
Paper Reading: Embodied AI 1
从一些 Embodied AI 相关工作中扫过。
RT-1#
使用 Image Encoder 以及 Text Encoder 并使用 FiLM 进行 Fusion 后用 Transformer 处理的模型
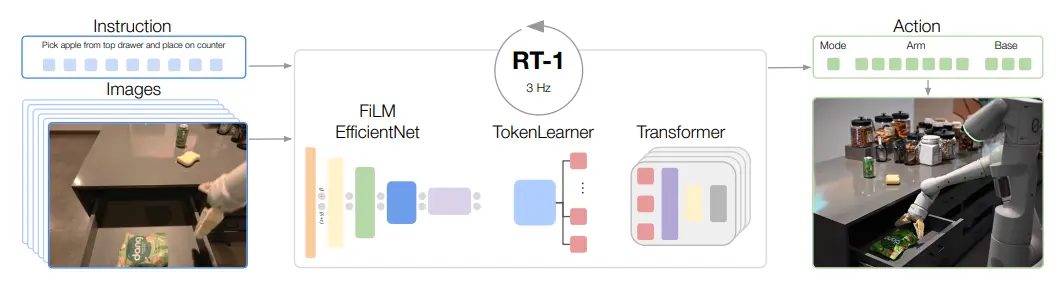
RT-1 由 Google 的具身团队推出,是比较传统的 VLA 模型。所谓传统 VLA,也就是并未使用 LLM Transformer 作为 Fusion 的模型这种现代的结构,而是完全 from scratch 搭建的 VLA 模型,毕竟对于 VLA 的定义,也就只是需要输入 Vision 和 Language 作为条件,输出 Action 作为结果。
Scaling up 的 deep learning 本质上是在学习多峰分布,并且在分布之外追求模型的外拓能力,从目前的视角上来看,使用 LLM pre-train 的 Transformer 作为 Fusion 的模型,是更优的。不过这篇论文上传于 22 年,彼时这种范式远未被探索,因此倒是合理。

RT-1 属于是彻底贯彻了 Scaling up 的理念,收集了 ~130K episode 的数据,以及超过 700 个不同的任务。事实上在实验的过程中,实际上貌似依然是在有限的任务上进行训练,而并没有一下子用上全部的数据,或者说用上了之后并没有 work,所谓的 unseen task 也仅限于交换物体(比如说见过捡起可乐瓶和推动水杯,未见则可以是捡起水杯)。不过无论如何,依然是初步 work 了的,可以做到交换级别的外拓。
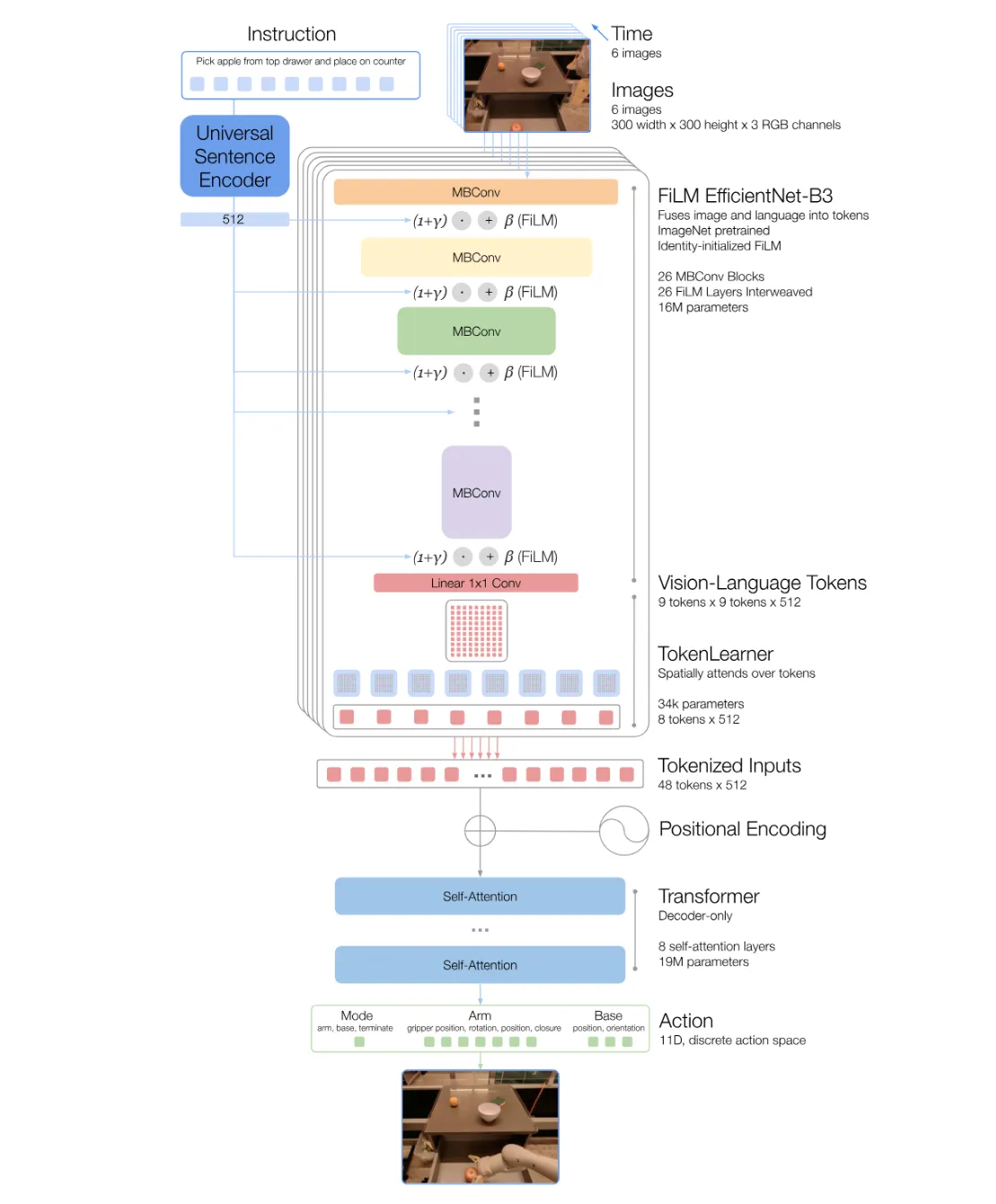
最后简单从结构上观察一下,如图所示,文本被 text encoder 编码之后,而 Image 取六个时间步的图片,输入到 efficient net 中。编码后的文本和图片的特征被 FiLM 调制,然后输入到 transformer 中。之后获得 Tokens 再过 TokenLearner,输入进一个 transformer 里面,获得最后的 Action 信息,格式是 End-effector Pose。本身使用 TokenLearner 而非直接端到端是出于效率的考量,相似的考量的另一个细节是保留 Image Token 的历史并且进行复用。
最后简单提及一下感想,RT-1 可以说是提出了一个 work 的 VLA 范式,并且做的一定程度上可以泛化。不过 RT-1 还是具有一些局限性,不能引入 VLM 来强化模型的泛化能力使得模型几乎永远无法真正泛化到未见物体,而且减少了 co-training 的纯粹拟合 action 数据,使得很难利用到 VLM 等更加广泛的数据,而只能使用 VLA 的昂贵数据。后续的问题在 RT-2 解决了不少。
RT-2#
使用 LLM 进行 Fusion 的现代 VLA 架构
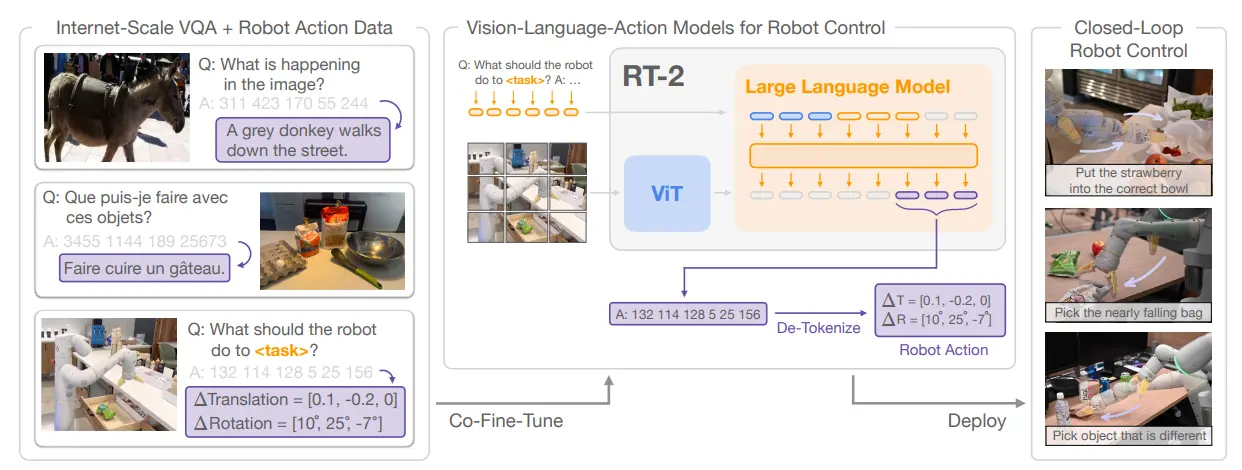
RT-2 是 Google 时隔一年之后的又一力作,从结构上来看就已经合理了不少了。因为 LLM 以及 VLM 的兴起,在过去的一年中出现了不少的新工作,包括了两个被 RT-2 采用的模型,也就是分别是 PaLI-X 以及 PaLM-E。
RT-2 的结构可以说奠定了之后的一种流派。总的来说,RT-2 完全遵循使用 Transformer 进行 Fusion 的思路,并且替换 256 个 Token,改为离散化的动作表征 Token,并且 Token 可以解码为 End-effector Pose。
模型的训练使用了 Web Data 进行 VLM 的预训练,并且在此之后,依然是进行了多任务的训练,效果也很不错,并且支持了 reasoning 环节。实验部分使用了 6K 的轨迹进行训练,体现了新物体、背景和环境上的泛化,并且可以进行符号理解。
RT-2 作为初步使用 VLM 来作为 VLA 模型预训练权重的模型,通过符号理解等能力,体现了 VLM 的能力迁移到 VLA 的潜力,虽然事实上的性能可能还是来自于后训练。这一架构后续被包括 OpenVLA 在内的诸多模型沿用效仿,成为了一段时间内的主流方法。然而使用离散化 Token 的方法也存在其局限性,因为使用离散化,因此模型的精度有限,这一点在使用绝对位姿控制的模型上尤其显著,伴随模型的 Action Space 扩大,模型每一个 Step 的精度会进一步下降,因此难以进行一些精细操作,而带来更多的离散化数量在本质上也依然是治标不治本的。
参考资料:
VIMA#
使用 Object Token 对物品信息(Image, Text and Location)进行编码
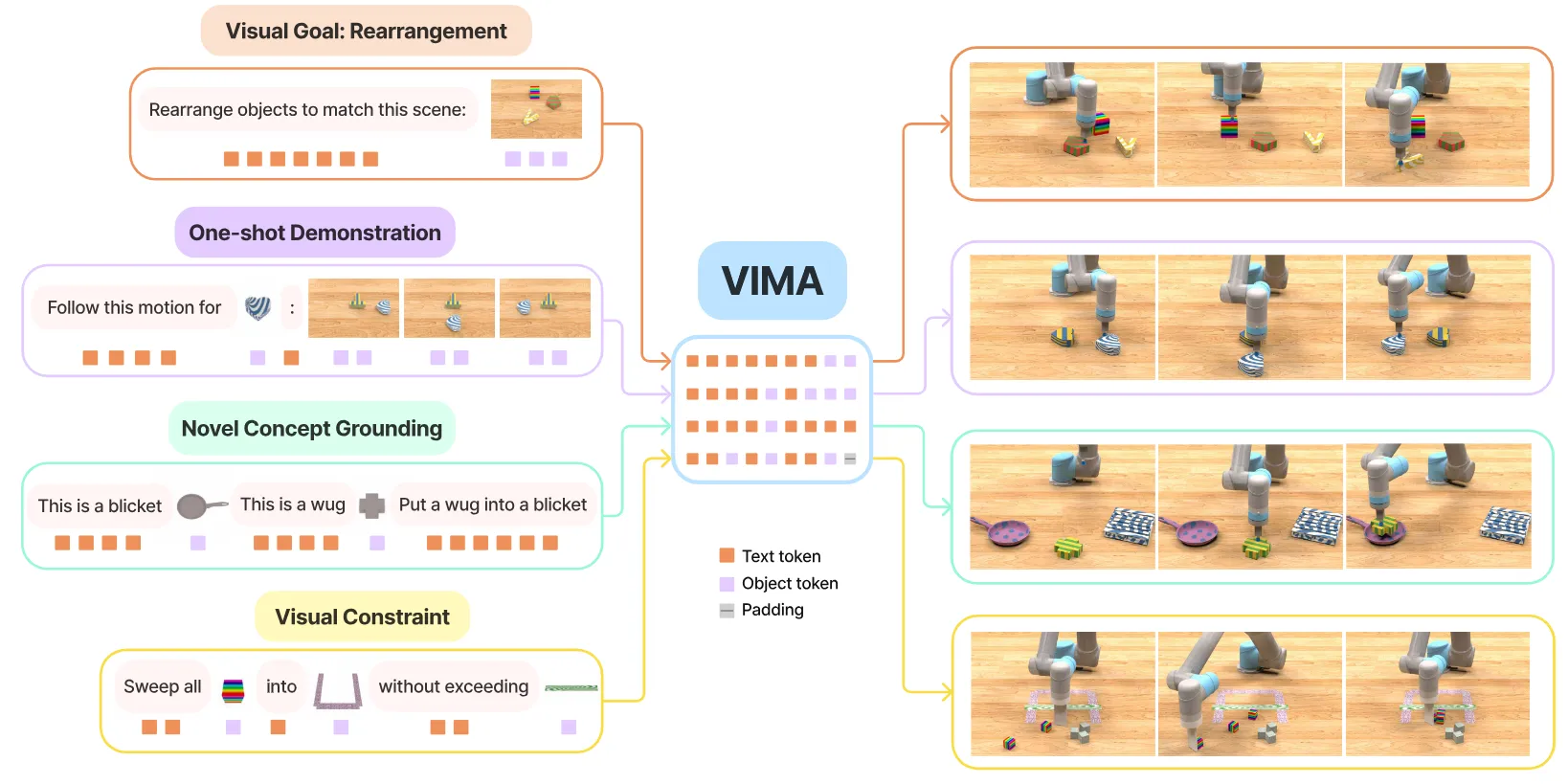
VIMA 是比较早期的工作,由 Feifei Li 的团队推出,也是很不错的实现,本身里面一些有意思的设置。
VIMA 本质上并没有完全使用 LLM 或者 VLM,而是使用了 T5 的 Encoder 来进行 Token 之间的 Fusion。从输入开始说起,VIMA 一共包括 Object Token, Scene Token 以及 Text Token 三种不同的类型。其中 Scene Token 或者说 Image Token,就是非常传统的图片输入,Text Token 同理,而 Object Token 则是将需要关联的物体在使用 Mask R-CNN 之后,对于 Crop image 使用 ViT 编码,bounding box 使用对应的 encoder 编码,可以说同时包含了物体和位置信息。
VIMA 还支持历史信息,可以进行长任务。虽然说 RT-2 也可以上下文理解,但是 VIMA 直接使用原本的信息,肯定表征更多一些,也就是所谓的 Visual centric 的表征方案。一个 insight 是使用 object token,常规的多模态输入都是先图像后文本,object token 将两个交叉在一起,interleave 的方案可以提供更加直接的 format,并且可能带来更好的效果,也更加将图像融入了文本的体系里面。
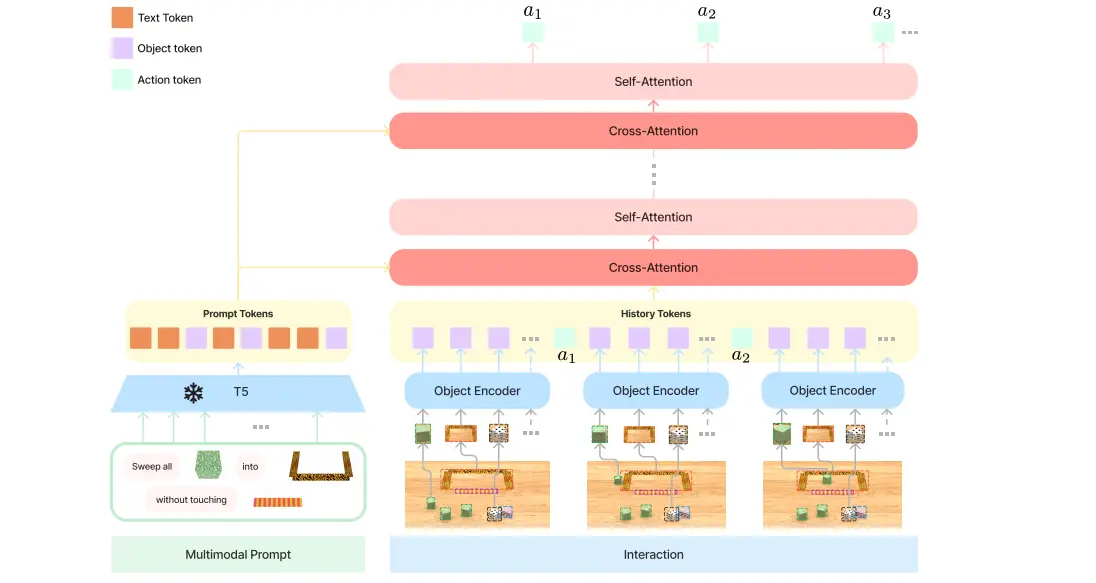
VIMA 的问题在于使用 RCNN 还是太过于草率了,但是即使使用 Grounding DINO 或者更好的方案,似乎也并不会有本质的改变。在使用 Object token 的方案的情况下,相较于如今 VLM 直接力大砖飞的方式,在结果上来看并没有过多的性能差距,而 VLM 带来了更多的可拓展性以及泛化能力。
留给 VIMA 的问题是显然的,是否有更加优雅的方式来进行 object token 的生成或许会是一个问题,以及如何进行泛化的大规模学习。而同时,目前随着通用能力的提升,模型能否在泛化以及更加复杂的 Skill 上处于一个良好的 trade off,也是一个关键问题,不过 VIMA 在 Input 上有了不少的探索,但是输出似乎还是直接使用 Transfomer 来整合 History 和 Prompt,直接进行 from scratch 的训练,泛化能力也是有限的。
参考资料:
SayCan#
使用 RL Value Function 纠正 LLM 输出的可行性
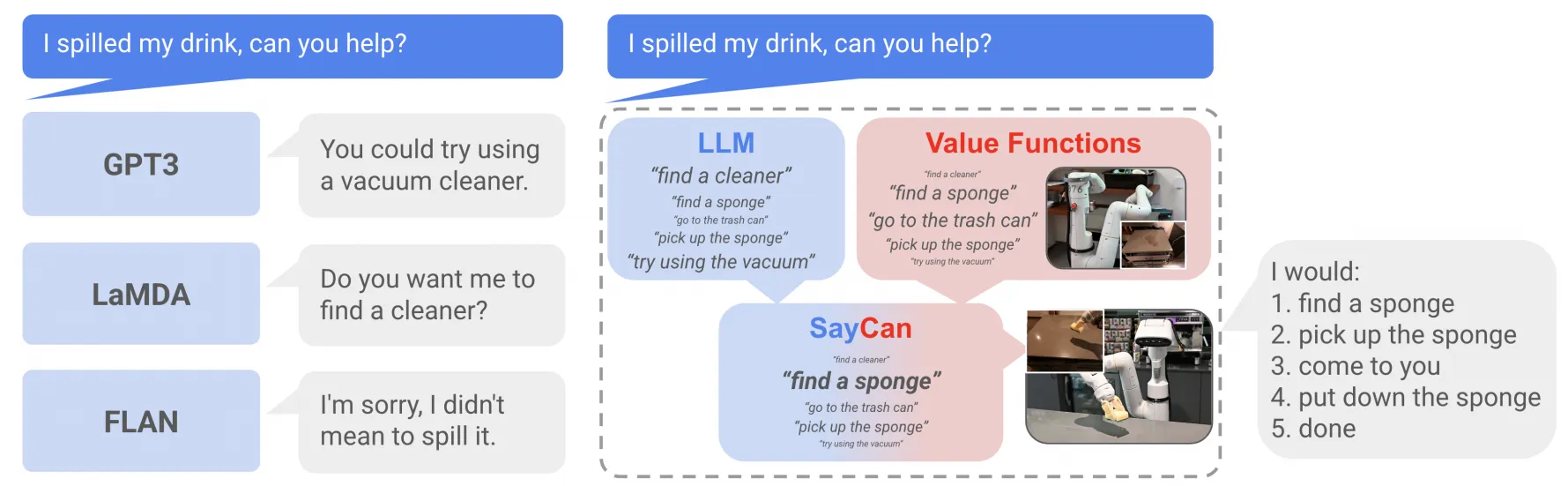
SayCan 可以说是在做这种规划任务里面比较早的了,所谓规划任务,或者说 System2,其实就是通过任务拆解以及分析,来为下游真正的 low level 的模型提供一个更清晰的指引,进而扩大整个体系的泛化能力,显而易见的就是可以外拓到一些 reasoning 任务来。
SayCan 本质解决的问题可以理解为是 LLM 或者 VLM 的幻觉问题以及 LLM 缺乏对于机器人相关的先验知识的问题,如图中所示,模型可能会指示下游的模型去进行一些不切实际的任务,而这些任务实际上是不可执行的,SayCan 为了就是增加一个权重,纠正这种内容,把需求和可行性结合起来。
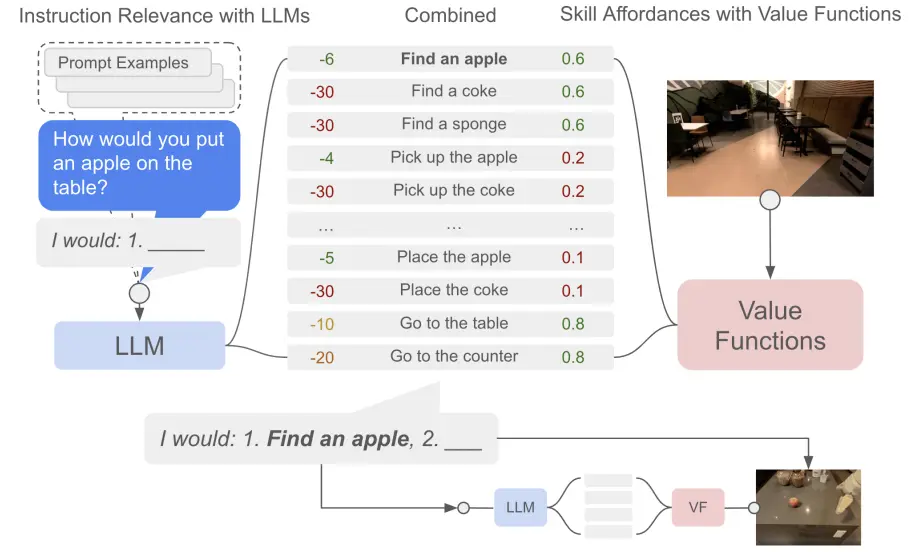
大概的流程就是,对模型输出本身的任务目标,而模型本身存在一个动作列表,里面是定义好的 Skill(可能是提前训练好的 low level policy),那么 LLM 就可以从这个动作空间里面给出不同的推荐。如上所述,一个问题在于,由于 LLM 不清楚当前的情况,所以说可能无法很好地给出能够执行的结果,这个时候可以使用另一个模型,或者说是一个价值函数,来去评判在当前情况下这些动作的价值。那么这个价值函数是使用了环境信息的,并且在 RL 上进行了学习,最后价值和大模型的推荐结合在一起,就生成了一个布置合理,而且可以完成的动作。
这里面的 insight 其实不多,或者说显而易见,想要让 LLM 去参与到动作的生成,固然其本来就具有一定的规划能力,但是这种能力在没有现场情况的了解下是施展不开的,于是可以简单地使用价值函数来作为一种当前情况的引入,本身需要训练的东西也很少,可以说是十分的轻量化。不过伴随着模型的能力增强,这方面的规划不再是主要问题,而是在于更加 open vocabulary 的规划,以及复杂任务的理解能力,甚至说一些 grounding 能力,而这些能力甚至在 VLM 中都没有很强,在 VLA 中更是难以实现的难题。
参考资料:
Language Models as Zero-Shot Planners#
使用 Pre-Trained LLM 将任务拆解并映射到 Action Set 里面的 Actions
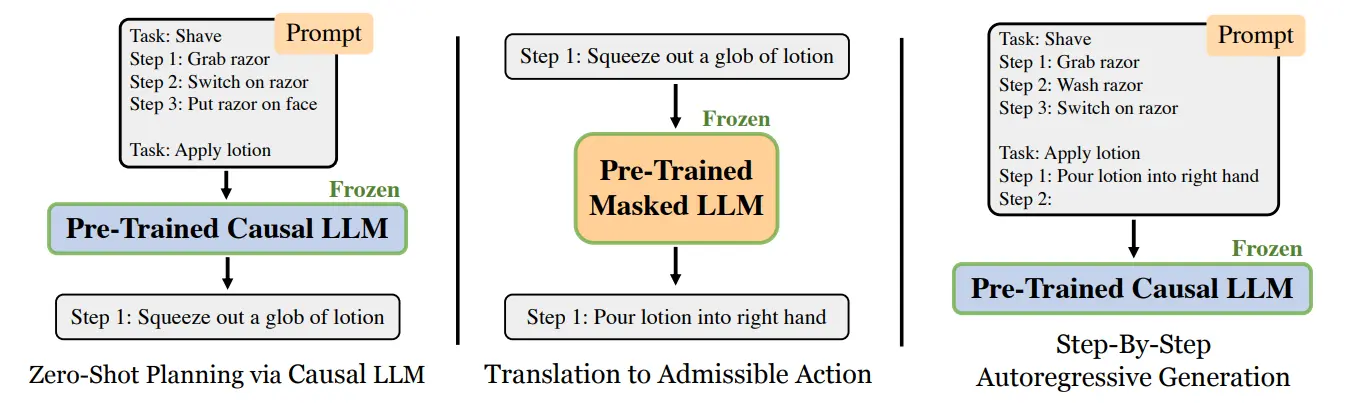
这篇文章也是在 planning 领域的内容,某种程度上也可以说是 low hanging fruit,甚至说不需要任何的训练,就是纯粹的 prompt。在这篇文章中的设置下,系统会设置一个 Action Set,这一点与诸如 SayCan 等模型一致,假设存在需要的 low level policy。
对于任务,这篇文章的方法是先让一个模型给出一些任务拆解,然后这些计划通过另一个模型翻译成在 action set 里面的最接近的内容,最后交给下游的 policy 来执行。从本质上,Zero-shot Planner 甚至感觉是 SayCan 的简化版,不检测可行性,相信 LLM 的能力,而是只确保任务在 action set 里面,而最后理论可以达成的效果与 SayCan 一致。
参考资料:
- Language Models as Zero-Shot Planners - https://zhuanlan.zhihu.com/p/656399047
PaLM-E#
用大量的数据训练一个 high level 的 planning 的 VLM

彼时谷歌的 PaLM 模型刚刚推出了一年,而 PaLM-E 则在其基础之上,将 PaLM 添加一个 ViT,组成 VLM 模型,在大量的常规 Language 任务, VQA 数据以及包括机器人场景的数据上进行训练,以得到一个通用的 VLM 模型,同时这个模型在机器人场景中也被设置为一个 specialist 的角色,可以在 Planning 等任务上更加擅长。
因为 PaLM-E 是在届时最为先进的 VLM 模型之一,同时在具身任务上进行了训练,所以说看上去确实十分具有吸引力,也可以超过当时同样 Google 提出的 SayCan。不过从当今的视角来看,PaLM-E 却不太能带来额外的 insight。在 2023 年,VLA 的概念依然没有完全成型,端到端训练动作模型的方案也依然并不是主流,从 CVPR 2022 的 Best Paper 给自动驾驶的系统性论文就可以看出,当时包括 PaLM-E 在内的 VLM 作为 System 2,并且在此基础上使用 low-level policy 来提供诸多能力,似乎才是合理。当今使用相似的结构的包括 RoboBrain 系列等,依然是 follow 的 System2 的故事。
参考资料:
ViLA#
Prompt-based 的 high level planning 解决方案,记录以往的解决的 Tasks
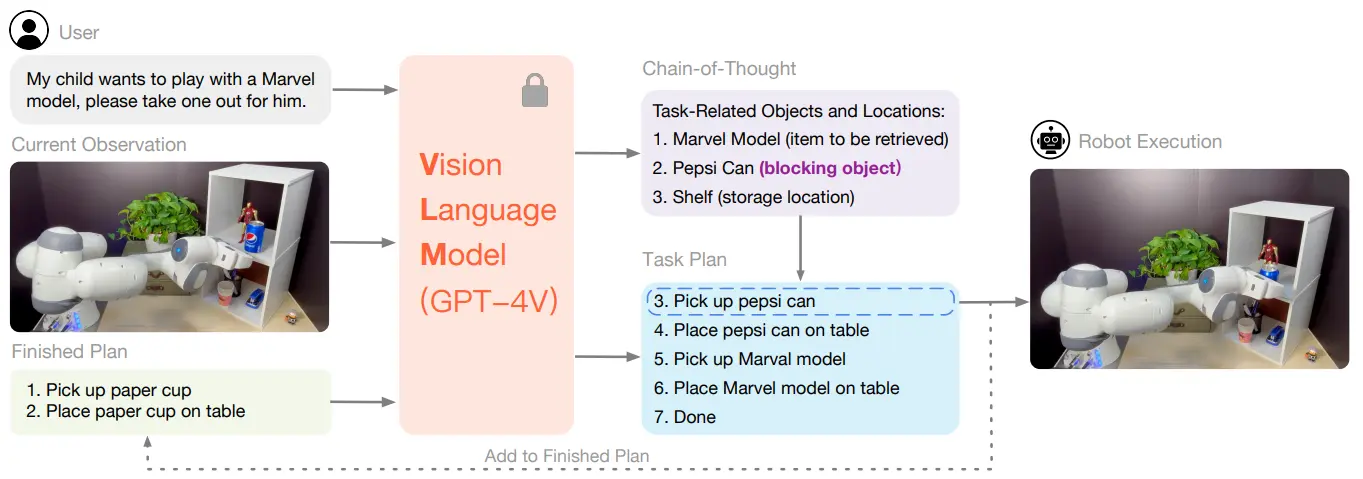
ViLA 提出了一个相当直接的 Idea,但是却在 Prompt 类型的工作中相当本质。笔者并没有了解 Agent 相关工作,使用 LLM 或者 VLM,并且使用闭环让 LLM 或者 VLM 持续获得 in-context 信息,并且可以对于反馈进行新的规划,应当并非新的 Idea,但是在 Manipulation 中确实是首次。
ViLA 的思路非常简单,如图中所示,将任务以及 Obs 直接输入给 VLM,让 VLM 输出 CoT 以及 Task Planning,然后将 Task Planning 作为一个 TODO List 进行维护,将 List 的第一项交给 low-level policy 来执行,并且将执行的结果(新的 Obs)以及已经完成的任务列表给 VLM,让 VLM 进行新的 Task Planning。
伴随着 VLM 的性能提升,如何 leverage VLM 的能力到 Long horizon 的规划中,并且利用 VLM 的优势,这是一个十分值得探索的问题,或者换句话来说,有什么时期是 VLM 可以做到,但是 low-level policy 难以做到的,这就是 System 2 的体系作为 System 1 的补充的存在必要性。ViLA 敏锐的把握住了其中的两个关键要点,一个是 Reasoning,在框架中体现为 CoT 的输出,可以将需要推理的任务拆解为更加直接的任务表示;另一个则是 Long horizon 的规划,在框架中体现为 Task Planning 的输出,同时还顺便支持了闭环的纠错。
ViLA 尽管看上去十分草率,甚至说本质只是几句简单的 Prompt,但是却十分具有启发性,敏锐地把握了 VLM 的优势,整体故事十分完整。
CoPa#
使用 SoM 以及 GraspNet 获得 Grasp Proposal,并且使用点云信息聚类结果做 Motion Planning
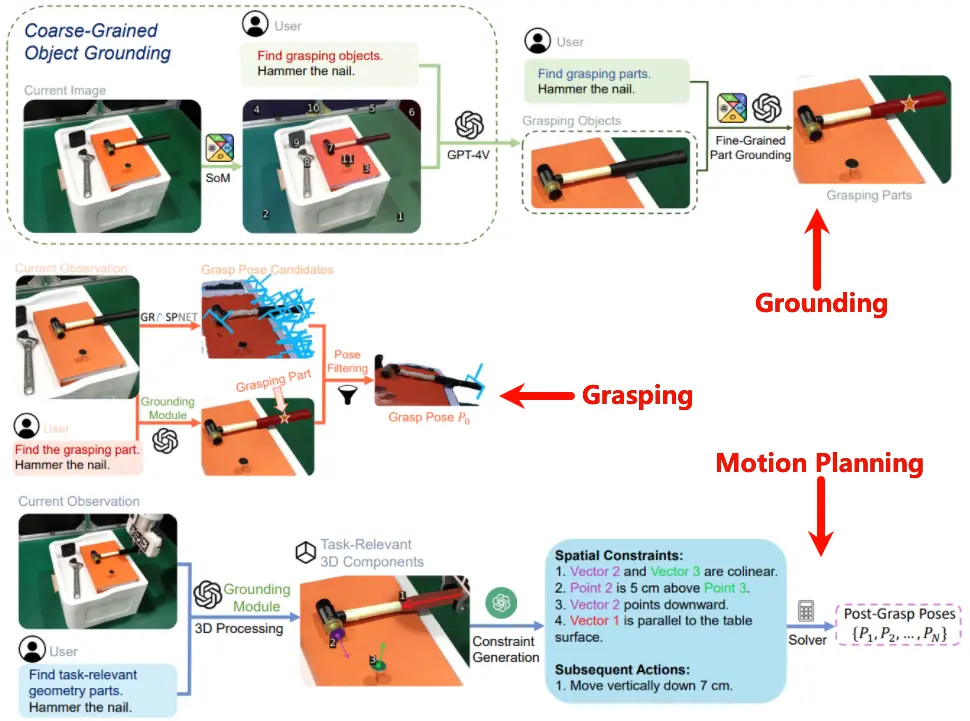
CoPa 是在 ViLA 之后进行的后续探索,虽然说本身还是以 VLM 驱动,但是却并非 System 2 的思路(即通过搭建 workflow 来为 low-level policy 稳定提供任务规划),而是引入了更多的 foundation model,并且直接用整体的体系直接输出 Action,并且可以直接完成任务。
整体来说,CoPa 如图所示,由三个组件组成,分别是 Grounding, Grasp Proposal 以及 Motion Planning。Grounding 以及 Grasp Proposal 包括了 Grasp 的生成以及筛选,生成的思路十分简单,可以直接使用 GraspNet 这种 foundation model,通过 depth 和 rgb 输入来生成 Grasp Pose;而对于筛选来说,则是使用多组 SoM 来选择需要抓取的物体的部分。
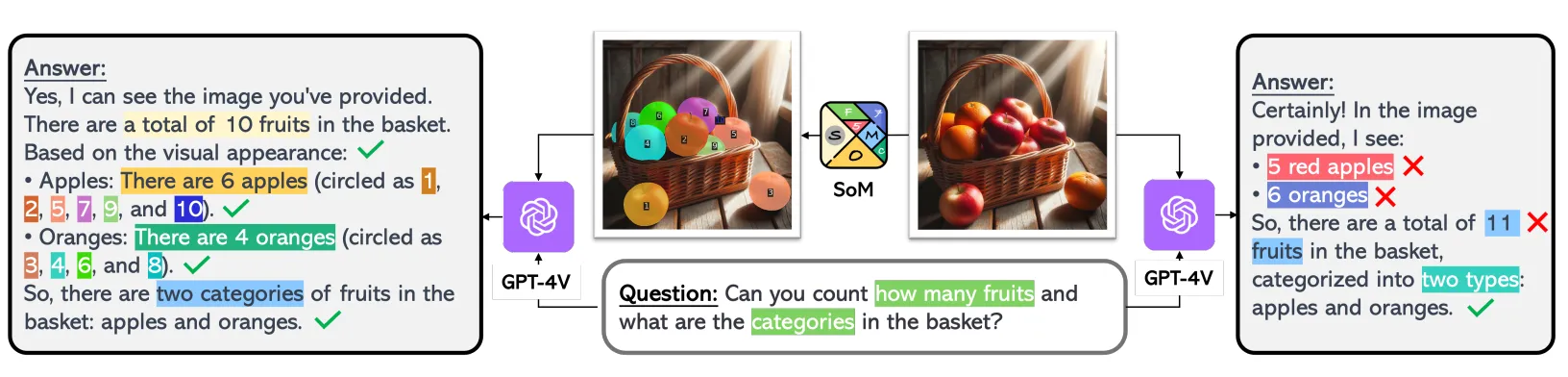
SoM 即使用 SAM 进行分割之后使用 GPT 来选择对应的 Mask,来达到物体分割的效果。CoPa 在此基础上使用了多轮的 SoM,可以先选择粗略的物体,然后细致地选择物体的某个部分,如 桌面->锤子->锤柄。
接下来是一个路径规划,这里先识别了各种物体的位姿,然后将这些内容画在图上,估计这种选择是因为不信任大模型的数学能力,反而是图像比较直观,容易理解。之后通过这种细粒度的指示,大模型就可以给出更加合理的建议,类似于之前是将锤子放在钉子上,现在可以是将锤子和钉子对齐,而且根据识别的位姿,或许可以精确到距离。然后交给执行器。
CoPa 以及之后提及的 MOKA 是使用 foundation model 来完成任务的典型工作,到之后学界开始发现使用端到端的 VLA 也可以达到相似的效果之后,这些范式就逐渐淡出了人们的视野。然而事实上,在当下,对于调试一个 Fancy 的 Demo 来说,得益于 foundation model 的稳定性以及显式拼接的可解释性,使用这种 modular framework 进行调参并且完成任务依然是十分高效的。
PointLLM#
点云版本的 VLM
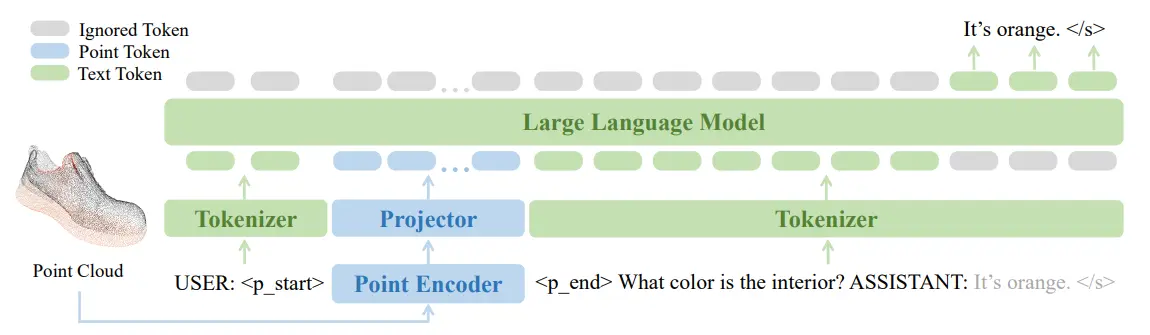
PointLLM 可以是说十分标志的工作了,属于是非常符合直接的工作,本身也得到了很高的认可度。PointLLM 本身的目的就是建立像是 VLM 对图片理解能力一样的对点云的理解能力。因此不难理解,PointLLM 的实现方法也就像是正常的 VLM 一样,但是只不过是将图像的模态输入换成了点云,然后使用 point encoder。总体来说改变并不算多。可以说这篇工作的诞生是符合直觉的,点云模态也可以对齐到语言的空间上进行建模并理解。
EmbodiedGPT#
使用 Q-Former 范式的多模态 VLA,直接输出 low level action
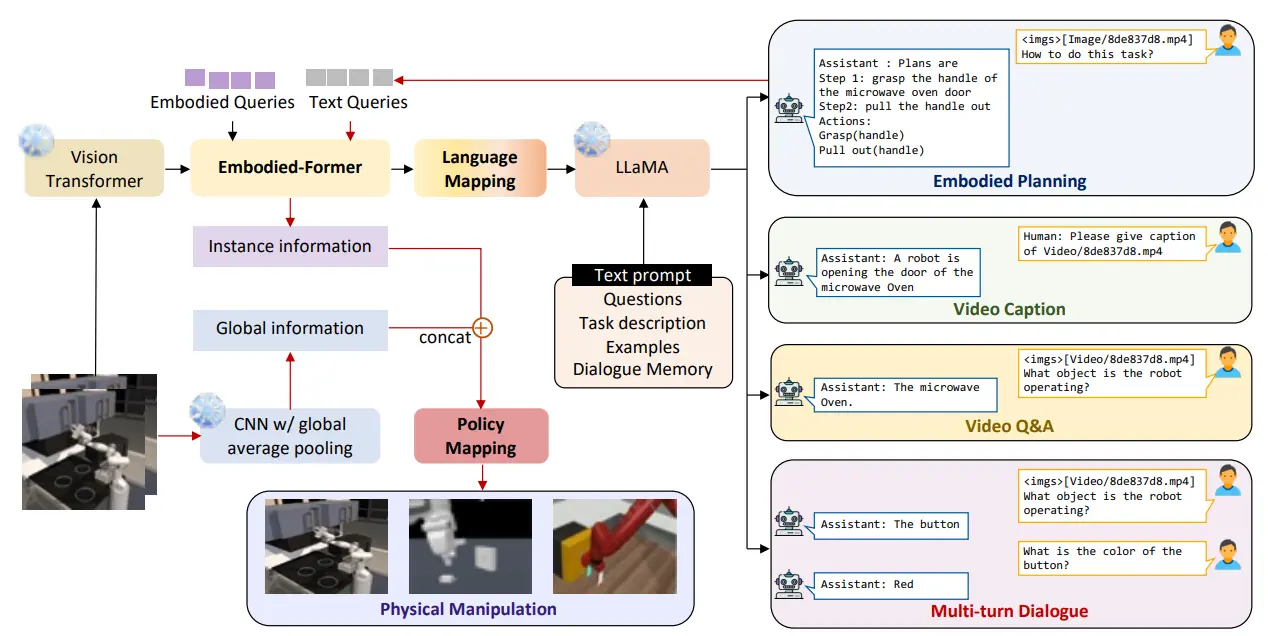
EmbodiedGPT 是一篇有些复杂的工作。简单来说,EmbodiedGPT 用 ViT 进行 encode 之后,和 embodied token 在 Q-former 中进行融合,然后和 Text 信息一起输入给 LLaMA3 的 decoder,输出 Planning 的信息。纯 Text 的 Planning 信息输出之后,可以再次 tokenize 之后和 ViT token 在 Q-former 中融合,之后输出一个 instance information。同时一个 CNN 处理图像输出一个 global information,两个 information 进行 concat 之后作为 low-level policy 的输入。
本质上,EmbodiedGPT 依然是受到时代局限性的影响,受到 BLIP 2 的启发引入 Q-former,但是并未采用后续 VLA 通用的 VLM Fusion 方案。然而 EmbodiedGPT 依然是具有启发性的,Planning 如何在 VLA 系统中被显式引入,通过重复的输入来重复利用一些组件,并且将显式的 Planning 引入监督中,并且让后续的流程中可以作为输入,依然是值得借鉴的。
RT-Trajectory#
使用 Trajectory 替代 Instruction 进行任务表征的 VLA 模型,Trajectory 也可以通过其他方法来生成
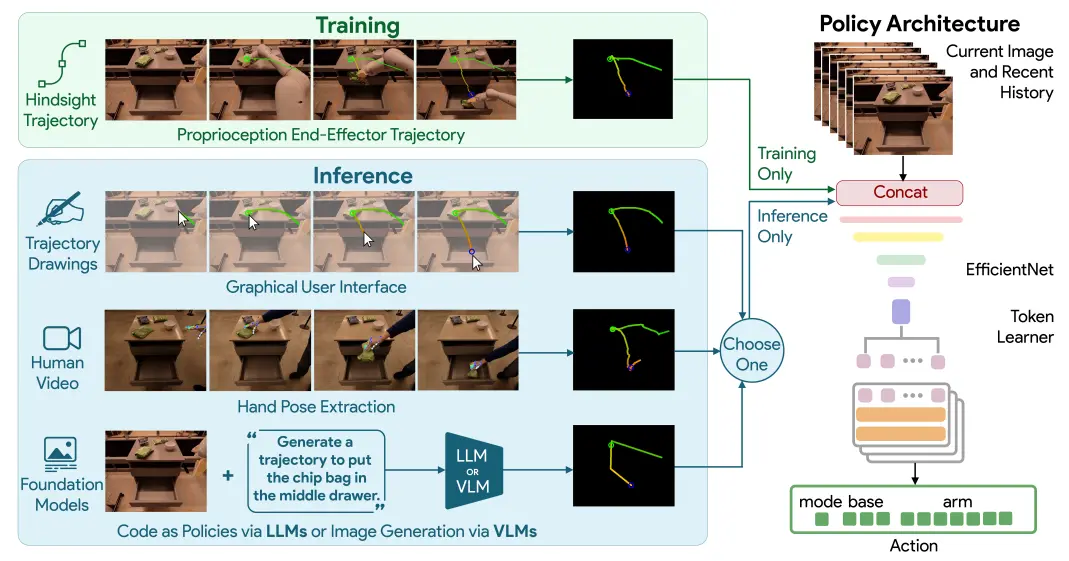
从图中不难看出,RT-Trajectory 本质上是在 RT-1 的基础上进行了调整的模型,本身依然是使用 RT-1 的框架进行动作输出的 low-level policy。在此之前的模型,主要依然以 VLA 模型以及 VA 模型为主,然而 RT-Trajectory 则打破了这一范式,尝试使用 Trajectory 而非 Language 作为 Condition。
模型的输入包括之前和当前帧的 Obs 以及一个 trajectory 的轨迹,轨迹使用图片进行表征,通过 R 和 G 两个通道表征了时间顺序以及高度信息,还可以加入交互标记,最后和图像一起输入。因为从文字 prompt 改为了图像(轨迹),所以本质上具有更高的细粒度,然而也会带来别的问题。首先是轨迹的来源,尽管论文中给出了多种可以产生轨迹的方法,但是具有高保真度的轨迹生成依然是一个问题,同时,对于轨迹来说,单一的轨迹即使包含深度信息,在对应机械臂的末端执行器在三维空间中的运动时依然具有歧义,在对于一些需要机械臂进行旋转的操作的时候,二维轨迹的表征能力依然不足。
不过总的来说,RT-Trajectory 提供了一个新的视角,即,作为 low-level policy,并不一定需要以语言作为中间表征,恰恰相反的是,可以通过更加细粒度的信息,为模型带来更多的指引。
Im2Flow2Act#
Object Centric 的 Flow Generation,并且使用 Flow 来进一步生成 low level policy
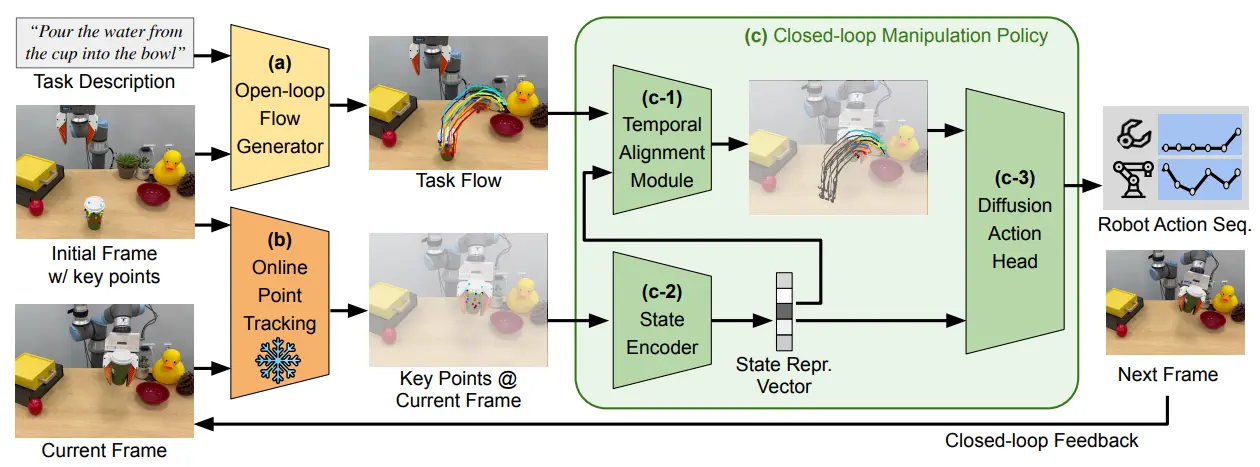
Im2Flow2Act 的核心思想在于,首先根据任务生成对象流,也就是以操作物体为中心的光流一样的轨迹簇,对象流具有很高的细粒度,并且甚至可以包括物体内部的指引,比如说折叠毛巾,之后对象流通过模仿学习来获得动作规划。
Im2Flow2Act 使用了 Diffusion 里面的动作生成(视频生成)作为流生成的方法。首先先框出来一个物体,在物体上面可以采样若干的关键点,这些点就组成了一个 的图片,但是这个图片不是正常的图片,和RT-Trajectory 里面的轨迹图片一样,是通过像素表征了别的信息,这里面就是图像系下的坐标和可见度。那么根据条件输入,就可以生成视频了,而这个视频本质上表征的是这个物体在不同时刻的空间信息。

流生成了之后,基本上是直接使用模仿学习进行的运动规划,用了 Transformer 去编码当前帧的状态,再用 Transformer 去和任务流做融合,来生成剩余的流,最后交给 Diffusion Policy 去生成动作。
Im2Flow2Act 的创新性在于使用生成式的方法生成高细粒度的物体流,这种过程在表征能力上显然是优于 RT-Trajectory 的,同时第二阶段的时候使用当前的状态和任务流做融合,有一种 nav 中全局规划和局部规划的意味,也可以说是十分 make sense 的 motivation,而并非一拍脑门的想法。总的来说是一篇 based 轨迹的动作规划的很不错的工作,而且相较于 RT-Trajectory 更有细粒度。
LLARVA#
OpenVLA 范式下增加了 2-D Visual Trace 作为额外的任务
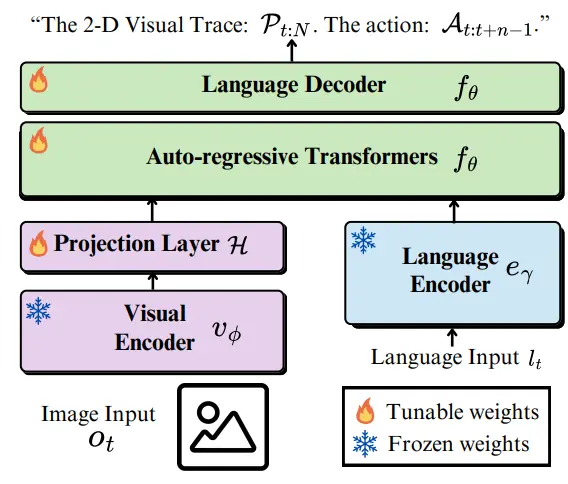
LLARVA 相较于之前的工作,可以说也是一个比较符合直觉的工作,使用指令调优(IT)的方法进行训练,处理了 OXE 这个数据集,让模型学习 2D Visual Trace。从 Pipeline 也不难看出,LLARVA 是一个比较经典的架构,基本上也是 LLAVA 的框架,训练一个 projection layer 以及后面的 Transformer 做对齐以及模态的融合。

本身 LLARVA 的思路还是十分清晰的,使用 co-training 的方式来为模型带来更多的约束,以学到更多的知识,进而再类似于 OpenVLA 的范式下得到更好的动作能力。从本质上来说,作为使用 next token prediction 来输出 action 的模型,先输出轨迹再输出动作,也是一种 CoT 的体现。
ATM#
使用点跟踪技术生成数据集,通过轨迹条件策略预测动作,创新在于使用轨迹作为表征和条件
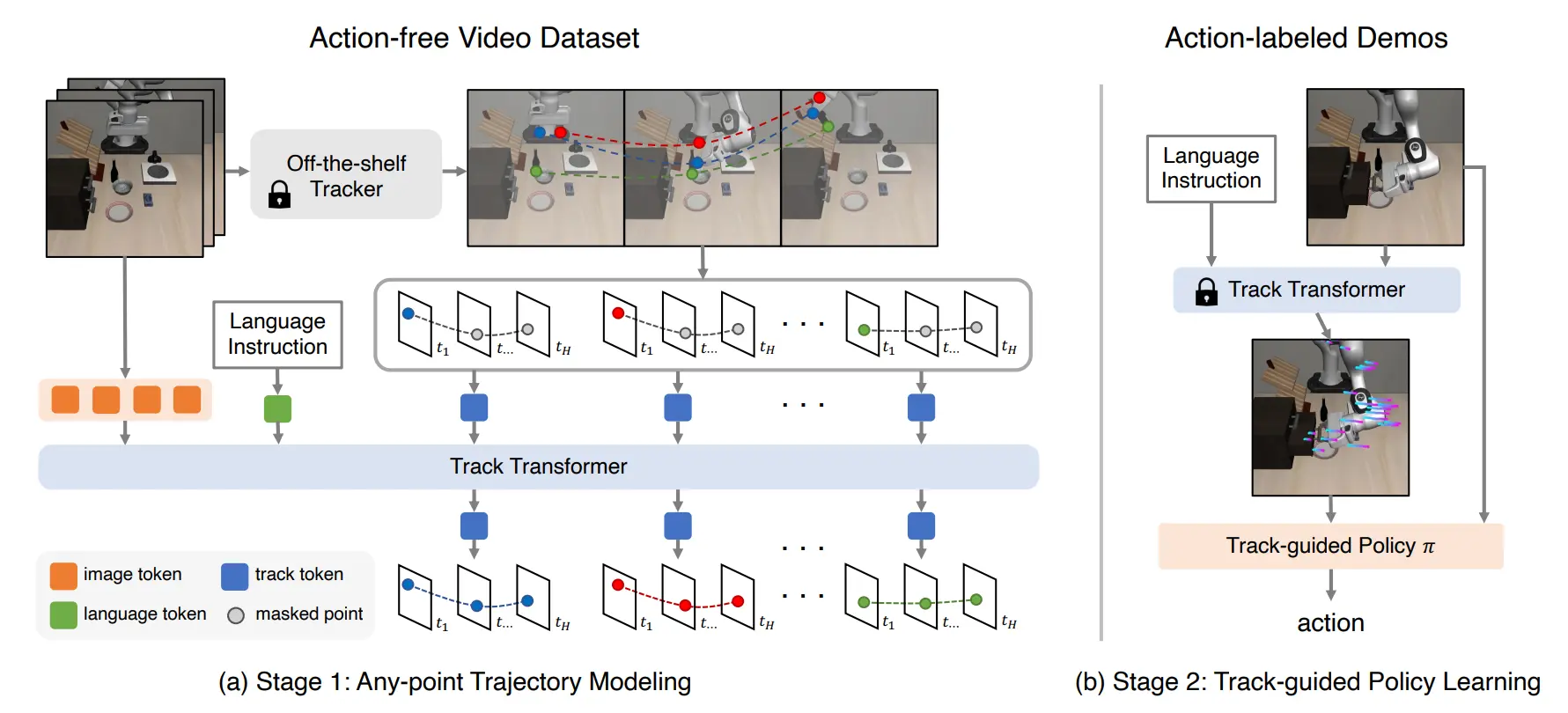
ATM 可以说是在提出光流式的轨迹,并且作为指引进一步生成 action 的框架中相对较早的,本身的做法也是比较清晰,也是得到了 RSS 的满分。
本身的话,ATM 没有采取像是 Im2Flow2Act 一样的物体轨迹的预测,这也比较好理解,全局的点一方面或许可以具有全局的动作视野,而另一方面,全局的点也会比较好获取一些。本身的方法就是使用点跟踪的技术对图像里的点进行跟踪来生成数据集,然后让一个 track transformer 来预测点的轨迹。接下来就是一个正常的 Trajectory Conditional Policy,本身的实现,论文里也说了,也是使用 cls token 去做全局表征(ViT like),然后用了 track prediction 去作为额外的 condition 进行 fusion。
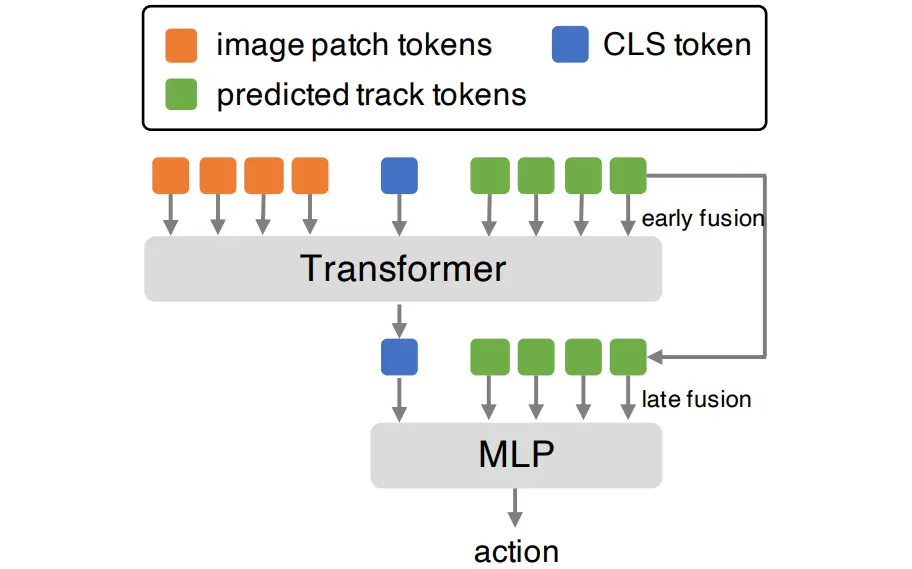
从创新点来说,这篇算是开山之作之一了,引入了 Track 作为中间的表征以及条件,并且可以通过数据集的一些生成的技术进行标准的损失计算,因此在监督下训练提升的很好也是意料之中了。一方面增加了更具细粒度的输入,一方面这种细粒度也体现在任务的难度上(hard task),二者共同导致模型的简单易用。
Track2Act#
与 ATM 类似,使用轨迹预测作为动作生成条件,加入残差策略提高准确度
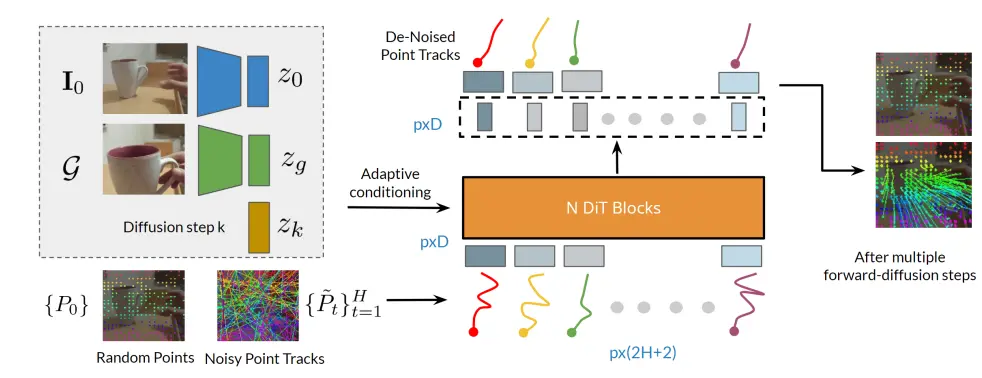
Track2Act 和 ATM 之间其实并未具有较大的差异,二者的方法实际上是近似的,也就是先预测轨迹,之后将轨迹作为动作生成的条件。模型首先还是进行点的预测,在这里使用的是 DiT,随机 sample 一些点和轨迹,然后就可以进行生成了,将当前状态、目标以及迭代次数都作为 adaptive conditioning 输入。
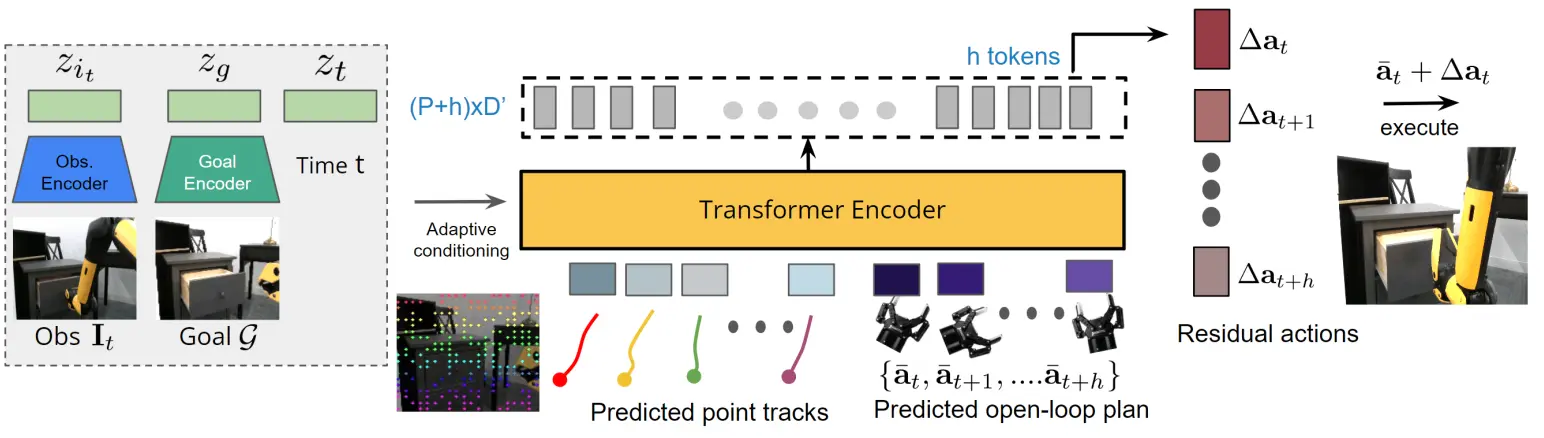
有了这些点之后,就不难给出一个刚性变化来描述 Action 了。然而刚性变化注定不太靠谱,于是乎加入了一个残差策略,再用另一个模型的预测来修正之前的结果。按照文章的表述,残差控制可以增加准确度并非首创,不过确实是一个纠正偏差的好方法,前面的轨迹生成并求刚性变化,获得一个变化之后加上残差,这本质上其实和 ATM 直接通过一个模型进行 action 的求解是等价的,毕竟刚性变化同样可以用模型来进行表征。
Extreme Cross-Embodiment#
尝试跨机器人模态的表征学习
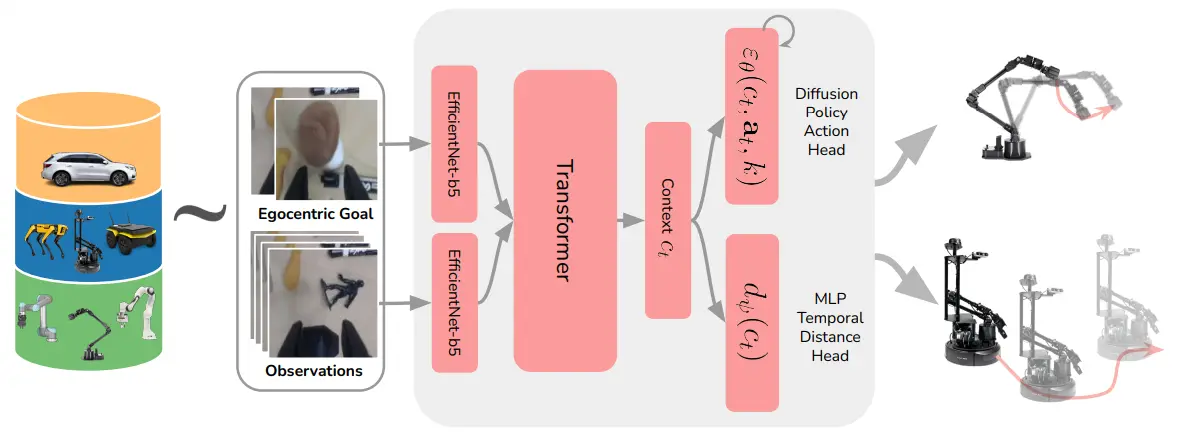
这篇文章基本的故事是说要实现一种跨不同机器人模态的表征学习,但是实际上只是视觉导航以及抓取这两种任务。本身的想法就是说,移动和抓取的本质上都是让EE-Pose 或者相机坐标系发生了坐标系变换,实际上是等价的,所以说可以统一,然后就开始直接训练一个模型,输入是 state 和 goal,之后直接融合,获得两个目标,一个是机械臂的位姿(DiT),一个是距离的预测(MLP),也算是将这两个任务统一了一点。
之前的任务,绝大多数都在处理单一的机器人下的任务,一般为机械臂,这篇的创新点也就止步于同时使用两种训练数据了,最后从效果上来看并非是十分理想。
ECoT#
在传统 CoT 中加入 Embodied 条件,生成 CoT 数据的操作具有借鉴意义
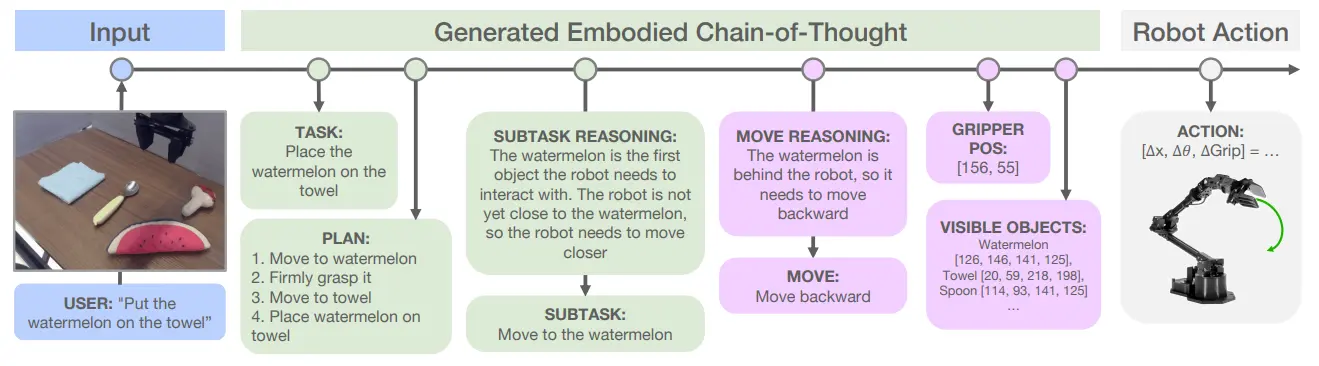
ECoT 的文章可以说是 CoT 在 Embodied AI 领域里面一次较为全面的运用,或者说这其中包括让模型显式输出不同的中间表征,包括说输出 Task,SubTask,Planning,Move 以及各种的包括说 Gripper Pos 以及 Objects 的 Grounding。
本身的模型依然是 OpenVLA,也就是在进行了上述的 Reasoning 之后输出离散化的 Action。
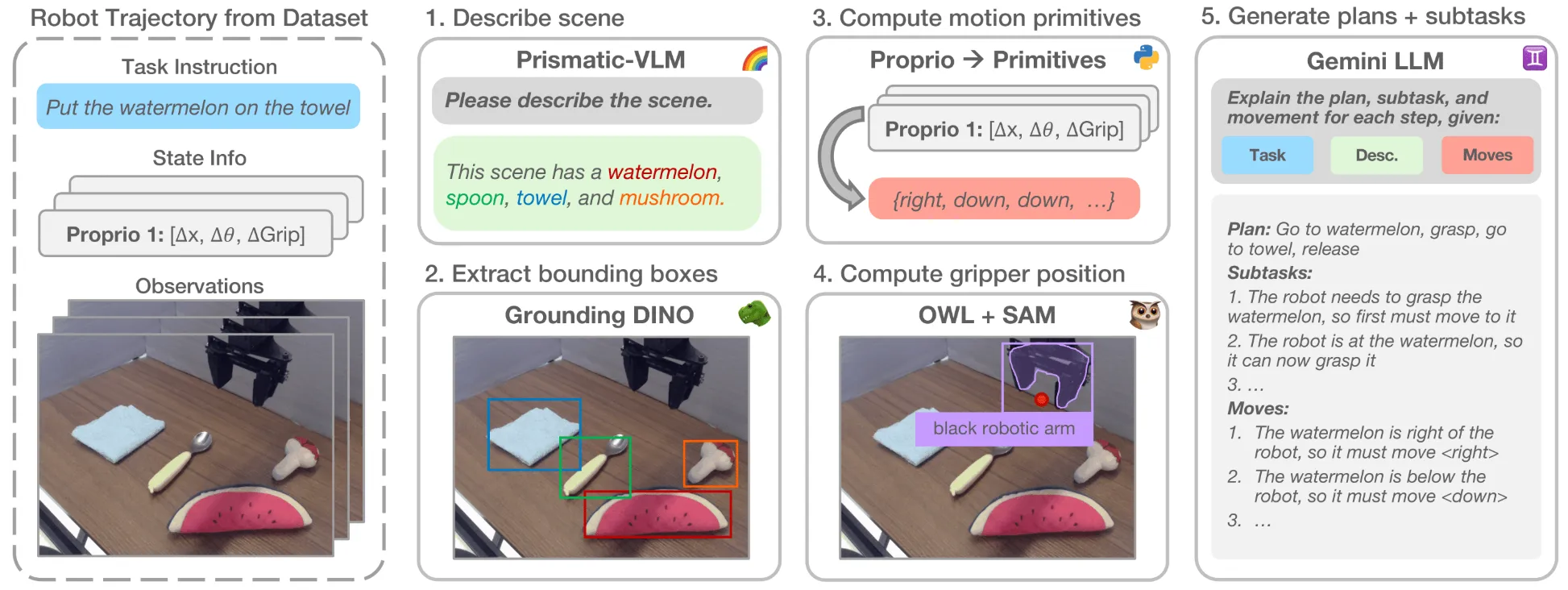
ECoT 在 OXE 上收集了不少的 CoT 输出,建立了一套标注中间表征的方法,对于不同的内容使用不同的方法,如上图所示。
ECoT 在 Reasoning 和 Action 相结合这方面还是做的很早的,但是依然有一些 limitation。本身 OpenVLA 的输出已经是 next token prediction,加上如此如此多的中间表征,可以见得模型的执行频率必然不高。如何让模型在执行的过程中自行控制何时开始 reasoning,甚至如何进行隐式推理,这些依然是一个值得思考的问题。
VoxPoser#
通过 LLM 和 VLM 获取图像表征,输出价值图以指导轨迹规划

VoxPoser 本身是通过 LLM 以及 VLM 获取图像以及任务的表征,并且想要输出两张价值图,其中 VLM 是传统的 VLM,类似于开集检测器,可以获得物体的位置,之后 LLM 来去处理这些位置,获得两张价值图,这两张价值图进一步引导模型进行轨迹规划。
使用价值图进行轨迹规划还是一个比较有趣的话题的,但是事实上从 VLM 输出的 Code 来表征价值图,还是会显得缺乏一些细粒度,只能说有一定的可行性。
MOO#
基于 RT-1 架构,设置通用接口处理复杂语言表征,使用 Mask 作为 Target 的表征
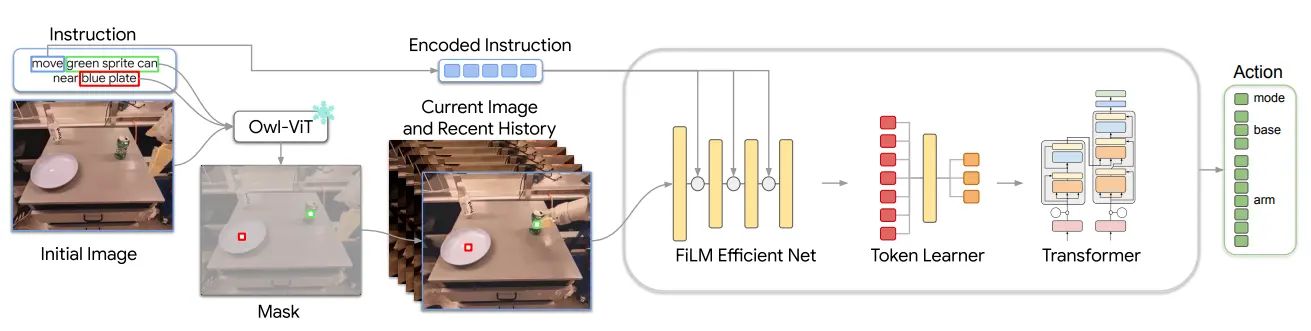
MOO 的 pipeline 很简单,本身使用了 RT-1 的架构,大致的流程就像 pipeline 里面描述的一样,其可以将 Mask 作为一个通道融到图像里面,然后将动词提取出来,来作为 text token,在 FiLM 里面进行调制。MOO 本身是在尝试一件事情,能否使用 Mask 作为中间表征,来更好地建立一种通用的抓取模型,从实验来说,确实也是进了大量了 Unseen 的实验,从效果上来说认证了这一点。
不过疑点可能在于,从结果上来看,模型的表现并没有比 RT-1 好太多,而从如今的视角来说,RT-1 并没有那么好的性能,尤其是接近于 zero-shot 等内容的时候。不过从思想上来说,往小了说,是 Mask 版本的 RT-Trajectory,而往大了说,可以说是某种 Visual centric 的 Guidance,到了 VLA 时代之后,这种思路似乎可以继续被采用。
ChatGPT for Robotics#
使用 ChatGPT 进行机器人应用的发散性思考,提出了 PromptCraft 等工具
本身可以理解为使用 ChatGPT 去做机器人的一个发散性的思考,同时提出了诸如 PromptCraft 之类的工具。
PIVOT#
利用大模型的 VLM 能力,通过选择题方式在具身智能任务中进行操作方向的决策
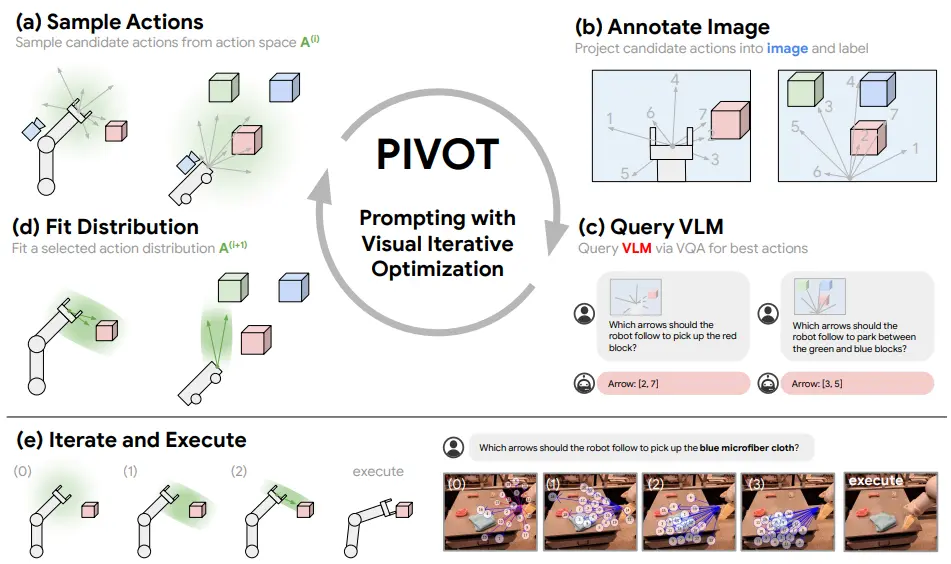
PIVOT 的思想还是比较有趣的,也算是充分利用的 MLLM 的 VLM 能力。本身的思路其实在于,让大模型在具身智能的任务中进行生成式不太靠谱,同时进行空间自由度的生成更加有问题了,毕竟自由度是具有差距的,但是去做平面的选择题还是可以的。
于是设计了一套 Pipeline,可以先随机 sample 一些动作或者轨迹,之后将这些内容 annotate 到图片上,毕竟本身模型在图片上进行方位的理解会更好。在此之后就是让模型选择,然后一次次的选择即可。
在这里除了明面上的这些内容,有意思的一点在于,正如在 Extreme Cross-Embodiment 中所说的一样,本身 Navigation 以及 Manipulation 都是坐标系的变化,因此 PIVOT 还可以做 Navigation 相关的任务。
Code As Policies#
使用 LLM 输出代码,并建立 Rule based 方法进行 control
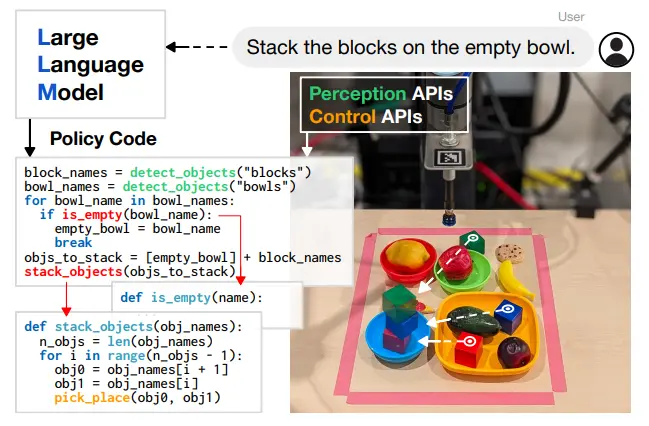
Code as Policy 这篇文章的思路很简单,就是可以使用代码来控制机器人,这等于可以让 LLM 与环境进行持续且合理的交互。大模型可以通过调用 API 来获取环境信息,比如说调用视觉 API 来获取物体位置,同时也支持了使用一些比如 for 之类的操作,毕竟代码肯定比一次次的生成式更加有条理。
在后续的工作中,Code as Policy 作为一种思想也得到了很多的运用。这其中的核心在于,代码允许整体的体系使用 Loop 进行更多的事情,保持频率以及稳定性,并且在达到某一条件的时候立刻跳出循环或者转折。Code as Policy 某种程度上位于线段的一个中点,一端是 System 2,假如说模型直接输出 Planning 等,一是 Guidance 不明确,而是按照较慢的频率推理,feedback 不实时;另一端则是 System 1,本身需要学习 Action 的表征,并不 Training free,难以 leverage VLM 的能力,并且缺乏泛化能力。因此还是十分巧妙的。
MOKA#
通过 Prompt-based VLM 进行路径规划,使用标注点引导模型完成动作
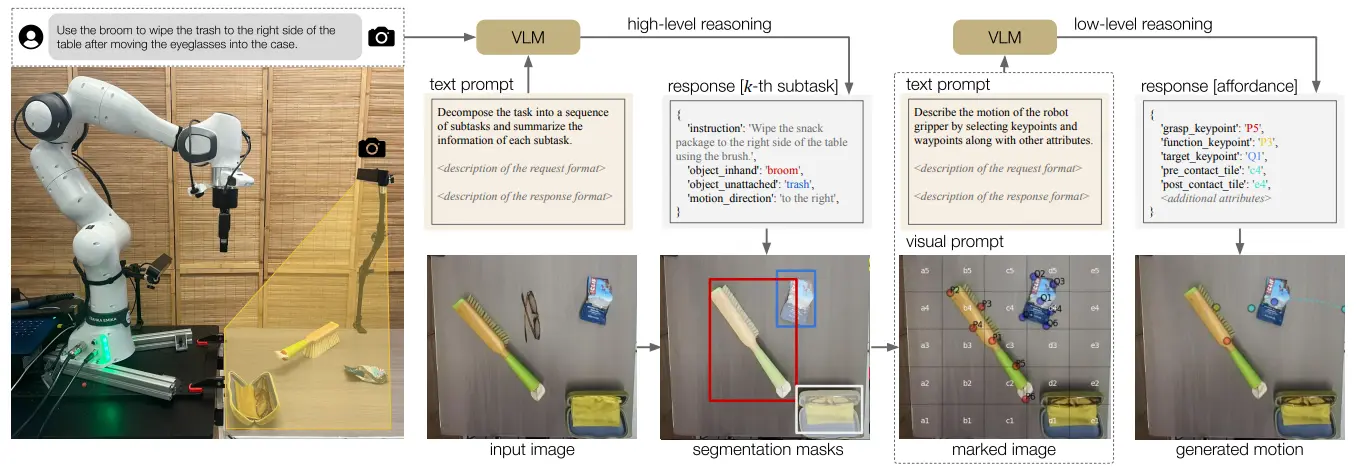
MOKA 的思路其实本质上和 CoPa 以及 PIVOT 是十分类似的,都是使用 Prompt-based 的 VLM,通过将不同的选择 annotate 到图像上,并且让模型进行选择,从而进行路径的规划。
MOKA 等于希望通过若干的点标注,让模型学会如何去完成动作。所以流程上也是首先先找到需要操作的物体,然后再采样抓握点以及路径点之类的,最后结束。甚至说虽然 MOKA 里面没有明说,但是实际上其对于抓握点进行 filter,并且通过 filter 获得抓握姿态,这个流程实际上和 CoPa 可以说是一模一样,只是说 MOKA 希望通过路径点来完成动作,而 CoPa 则希望通过向量来完成动作。
RoboPoint#
实现 point grounding 模型,其实本质是 perception 模型
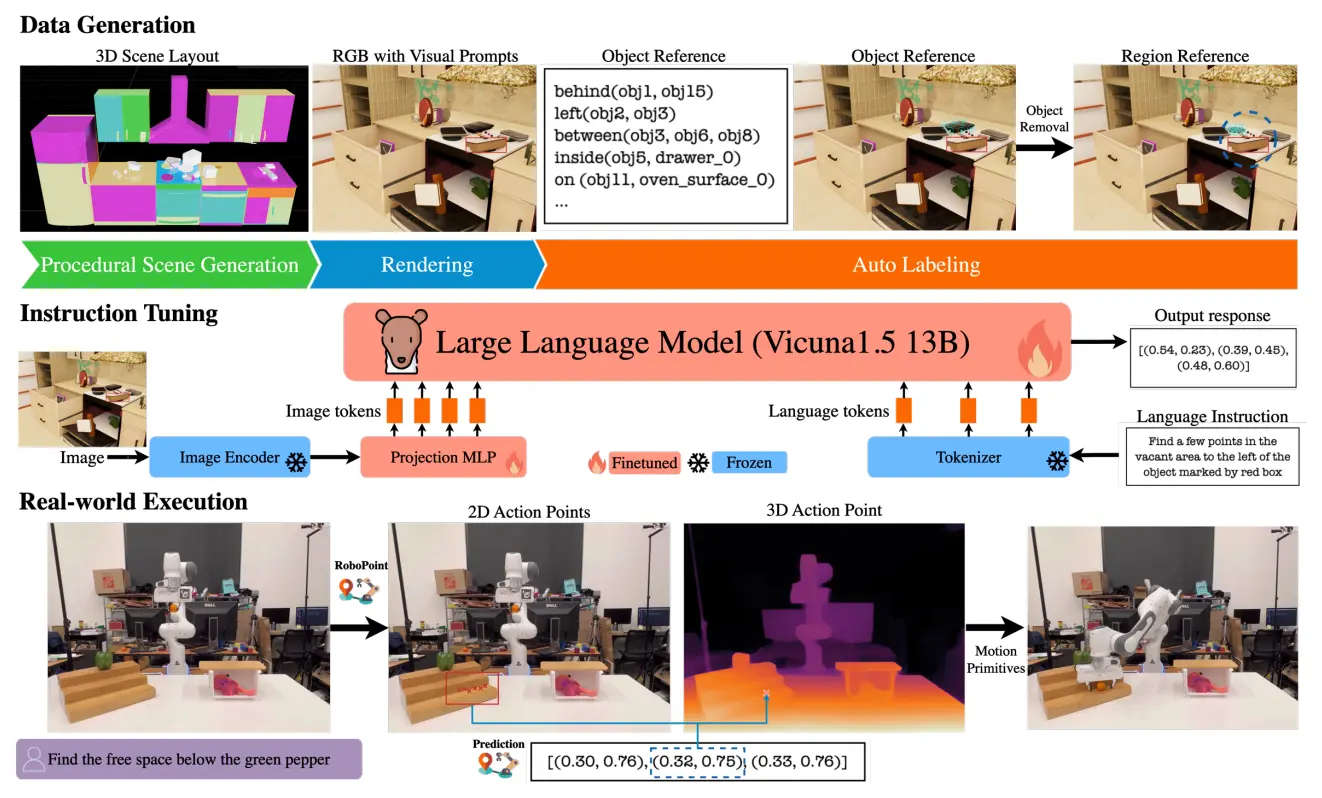
RoboPoint 本身也算是一个十分直接的论文了,基于 Vicunal1.5 13B 进行训练,去训练模型对于 point 的 grounding 模型,也是按照 System 2 的路数。
本身论文并没有很多值得更多 highlight 的点,不过在这里可以依然延伸一下,在这个时期,包括甚至说现在,单独去做 System 2 的模型还是有很多,但是很多时候,事实上学界并不清楚 System 1 需要 System 2 提供什么。整体双系统,借助 System 2 的 VLM 的能力来实现泛化的故事,在现在看来,还是需要两个系统的相互迭代,才可以得出结论,届时需要 Box 还是 Point,才可以有一个继续推进的方向。
GR-1#
在人类数据上预训练,再在机器人数据上微调,通过视频预测建立 World Model
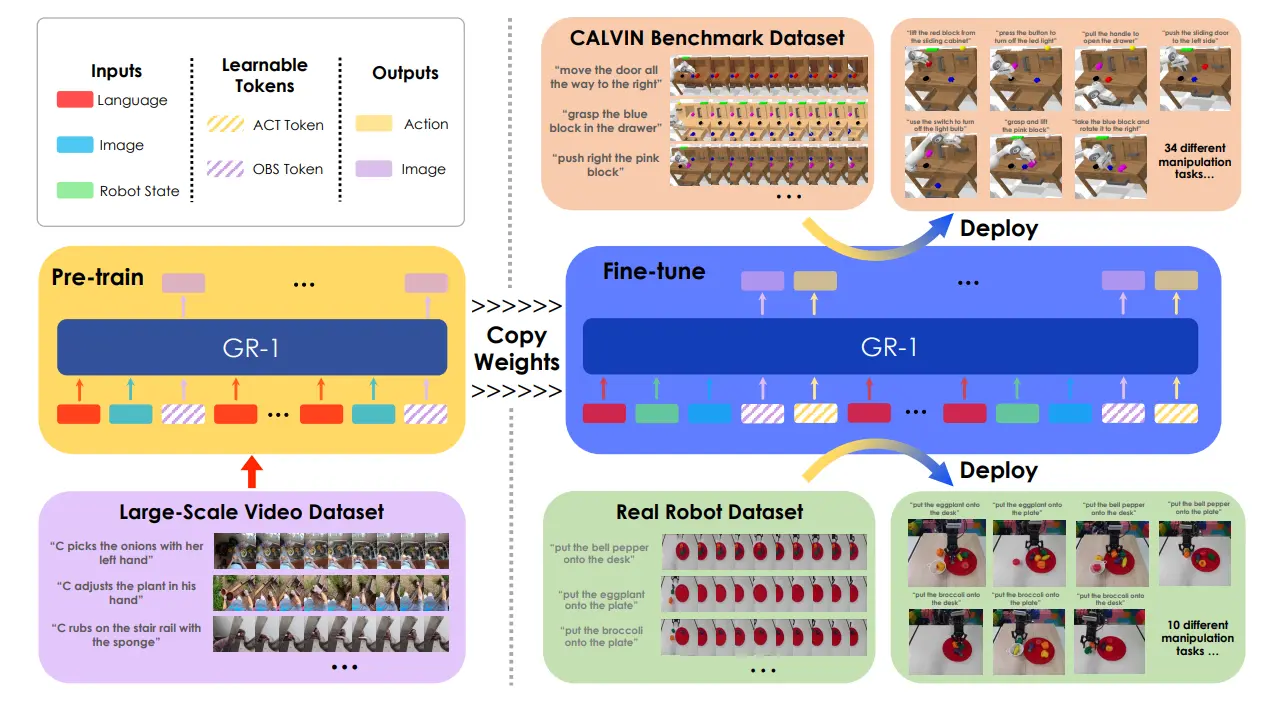
GR-1 可以说是一个很不错的经典工作了,用了十分直接的方法,效果也很不错。具体来说先在人类数据上训练,然后放到机器人数据里面进行 fine-tune。执行的 Task 有两个,一个是预测图片(多张图片,也可以说是视频),一个是预测动作,见下图。
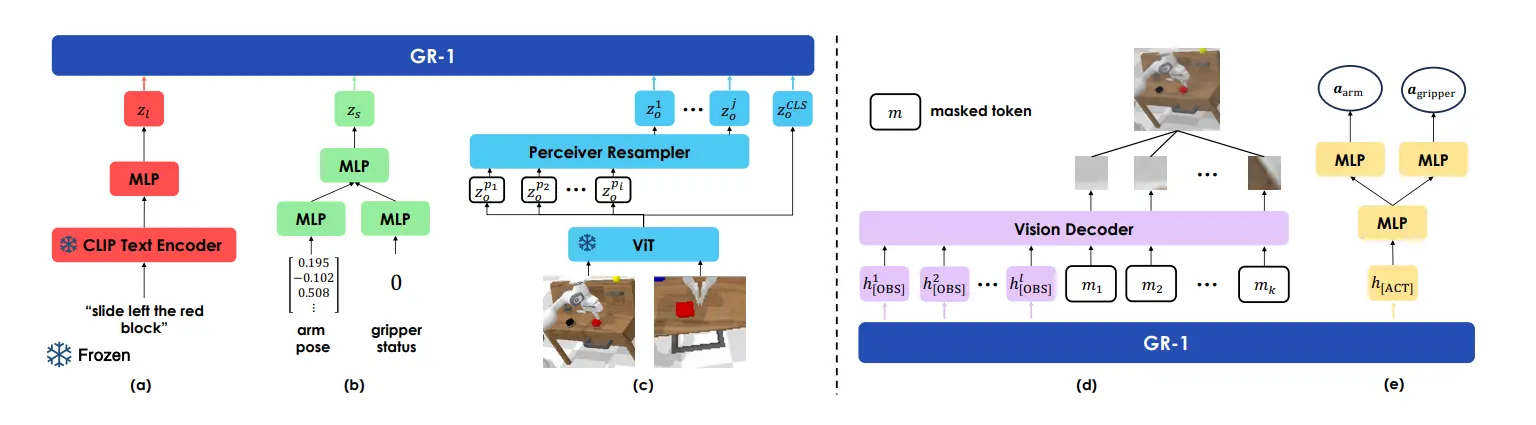
本身因为 GR-1 是 GPT 架构的模型,所以说输出的 Token 数量是可以根据不同的训练阶段进行调整的,并且不同的阶段,不同位置的 token 可以拥有不同的含义。GR-1 运用了 world model 的思想,通过预测视频来预测未来,从而认为模型可以 train 出来对于世界如何运作的理解,然后在这个基础上进行微调。
本身模型分为两个阶段的训练,第一个阶段是在视频上进行预训练,这里面输入图片以及 Language,输出的 Token 可以被解码为预测的未来图像,称之为 [OBS]。同时,在后训练的时候,额外预测可以被 MLP 解码为动作的 token,称之为 [ACT]。GR-1 预测未来的若干帧。
从数据的角度来看,这种使用视频预测的策略确实很不错,因为只要存在一个文字视频对(应该不少),那么就可以大量地进行 scaling up。
说到 Scaling up,总的来说,依然是需要体现出从 Scaling up 的 messy 数据中 transfer 出来的,几乎可以 zero-shot 到 post-training 之后的能力。例如在人类示教视频中进行了一个动作,而这个动作是并不在机器人的数据里面,但是在实验中机器人可以执行,那么就很能体现 scaling up 的意义了。因为加入的大量人类视频数据里面学习到的 skill 可以 transfer 到机器人的动作能力中。毕竟人类数据很多,而且录制起来也很简单,这就会成为一种未来。而这种验证,在未来的 VLA 中有望被实现。