
前言#
我们假设有这样一种情况,你需要一些分数,或者一些项目经历,或者你想要水一些比赛,所以你看到了你的学校的群里,有医学相关的同学在招募编程同学,然后你看到了这个机会,然后你就开始了你的水项目之旅。
所以你和他们说,要不然我们来做一个医学影像分割的项目吧,我们有一些数据之后,训练一个分割模型,看上去就很炫酷,而且我们可以将一些故事,比如说可以这个系统可以帮助医生提高工作效率云云,毕竟只是一个项目,已经可以交差了。他们说,好的,那么我们来提供数据,然后标注数据,你来负责训练模型,然后我们就可以开始这个项目了。
标注数据#
首先,你的队伍一定联系到了某个老师,所以手头已经有了一些无标注的数据了,比如说几百条,这些数据都很奇怪,你不知道如何读取以及标注。
DICOM 是医学影像中非常常见的数据格式,我们一般直接读取 DICOM 的数据,并且进行数据集的标注,在此之前你需要先下载 ITK-SNAP。
下载 ITK-SNAP#
ITK-SNAP 是医学影像分割方面常见的数据集标注工具,为了安装这个软件,前往 ITK-SNAP 官网下载,选择下图:
选择跳过注册:
点击下载链接:
之后会跳转到 SOURCEFORCE,等待五秒钟之后自动下载:
会下载到一个安装程序:

安装 ITK-SNAP#
点击这个 .exe 应用以安装,选择 下一步-我接受(I) :
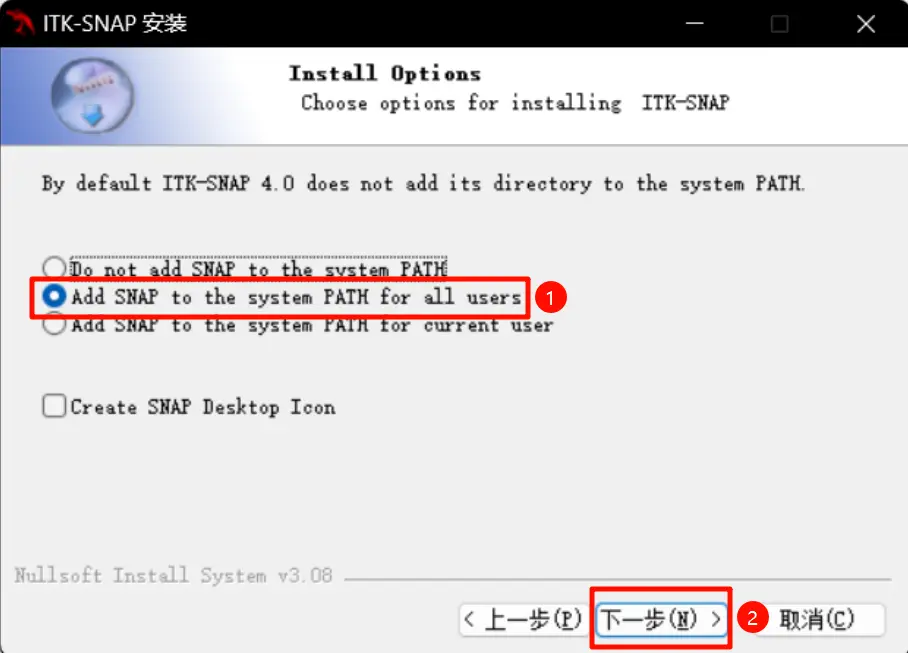
如上图,选择 Add SNAP to the system PATH for all users;对于不善于使用电脑的同学,勾选 Create SNAP Desptop Icon,以免之后找不到软件。
选择安装目录,找个地方,别放 C 盘,尽量显眼一些,或者你有一套自己管理软件的逻辑,后续可能需要你找到这个目录,因此别忘了。
之后继续下一步,在开始菜单也创建一个快捷方式,之后勾选 runtime:
点击安装,稍等片刻,假如有一个报错说什么 too long can’t add to PATH,不用管,假如存在其他报错,请向我反馈。
ITK-SNAP 的使用#
按下 win 键,输入 ITK-SNAP,或者选择所有应用并找到 I 列,点击打开 ITK-SNAP。
我们的 CBCT 文件的格式是 文件,而其本身是 DICOM 文件。
打开图像#
选择 File - Open Main Image:
在这里有必要说的是,这里需要打开的是,将某个压缩文件解压之后,进入 exam/xxxxxxxx/xxxxxxx 里面,打开的是 I0000000 文件。
选择 Browse,找到一个文件,点击并打开:
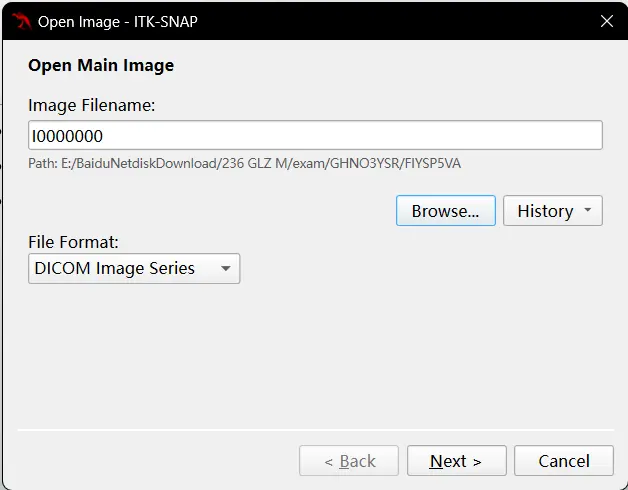
File Format 会自动改为 DICOM Image Series,意味着成功,点击 Next-Next,在 Reading Image 读条之后在小窗点击 Finish,就可以看到界面了。
如下图,三个图像是影像的三个面,将光标放到其中的一个上面,滚动鼠标滚轮,可以看到图像在变化,这是这个界面对应的面的深度在变化:
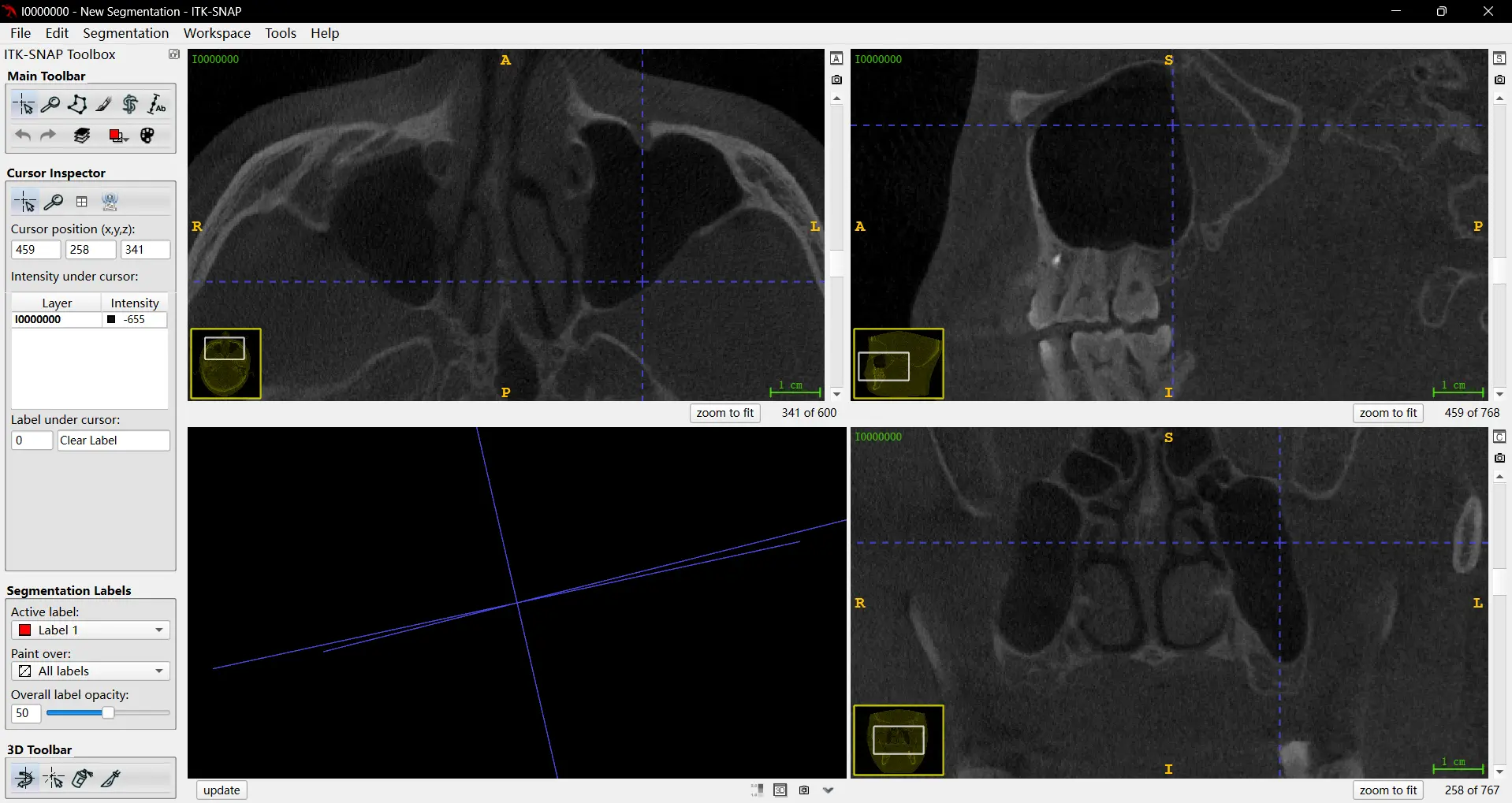
可以注意以下两张图片的右下角数字变化:
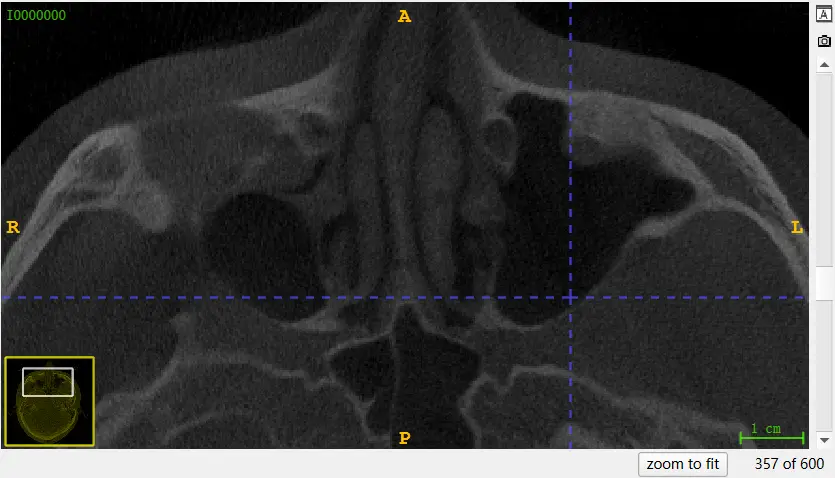
这是因为医学影像数据本质上是将许多张图片叠在一起,从而组成的立体图像,滚动鼠标滚轮等于在浏览这一叠图片的不同图。
标注数据#
注意左侧栏,其中是你需要用到的工具:
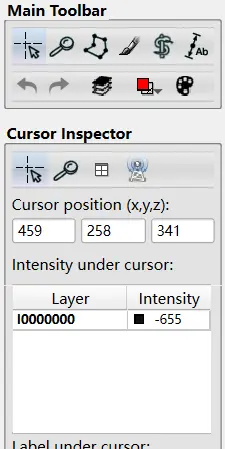
首先是 Main Toolbar 的第一个,光标,就是可以正常进行拖动。你可以看到每个界面上均有一个十字线,可以理解为这是另外两个于本平面正交的平面在这个平面上的投影,这个十字线在长按左键之后可以用鼠标拖动,看到本界面图像不动,其他界面图像改变,自行体会其中玄奥。
本质上我们只与一个窗口交互即可,上一段内容不必理解。
其次是 Main Toolbar 的第三个,Polygon,可以理解为一个选框分割器,选择之后在下方的 Polygon Inspector 中选择 Smooth curve:
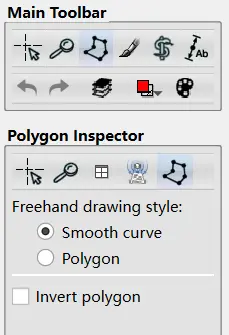
用左键在右侧窗口画图,这里使用左上角这个面:
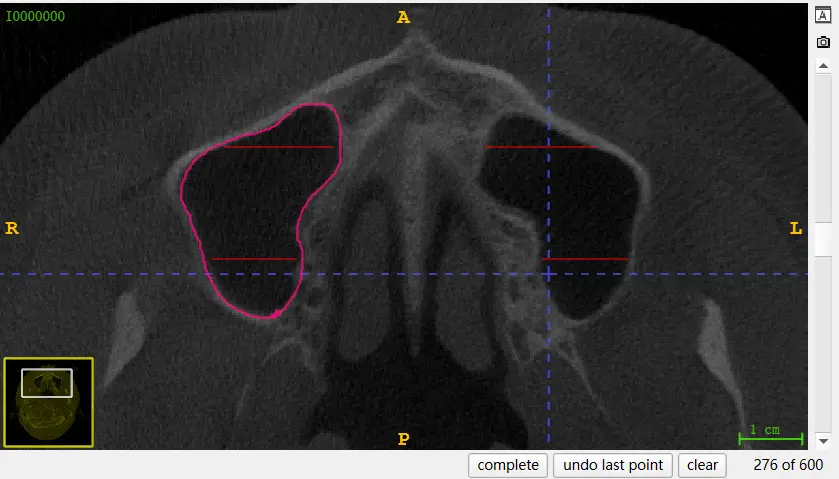
其中红色部分为之前画的,粉色为目前画的,曲线需要闭合,但是可能出现途中看似闭合但是则没有闭合的情况,点击右下角 complete,自动闭合,线段变为红色,假如本身就闭合,连接之后应该直接为红色。
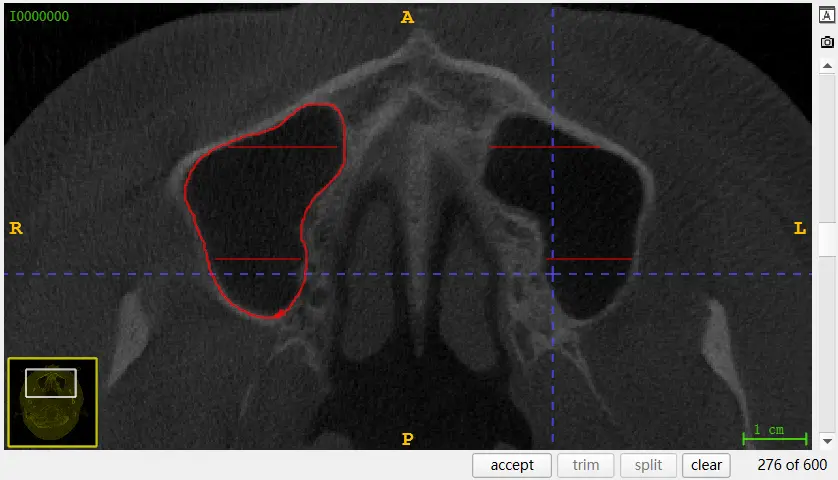
选择假如说曲线符合需求,选择右下角 accept,自动填充。
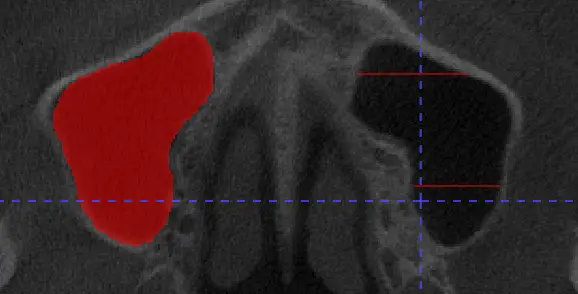
假如画出了自己不理想的曲线,如下图:
![]()
选择 clear,这个线被清空。
假如说画的内容不是很理想:
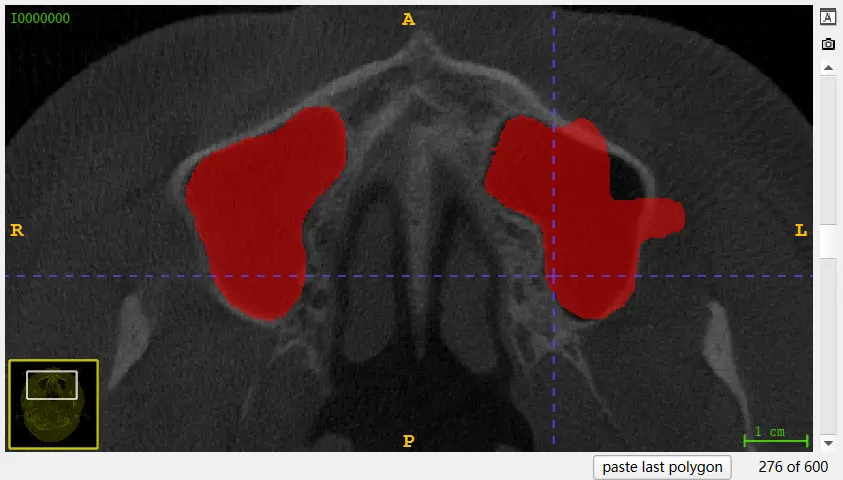
也可以选择 accept 之后细调,选择 Main Toolbar 的第四个,Paintbrush,这就是一个画笔,在下方可以调整 brush size 以及 brush style,简单易懂。在右侧来说,左键画,右键擦,擦除对于一些中间不需要选取的内容格外重要,可以先选框再擦除:
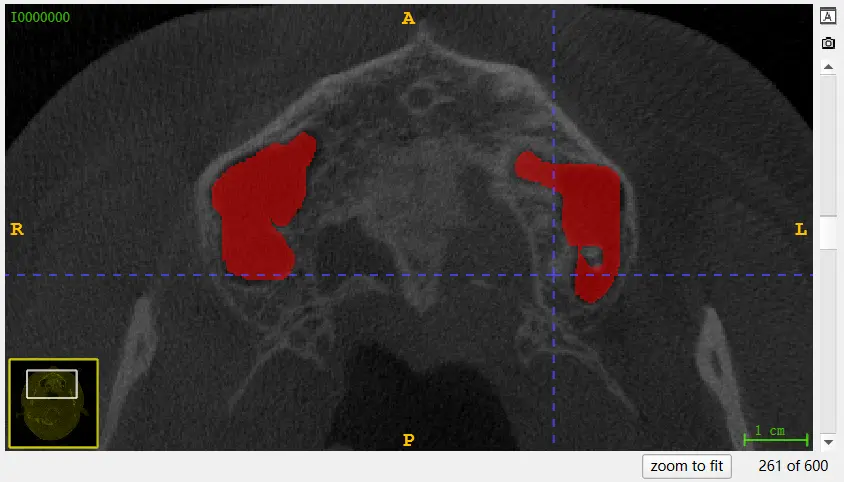
这一张标注完了之后,继续。
增加 Label#
假如说要标注牙齿,我们要识别不止一个牙齿,所以说我们需要把牙齿分成不同的 Label,这将会增加工作量,具体我们一起看一下。
首先需要在设置区里面设置一下 Label 的数量,因为默认的 Label 数量实际上是 6 个,但是我们需要有 32 个 Label,所以需要在软件里面设置一下:
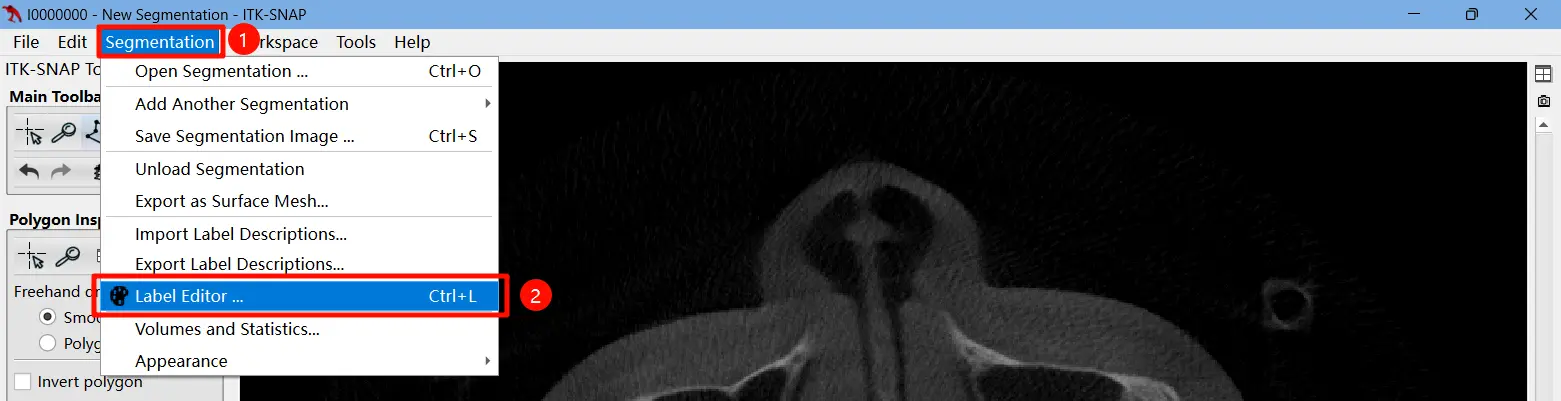
然后狂点 New,直到有了 32 个 Label 为止,其中名字(Description)并不重要。
切换 Label#
所以说可以切换 Label 了,在界面的左下角点击并且进行切换:
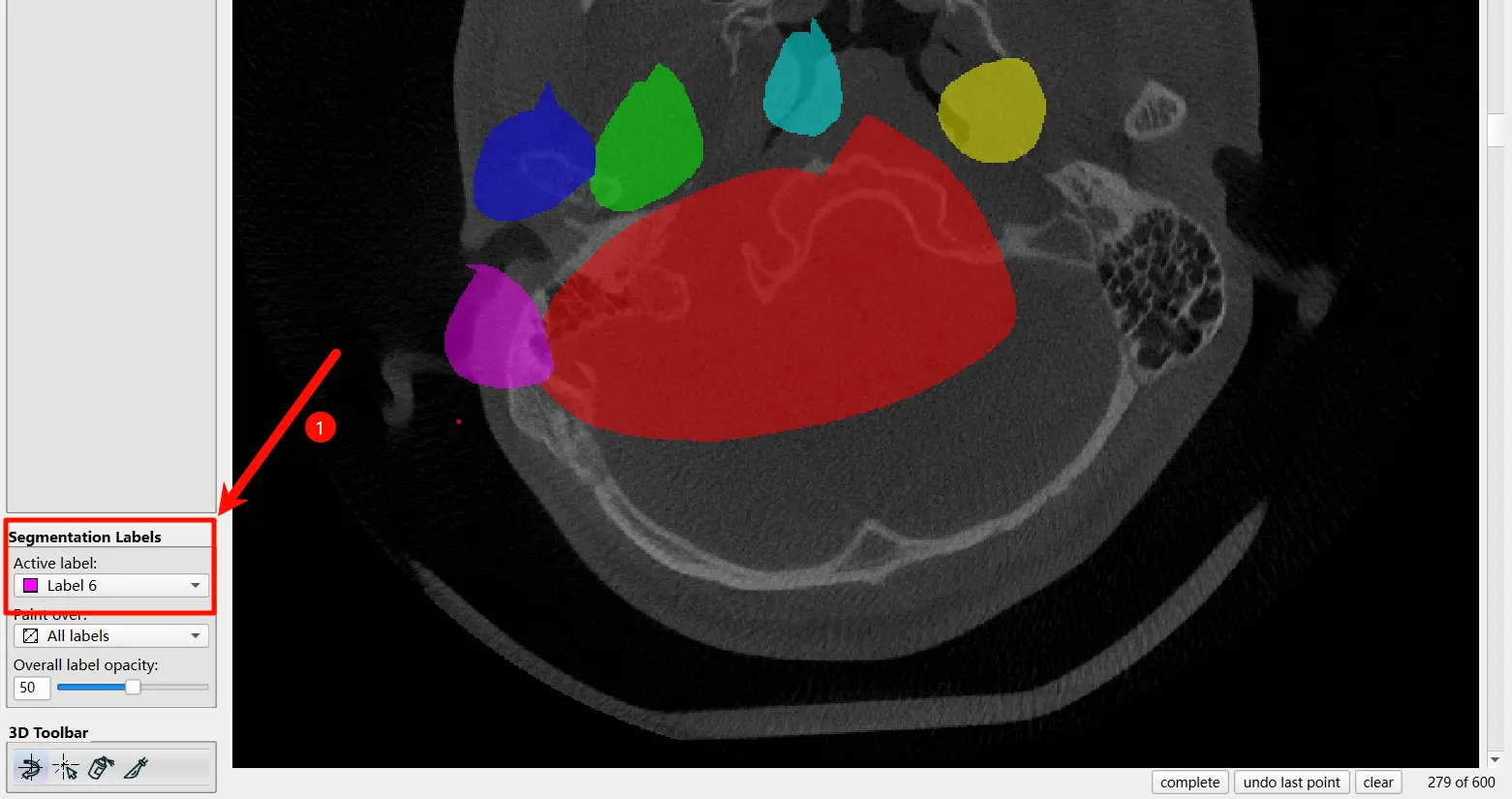
按照规定的顺序对牙齿进行标注,每次标注完一颗牙之后就可以切换一次。
保存与继续工作#
需要停下来或者结束了标注,按下 ctrl+s 保存,File Format 选择 NiFTI,Filename 写为你这个文件的编号,这很重要,别弄混了。
选择 Browse,找个地方保存。
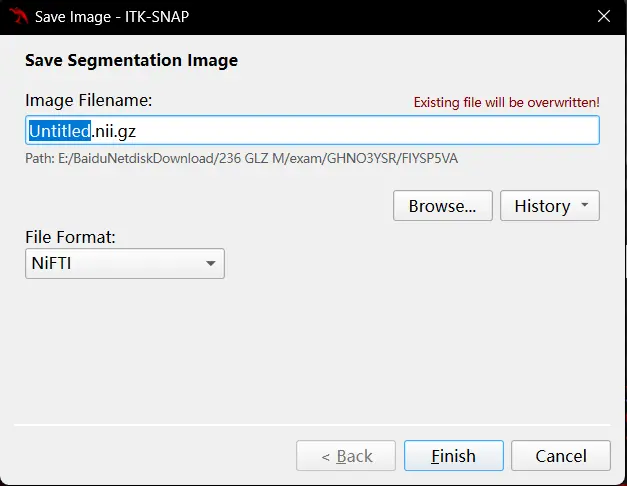
需要继续你的工作时,打开 Image,按下 ctrl+o:
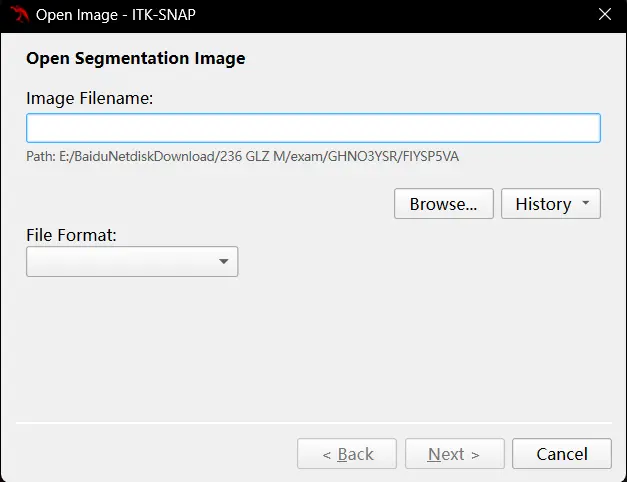
选择 Browse 并找到你的文件,Next,可能会有 warning 报错,不用管,看看之前的内容是否正常显示,然后继续你的工作。以上的方法可以帮助你保存和加载你的标注信息。
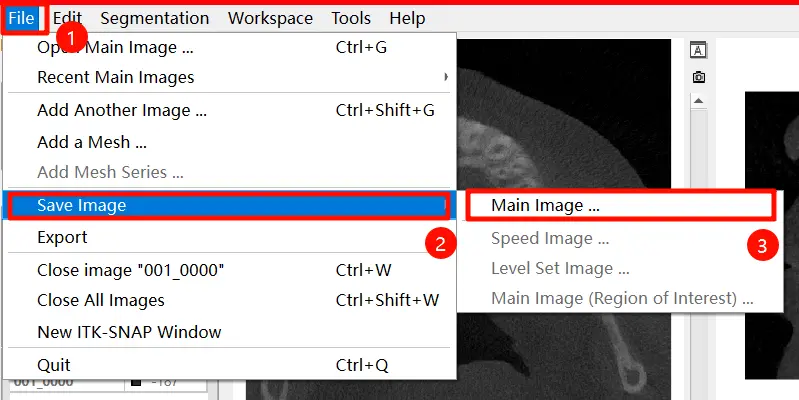
而你的本身的文件,也可以导出成 .nii.gz 文件,选择 File - Save Image - Main Image,选择 NIFTI 格式,选择 Browse 并找到你的文件,选择 Finished 即可。
数据处理#
这样,你已经有了自己的数据了,其中我们认为你把 image 和 label 放到了两个不同的文件夹中,你或许可以先 clip 一下数据,把数据中大量的空白都删掉,同时,需要注意的是,你的数据需要是统一分辨率的。
以下是一个示例代码,可供参考:
import glob
import json
import os
import pickle
from typing import List, Tuple
import h5py
import numpy as np
import SimpleITK as sitk
from tqdm import tqdm
def process_single_image(
image_path: str,
image_output_dir: str,
crop_range: Tuple[int, int, int, int, int, int],
is_label: bool = False,
):
image_itk = sitk.ReadImage(image_path)
image = sitk.GetArrayFromImage(image_itk)
if image.shape != (600, 767, 768):
print(f"Image {image_path} has shape {image.shape}, skipping")
return
z_min, z_max, y_min, y_max, x_min, x_max = crop_range
image_cropped = image[z_min:z_max, y_min:y_max, x_min:x_max]
if is_label:
image_cropped = image_cropped.astype(np.uint8)
base_name = os.path.basename(image_path).replace(".nii.gz", "")
image_nii_path = os.path.join(image_output_dir, f"{base_name}.nii.gz")
image_itk = sitk.GetImageFromArray(image_cropped)
sitk.WriteImage(image_itk, image_nii_path)
print(f"Saved {image_nii_path} with cropped image")
def preprocess_nii_to_nii(
image_dir: str,
image_output_dir: str,
global_crop_range: Tuple[int, int, int, int, int, int],
):
image_paths = sorted(glob.glob(os.path.join(image_dir, "*.nii.gz")))
print(f"Global crop range: {global_crop_range}")
for image_path in tqdm(image_paths, desc="Processing images"):
process_single_image(image_path, image_output_dir, global_crop_range)
def find_crop_range(label_dir: str):
label_paths = sorted(glob.glob(os.path.join(label_dir, "*.nii.gz")))
crop_ranges = []
for label_path in tqdm(label_paths, desc="Processing labels"):
label_itk = sitk.ReadImage(label_path)
label = sitk.GetArrayFromImage(label_itk)
non_zero = np.where(label != 0)
if label.shape != (600, 767, 768):
continue
z_min, z_max = np.min(non_zero[0]), np.max(non_zero[0])
y_min, y_max = np.min(non_zero[1]), np.max(non_zero[1])
x_min, x_max = np.min(non_zero[2]), np.max(non_zero[2])
crop_ranges.append((z_min, z_max, y_min, y_max, x_min, x_max))
crop_ranges = np.array(crop_ranges)
crop_range = (
np.min(crop_ranges[:, 0]),
np.max(crop_ranges[:, 1]),
np.min(crop_ranges[:, 2]),
np.max(crop_ranges[:, 3]),
np.min(crop_ranges[:, 4]),
np.max(crop_ranges[:, 5]),
)
buffer = 20
crop_range = (
crop_range[0] - buffer,
crop_range[1] + buffer,
crop_range[2] - buffer,
crop_range[3] + buffer,
crop_range[4] - buffer,
crop_range[5] + buffer,
)
return crop_range
if __name__ == "__main__":
label_directory = "label_new"
label_output_directory = "new_label"
image_directory = "image_new"
image_output_directory = "new_image"
os.makedirs(image_output_directory, exist_ok=True)
os.makedirs(label_output_directory, exist_ok=True)
crop_range = find_crop_range(label_directory)
print(f"Crop range: {crop_range}")
preprocess_nii_to_nii(image_directory, image_output_directory, crop_range)
preprocess_nii_to_nii(
label_directory, label_output_directory, crop_range, is_label=True
)
print("Preprocessing completed!")
不难发现且需要注意的是,本人使用的数据的原始尺寸为 ,假如你使用的是其他尺寸,请自行修改。你的全部的 image 应该是 xxx_0000.nii.gz 这样的形式,你的全部的 label 应该是 xxx.nii.gz 这样的形式。
训练模型#
训练模型可以直接使用 nnUNet,在这里给出配置的步骤,本人使用 autodl 租卡训练,请尽量使用 Ubuntu 而非 Windows。
首先直接配置环境:
pip install nnunetv2
git clone https://github.com/MIC-DKFZ/nnUNet.git
cd nnUNet
pip install -e .然后需要配置数据集,直接:
cd nnUNet
mkdir DATASET
cd DATASET
mkdir nnUNet_raw
mkdir nnUNet_preprocessed
mkdir nnUNet_trained_models
cd nnUNet_raw
mkdir Dataset001_Axi
cd Dataset001_Axi
mkdir imagesTr
mkdir imagesTs
mkdir labelsTr
vim dataset.json比如说一个牙齿分割的数据,配置如下:
{
"channel_names": {
"0": "CBCT"
},
"labels": {
"background": 0,
"Teeth01": 1,
"Teeth02": 2,
"Teeth03": 3,
"Teeth04": 4,
"Teeth05": 5,
"Teeth06": 6,
"Teeth07": 7,
"Teeth08": 8,
"Teeth09": 9,
"Teeth10": 10,
"Teeth11": 11,
"Teeth12": 12,
"Teeth13": 13,
"Teeth14": 14,
"Teeth15": 15,
"Teeth16": 16,
"Teeth17": 17,
"Teeth18": 18,
"Teeth19": 19,
"Teeth20": 20,
"Teeth21": 21,
"Teeth22": 22,
"Teeth23": 23,
"Teeth24": 24,
"Teeth25": 25,
"Teeth26": 26,
"Teeth27": 27,
"Teeth28": 28,
"Teeth29": 29,
"Teeth30": 30,
"Teeth31": 31,
"Teeth32": 32
},
"numTraining": 31,
"file_ending": ".nii.gz"
}此处 numTraining 为你的训练集的数量。
在 .bashrc 中添加:
export nnUNet_raw="/root/autodl-tmp/nnUNet/DATASET/nnUNet_raw"
export nnUNet_preprocessed="/root/autodl-tmp/nnUNet/DATASET/nnUNet_preprocessed"
export nnUNet_results="/root/autodl-tmp/nnUNet/DATASET/nnUNet_trained_models"按照你的实际情况修改路径。然后运行 source ~/.bashrc 生效。
之后就可以开始训练了,别忘了开一个 tmux,把程序挂到后台。
一个训练的脚本,可供参考:
#!/bin/bash
export dataset_id=$1
echo "processing $1"
nnUNetv2_plan_and_preprocess -d $dataset_id --verify_dataset_integrity
for fold in {0..4}
do
nnUNetv2_train $dataset_id 3d_lowres $fold
done运行:
bash train.sh 001训练结束之后,你可以在 nnUNet_trained_models 中找到你的模型。
之后可以直接测试,别忘了同样预处理你的测试程序,记录下来你第一个 crop 的范围,直接 crop,不要计算。
nnUNetv2_predict -i new_image_test/ -o out -d 001 -c 3d_fullres --save_probabilities -f all其中 -i 为你的测试集,-o 为你的输出路径。你需要等待很久,然后获得你的结果,祝你好运。
结语#
所以你水到了项目了吗?结果怎么样?你还开心吗?告诉我,如果你愿意。