
Paper Reading: Unify MLLM
浅浅尝试读一下Unify MLLM。
前言#
因为朋友们都在做 Unified MLLM,所以我也浅浅尝试读一下,这样可以有一些参与感。假如理解 Unify Model 做的事情是 Multi-in Multi-out 的大模型,那么按照这种定义,其实 VLA 也是 Unify Model 的一种,说不定可以触类旁通呢~
SEED#
使用 VQ,建立 SEED tokenizer,让 LLM 支持输入输出 SEED token,进一步支持多模态输入输出
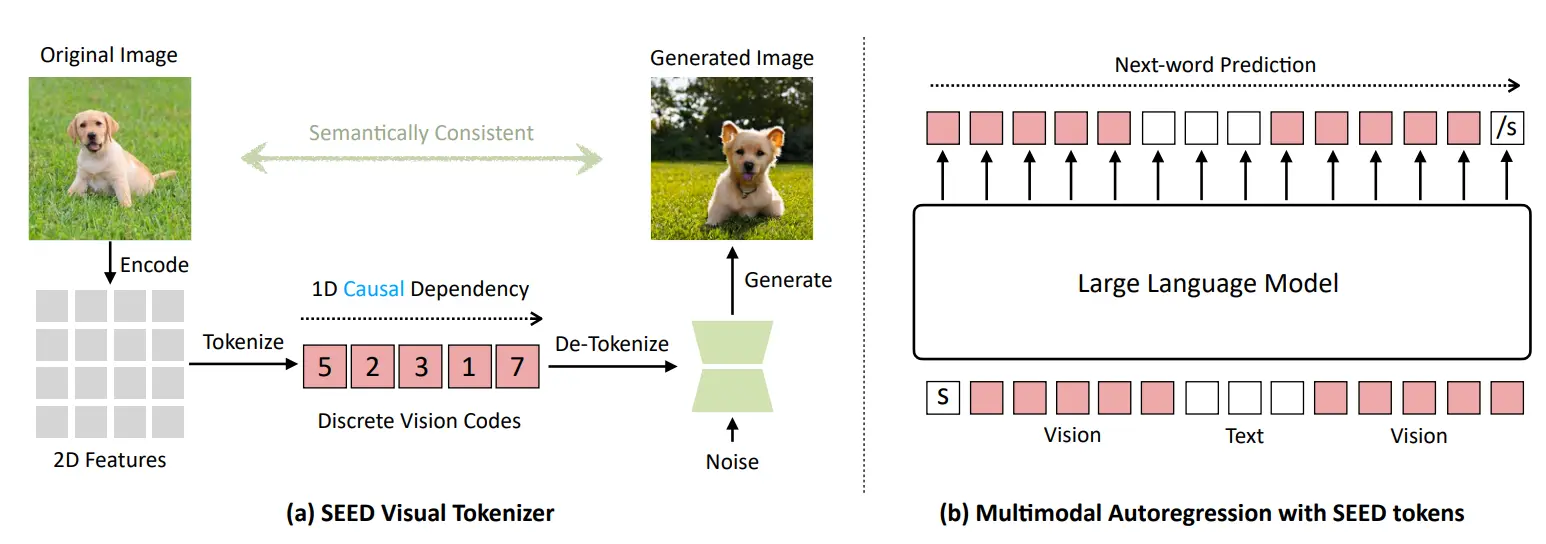
按照朋友的 Paper List,这一篇应该是较早的 Paper 了,或许是第一个提出这个想法的 Paper。大概的思路其实和正常的 MLLM 差不多,本来的模型支持 Visual token 的输入,并且和 Text token concat 到一起。这里因为用 Reconstruct,因此假如说 LLM 可以输出对应的 Token,那么就可以进行 VQ 的解码,也就自然可以生成图片了。过程中很多讲究,比如说使用 1D 的 token 而非 2D,兼容单项注意力,同时用高层语义。本身的结构还是经典的一些 Q-Former 和 Unet,这里不展开。
LaVIT#
使用 token selector/merger 来产生 Visual token,之后还是训练 VQ,并且 LLM 作为 Fusion,用 token 表示 img 与 text 的隔断
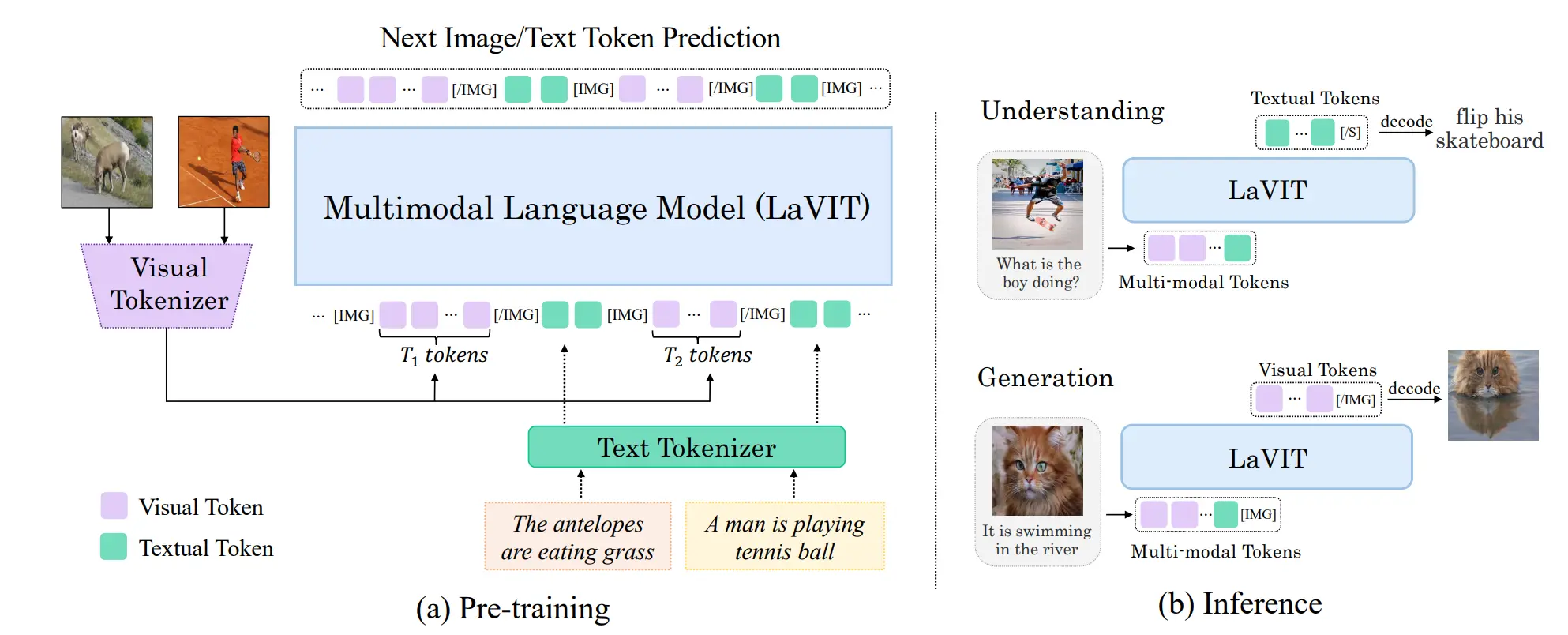
如图所示,实际上这个模型长得十分的标准,使用 Vision Encoder 以及 Text Encoder 来分别处理图片和文本,用 LLM 进行 Fusion 之后再用 Decoder 生成图片或者文本。一个设计是 Vision Encoder 中使用的 token selector 和 merger,selector 选择重要的 token,merger 用 cross attention 把选中和没选中的 token 进行融合。这一步本质上是为了动态选择 token,进行信息压缩,以及可以生成动态长度的 visual token。如下所示:
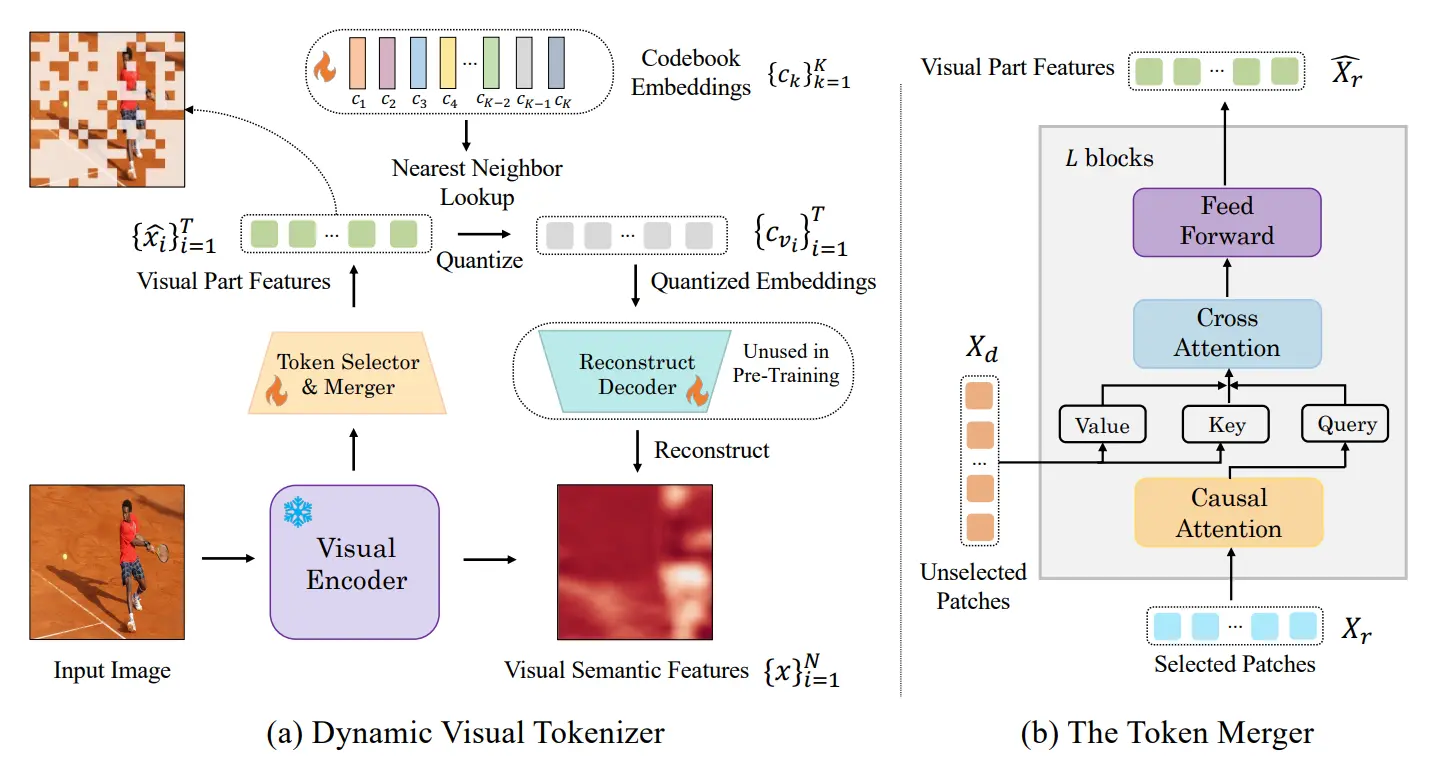
所以说这篇也是比较符合直觉的。只是一个疑问是这个 token selector 和 merger 的结构是否真的有用,难道本来的 token 输出真的很 sparse 吗?假如是的话,不是应该训练一个 encoder 吗,为什么执着于这个设计。
以及后续和朋友聊了一下,这个架构的本质问题可能在于 interleave 的设计,也就是一段文字一段图片这种结构交错在一起。理论来说这样子是可行的,但是事实上可以思考一下,有点像是让模型将两个任务交叉在一起,其实很难学到两个的并集,从而学不好。真正涉及所谓图片编辑的场景,都较少需要语言作为上下文,或者说可以被解耦为多次推理。一次推理中涉及多轮所谓图片以及语言的交互,其实乍一想可能是解数学几何题,但是这种明显使用 symbolic 的方式来解决更好。模型的“大脑”很难在两个模式之间切换,这是一个本质问题吧。
SEED-X#
Two Stage 训练的 Visual tokenizer,标准的 MLLM 架构,可以输出 Visual token 作为 UNet 的 conditional 输入
这篇感觉就是已经是比较成熟的设计了。标准的 MLLM 架构作为输入,支持对于图片的各种分辨率的适应。本身 Visual tokenizer 就是 ViT,之后输入到 MLLM 中。然后在输出的时候,如果说有必要输出 Visual token,那么输出之后就作为 UNet 的 conditional 输入进 SD 中,实现图片编辑。这篇是多个 Stage 的训练,感觉或许继续看下去之后回头看这里或许可以有一些感悟。
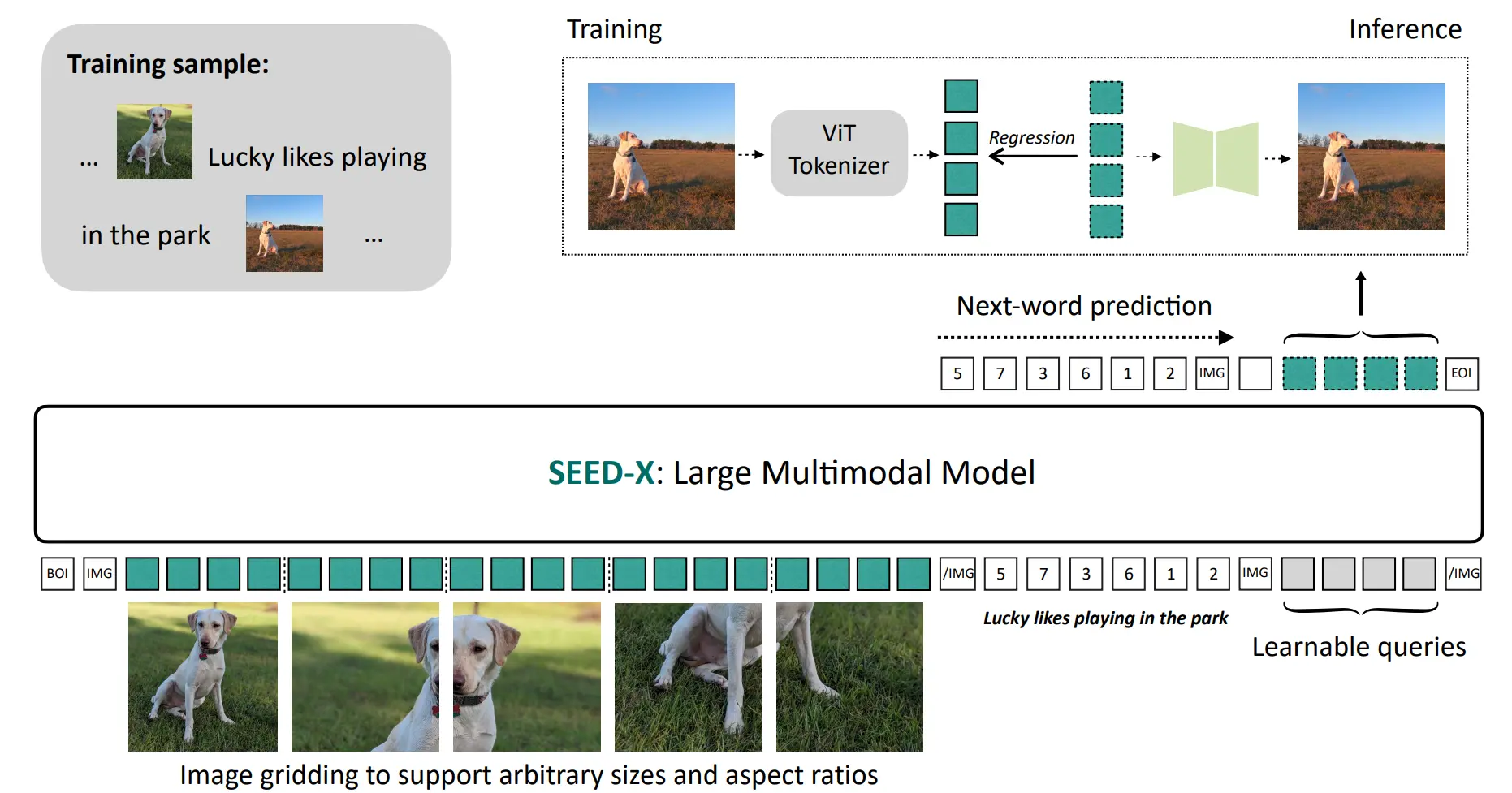
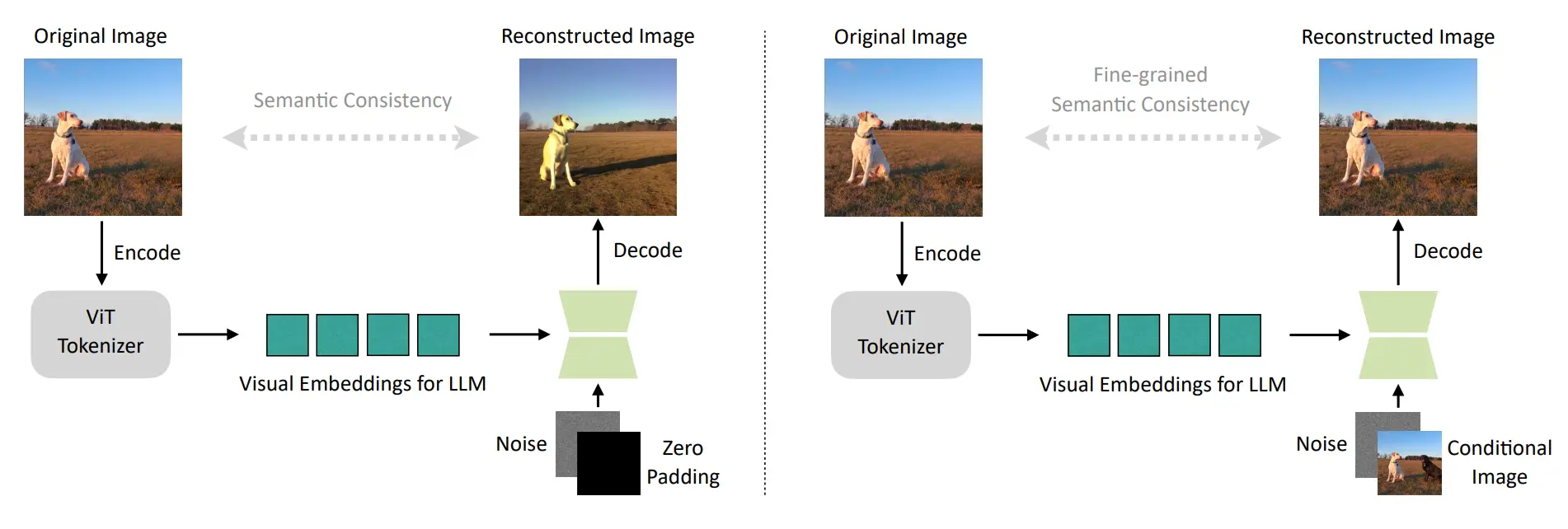
首先是训练了 Visual tokenizer,这一部分分为两个 Stage,第一个 Stage 就是简单的训练,直接 Noise 图片以及 Zero Padding 来 concat 进行输入,ViT 的输出作为 condition 代替本来的 language condition,然后做 reconstruction;第二个 Stage 的输入变为一个 Noise + Conditional Image 的输入,这一部分的说明是可以恢复原始图像的细粒度细节,可以理解为使得 SD 这一部分可以兼容正常的图像生成以及图像编辑。
之后也就是标准的 two stage MLLM 训练,第一个 stage 用 LoRA 训练了 Llama2-chat-13B,包括了 image-captions pairs, grounded image-texts, interleaved image-text data, OCR data and pure texts。第二个 stage 就是根据具体的任务再进行 instruction tuning,也就是说本质上 SEED-X 是一气化三清,而不是真的一个模型。不过总的来说这个工作确实足够简洁且优雅,应该是很标准也很符合想象的设计了。