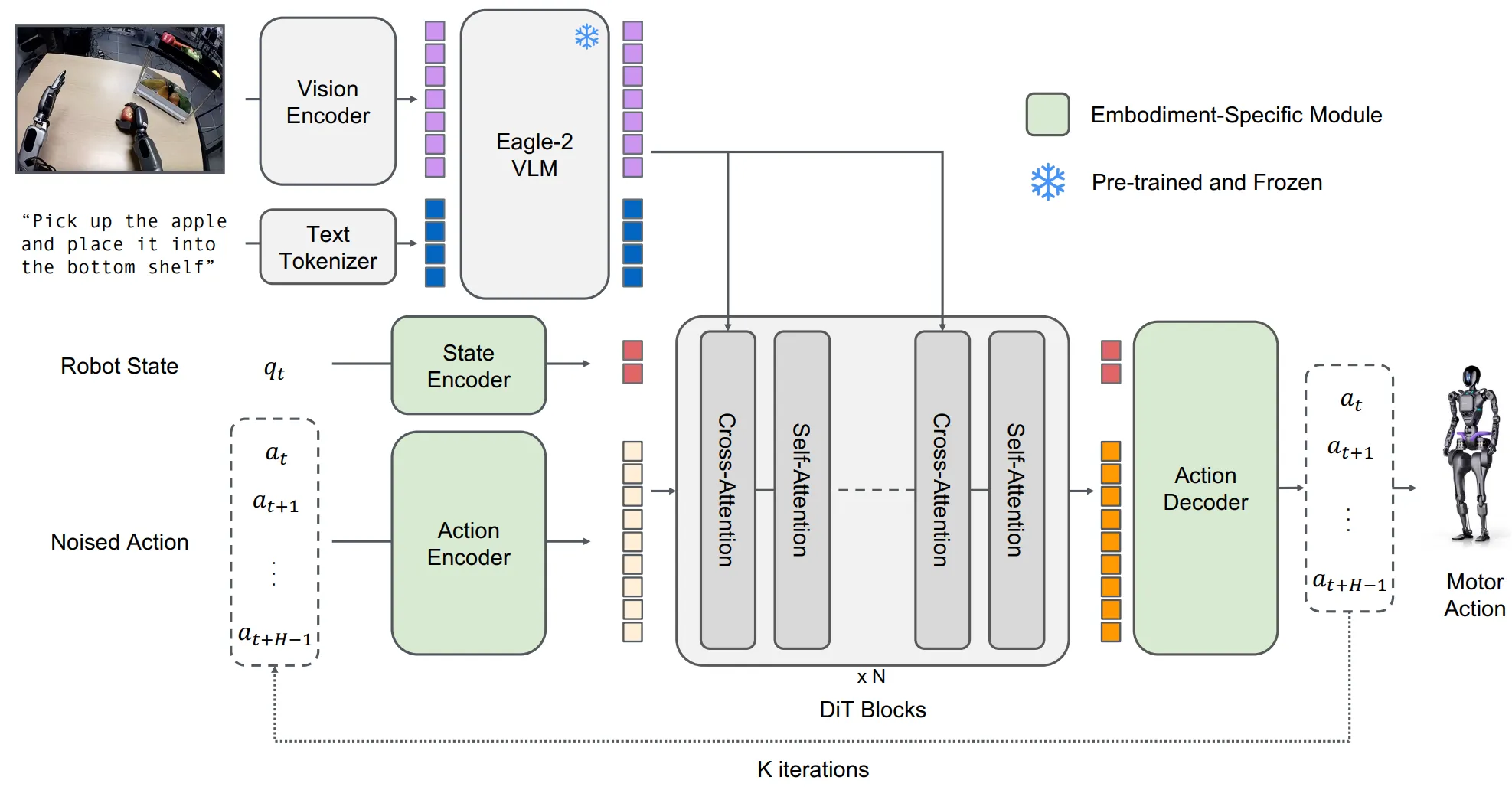
而在此之后,大多数模型本质上也都使用了常规 VLA 的架构进行了训练,本身 latent action 并没有什么特殊,这是一种和 Franka action 类似的概念等价的。
Latent action 最大的问题其实不难理解,就是训练 latent action 的过程中本质上是在描述图像之间的变化,而这种变化事实上可能并非本体(如人体)的变化导致的。不相关的变化可以简单枚举出两种,一种是环境变化,其中也包括其他的本体的变化,对环境操作之后的惯性,以及本身就是动态的环境等;另一种则是相机视角的变化,虽然说相机本身在本体上,但是相机视角的变化会带来大幅的图像特征变化,而这并不能在任何程度上代表本体本身的运动。
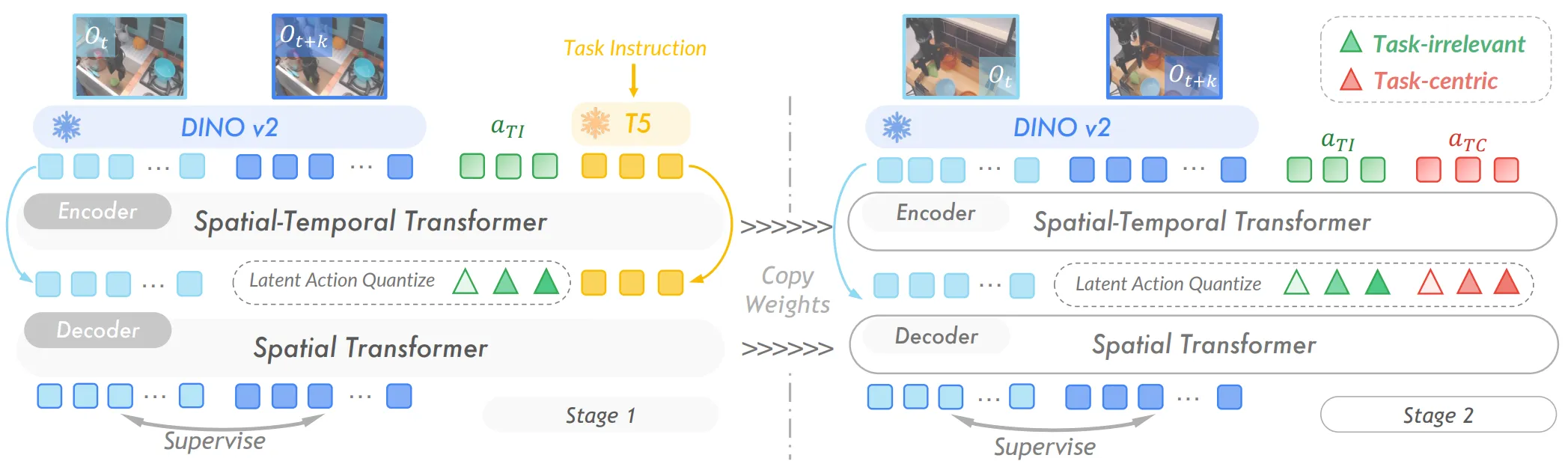
诸如 UniVLA5 等方法本质上就是在通过 Task-irrelevant 和 Task-centric 的 learnable token 来更好地提取属于本体的 latent action 部分。
数据采集#
雇佣大量的数据标注人员,进行数据采集,也是一条可行的路线,并且对于被资本青睐的具身智能这一新兴领域,未尝不是最好上手且 scalable 的路线。诸如上述提到的 RT-1 的数据集,以及后续 AgiBot 开源的基于他们机器人采集的 AgiBot-World 数据集10,都是这方面的典范。

大量的公司生产自己的机器人本体,并且雇佣大量的数据采集人员,在自己搭建的数据工厂中 scaling 大量的数据,这些数据伴随着数据采集的流程变得规范,质量也会逐渐提高。然而对于大多数公司来说,数据几乎是核心资产,在我的认知中,排除 AgiBot 之外貌似也并不存在大量开源。

尽管 LeRobot11 提供的 format 提供了很好的数据格式,并且在一定程度上统一了机器人领域的数据格式,但是目前各个工作可能开源的零星数据集本身依然难以汇聚成大规模训练的数据集,而 LeRobot 格式更大的作用还是在于大家在对齐了数据格式之后,可以快速将自己采集的数据用于公开模型的训练。
这条道路在一定的时间内似乎只对于大型公司有效,而在学界中难以普及。这主要是因为对于学界来说,整合网络上大量杂乱的数据,不只面临着数据质量的问题,同时不同视角下的异构机器人本体也会为学习带来额外的困难。目前的 VLA 学习仍然主要集中在同本体下的多任务泛化,而非跨本体的操作,因而如何筛选出合适的数据作为预训练仍然是一个很大的问题。
上述原因也进一步导致了基于真机数据采集的 VLA 模型,在学界中仍然大多数在单一任务上进行 post-training,一方面自然是算力等问题,但更多的也包括学界需要一个数据集,其中包括大量的同视角同构本体在不同任务上采集的数据。这些数据需要尽可能的多样,并且这款机器人也要尽可能地普及,而这一盛况在当今来看是难以实现的。
所以简单来说,尽管使用大量真机采集的。VLA数据对于模型进行直接的预训练是最简洁且本质的方法,而且数据工厂在业界开始逐渐普及。不过那些具有自己研发的本体的公司在数据工厂中大量采集数据之后,由于其不开源的特性,对于学界来说依然难以拥有统一的大量同本体预训练数据,而只能依赖公司开放的预训练权重,或者通过其他方式生成数据。这也为后续的内容带来了存在的必要性。
Video Gen 与 World Model#
伴随着 Sora12 的火爆,Video Gen 逐渐进入了人们的视野,而随着近期视频模型的进一步升级,如 Veo-313 等生成模型可以生成超高质量的视频,至于 Genie-314 的横空出世,可交互的 3D 视频生成也逐渐展现着可能性。同时,通过类似的范式,人们也可以用来生成机器人的数据。
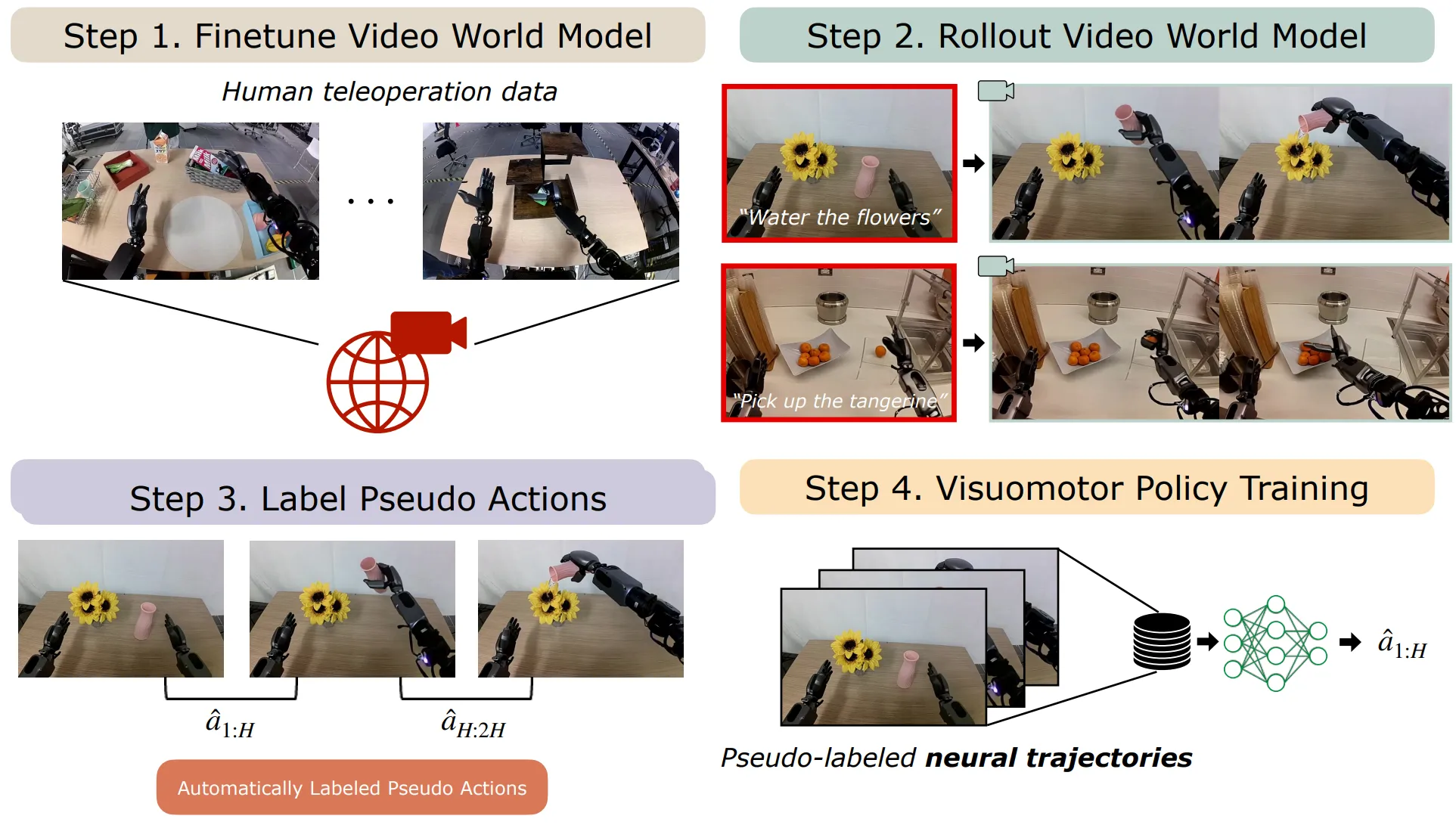
诸如 DreamGen15 等工作通过 Cosmos 等管线生产合成的视频,并且将其用于模型训练的数据,也可以达到不错的性能。
然而,当前基于世界模型的数据生成管线依然具有大量的不确定性,其主要就来自于机械臂本体动作与视觉上一致性的保持问题,也就是机器人的动作是否与视觉上的变化一致。而更进一步,对于深度估计等内容本身,单目深度估计已经存在一定的难度,因此一致性仍然难以保持。
因此视频生成的管线生成的质量不高的数据是否可以在大规模的预训练中带来 VLA 的泛化性也是一个问题,更何况当前学界大多数的视频生成模型依然在泛化上具有一定的局限性,而引入业界的视频生成模型,依然是一件有待完成的事项。
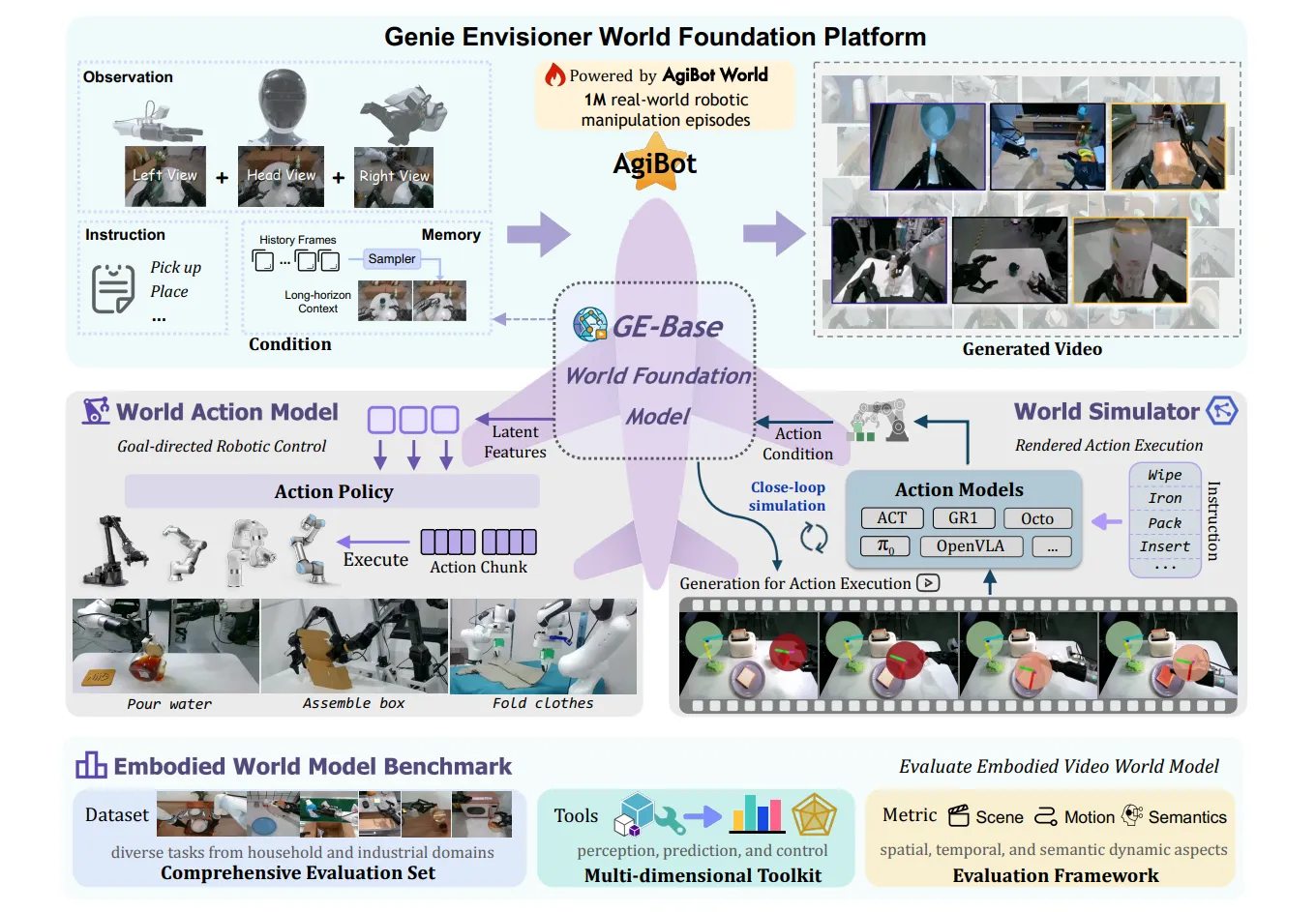
利用视频生成或者说是 world model 的另一种方式则是将其直接作为 VLA 的一部分,GR-116 以及 GR-217 在很早期就进行了相关的探索,而直到近期如 Genie Envisioner18 等方法,构建一个 VLA 所需要的实时推理的模型,同时还具有较高的视频生成质量,暂时来看仍然是一个 trade-off。
至于对于学界对于 VLA 起始的期望,一个端到端的可以理解任务并且推理,然后输出动作完成任务的模型,对于 World model 来说似乎依然有些强人所难。无论是图像还是视频生成,因为其中多半并不包括隐式推理的过程,而是直接进入类似 DiT 的流程中,因此仍然无法生成诸如 「1 + 1 个苹果」,更何况拆解或者分析更加复杂的指令并且进行泛化。
仿真平台与数据合成#
得益于计算机图形学在内的发展,物理仿真引擎以及配套的基于光线追踪等技术的渲染引擎构成的仿真平台应运而生,并且提供了仿真数据的生成方式。使用仿真来生成数据是最广泛的数据生成路线。

Isaac Sim19 作为 Nvidia 推出的强大仿真器,在渲染方面具有着得天独厚的优势,在后续被广泛应用于具身智能的仿真数据生成中;而另一方面,MuJoCo20 的仿真器则在刚体仿真上具有着更好的表现。除此之外诸如 Genesis21 等仿真器,尽管当前对于渲染仍然会带来巨大的性能开销,但是其对于流体软体的仿真以及其运行速度。作为新生代也展现了一定的前景,并在 RL 上已经可以进行了应用。
2025 年上半年 Nvidia 宣传的 Newton22 基于 Mujoco Warp 以及 USD 的体系,继承了 Isaac Sim 优质的渲染质量,也展现了更多的可能性。

我们不得不承认的是,使用仿真框架生成数据是不可能生成大量无穷任务的数据的。对于流体或者软体的仿真在仿真数据生成中仍然具有较大的局限性,乃至于生成叠衣服的数据可以成为一个独立的赛道,也诞生了诸如 DexGarmentLab23 等工作。而另一方面,使用仿真意味着需要积累大量的 3D 资产,这样才能构建尽可能多样的场景,并且生成尽可能多样的数据,这也为相关内容的积累提出了挑战。
Rule-based 与 RL#
一般来说,仿真数据的生成分为两条主要的方式。一种是通过手写规则的 rule based 方法,而另外一种则是基于 RL 实现。
所谓 rule base,也就是使用大量的手写规则来进行数据的生成,在早期学界对于每个任务进行 hard-code 的规则编写,这意味着并不 scalable,并且需要耗费大量的人力进行调参。
不过在后续流程的优化中,对于 pick and place 这一类型的任务,本质上已经可以使用一种 general 的规则生成 diverse grasp pose 的数据,并且在大规模的资产上进行 scaling up。如 GenManip24 使用 scene graph 作为 goal 的表示,可以使用简短的语句来描述任务,并且快速生成 long-horizon 的 pick and place scaling up 数据而无需任何参数调试,并且使用 mimicgen25 来进行 articulation 操作,在跨 GPU 的集群中并行。
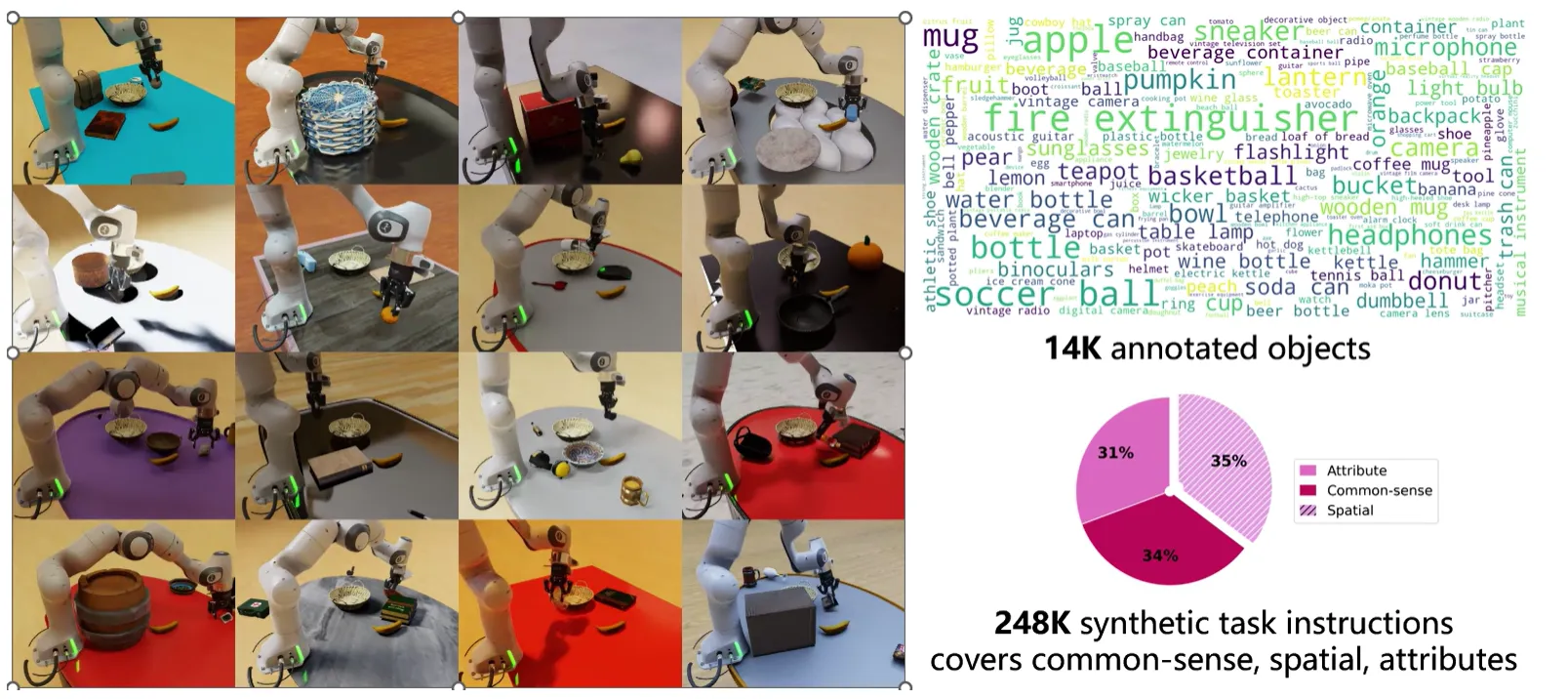
同时如 ArticuBot26 等方法也展示对对于 1 自由度的 articulation object,同样可以使用 rule base 的方法进行泛化的数据生成。而笔者也了解到相关的工作也在类似的方面进行了探索,事实上 SHAILAB 的 InternData27 之中的 M1 来自于 GenManip Framework,而 A1 则来自于在 articulation 以及 digital task 方面探索更多的框架。数十万高质量对齐的 scaling up 数据毫无疑问是学界所需要的。
而另一方面,RL 则是一种更加灵活的方式,通过强化学习的方式,理论来说只通过设置 Goal 就可以生成更加多样化的数据。然而目前来看,相较于已经可以做到泛化 rule 的 rule based 方案,RL 的优势并不多,甚至体现了部分的 limitations。
例如 RL 难以泛化到多任务,因此在采集数据的过程中可能需要反复训练模型,才可以收集更加 diverse 的数据,相较于 rule-based 的 training free,伴随着资产量级的增加,这一限制会显得越发明显;同时对于 Manipulation 的 dense reward 对于 RL 来说也难以进行泛化的设置,因此 RL 收集到的数据往往在关键动作上稳定,而在不同动作之间的衔接上因为没有 reward 的变化而乱动,这一点在诸如 RoboGen 中展示的 demo case 中有一个直观的展现。
仿真的多样性#
无论如何,读者不难预见的是,伴随着 rule base 的方法在更多的技能上的应用以及泛化的增强,仿真数据可以逐渐覆盖更多的技能种类以及任务类型。此时的问题忽然变成了,当仿真可以做到真实世界中相应的任务,那么为什么我不使用真实世界,而是要使用仿真数据?毕竟众所周知,sim2real 一直以来都是仿真中的一个重大难题,尽管使用诸如 GS 等方案的方法已经可以进行缓解,但是 GS 又带来了更多的 workload 以及资产的稀缺。
事实上,几个简单的例子可以说明仿真数据在一定程度上的优越性。比如说对物品多样性的覆盖,scaling up 数据的一个经典案例是在杂乱桌面上对于不同的物体进行 pick and place 操作。在仿真平台中,可以对于桌面物体进行快速的替换,并且覆盖上百乃至数千种物体,从而产生大量多样性的组合。而对于真机数据采集来说则更加麻烦,需要重新布置桌面,从库房或者物资管理获得新的物品,之后进行漫长的摆放以及布置,才可以采集一条数据。
出于这种特性,读者不难发现大多数真机数据集中任务种类较少(假如认为 pick A to B 当 A 与 B 不同的时候是不同的任务),但是可以涉及更加灵活的操作以及任务种类。而仿真中则任务数量较多,而技能种类则相对有限。

再包括仿真中可以灵活替换的贴图以及光照和机器人本体的各种设置,以及仿真可以输出如 depth、affordance 以及 semantic mask 等信息的 GT,仿真平台以及合成数据似乎是天生为预训练而生的,在大量仿真数据中将 VLM 与 A 之间的 bridge 构建,并且在真机数据中进一步强化模型对于技能种类的掌握,这或许是对于 VLA 的一条可行路线。
小憩#
一口气看了这么多,不妨歇息一下,喘口气。本博客主要介绍了当前不同的数据方案,以及对应的相关工作、模型如何利用这些数据以及limitations。其中也包括了本人自己的一家之言,略有见解,多有爆论,还望见谅。也欢迎读者在评论区进行积极讨论。
脚注#
-
EGO-4D: https://ego4d-data.org/ ↑
-
UniVLA: https://arxiv.org/abs/2505.06111 ↑ ↑
-
AgiBot World: https://www.bilibili.com/video/BV1Qw6gYXEyh/ ↑
-
Sora: https://openai.com/sora/ ↑
-
Genie-3: https://deepmind.google/discover/blog/genie-3-a-new-frontier-for-world-models/ ↑
-
DreamGen: https://arxiv.org/abs/2505.12705 ↑
-
Genie Envisioner: https://arxiv.org/abs/2508.05635 ↑
-
Isaac Sim: https://docs.isaacsim.omniverse.nvidia.com/latest/index.html ↑
-
MuJoCo: https://mujoco.readthedocs.io/en/stable/overview.html ↑
-
Genesis: https://genesis-embodied-ai.github.io/ ↑
-
News about Newton: https://developer.nvidia.com/blog/announcing-newton-an-open-source-physics-engine-for-robotics-simulation/ ↑
-
DexGarmentLab: https://wayrise.github.io/DexGarmentLab/ ↑
-
GenManip: https://genmanip.axi404.top/ ↑
-
MimicGen: https://arxiv.org/abs/2310.17596 ↑
-
ArticuBot: https://arxiv.org/abs/2503.03045 ↑
-
InternData-M1: https://huggingface.co/datasets/InternRobotics/InternData-M1, InternData-A1: https://huggingface.co/datasets/InternRobotics/InternData-A1, InternData-N1: https://huggingface.co/datasets/InternRobotics/InternData-N1 ↑