
Paper Reading: Embodied AI 3
从一些 Embodied AI 相关工作中扫过。
A_0#
训练 Diffusion 进行稀疏轨迹预测,之后 rule-base 执行
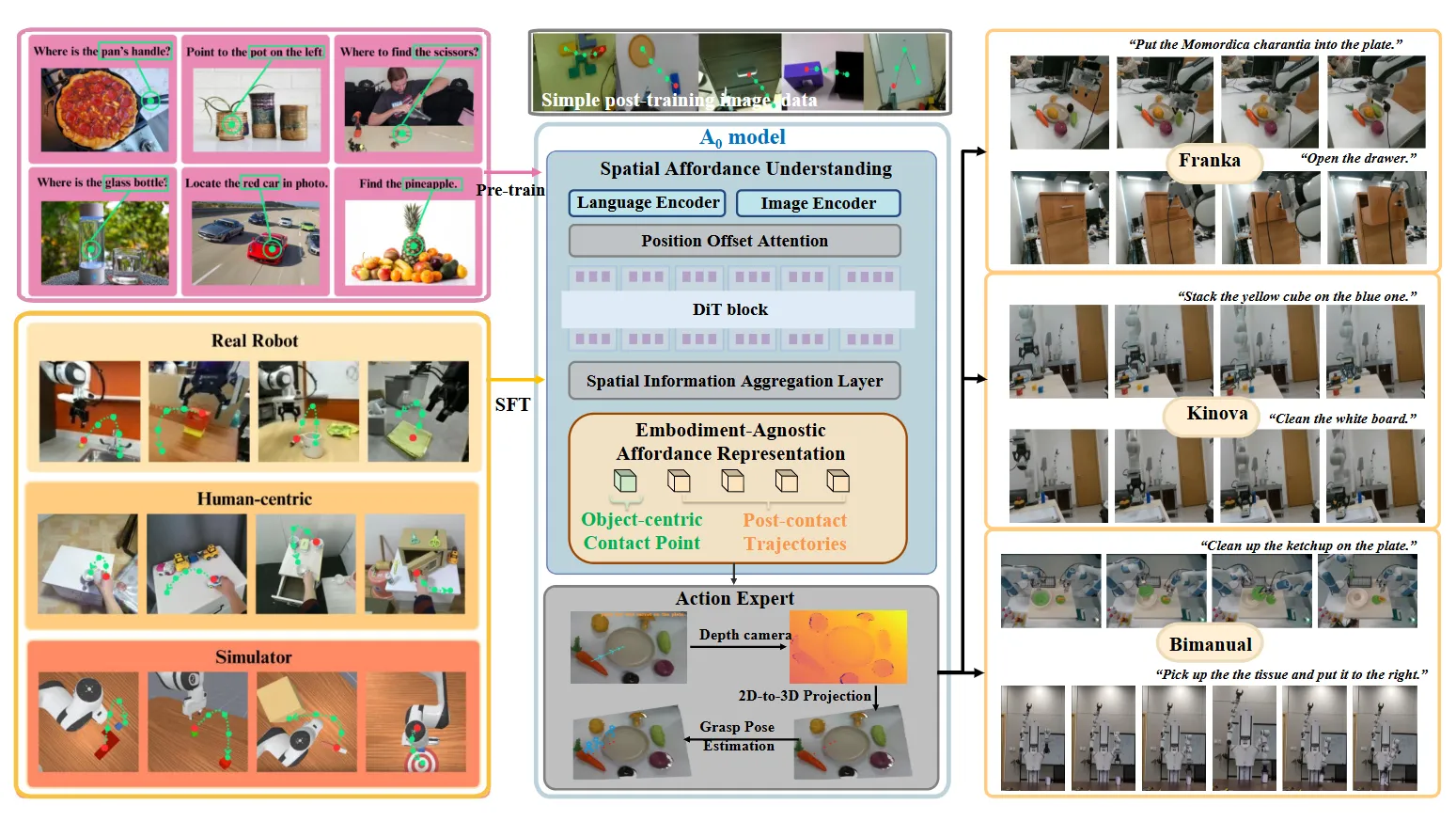
A_0 某种程度上算是类似于 RoboPoint 类似的思路。在之前的工作中使用了 Point 以及 Bounding box 作为输出,而 A_0 则是使用了 2D 的离散轨迹点作为输出。
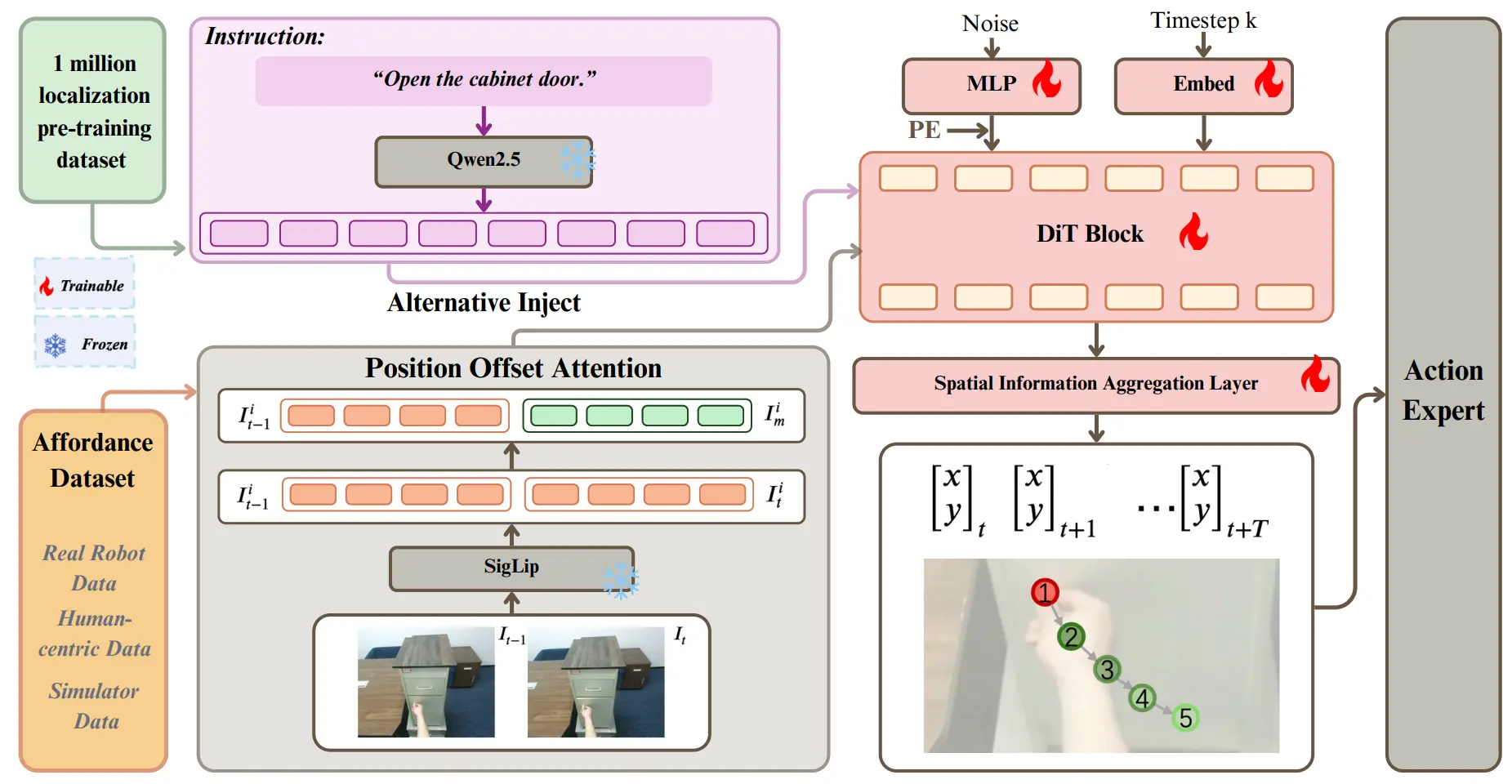
整体的框架如图所示,使用了 Qwen 2.5 作为 Language Encoder,并且使用 SigLip 作为 Vision Encoder,同时取 以及 的编码后的 Token 来加强运动信息的 perception。
之后就不难理解了,使用这些内容作为 condition,用 Diffusion 预测 2D 的稀疏轨迹,并且在大规模(~1M)的数据上进行预训练。在部署的时候,用 A_0 预测了 2D trace 之后,用 GraspNet 预测第一帧的 Grasp Pose,之后的用 VLM 判断高度,并且进行平滑,从而形成连续的轨迹,但是可想而知的是,limitations 可能在于执行一些更加灵巧操作的任务,还是需要下游是一个模型来进行训练,才可以表征。
OneTwoVLA#
自动切换 Reasoning 和 Action 的 VLA 模型
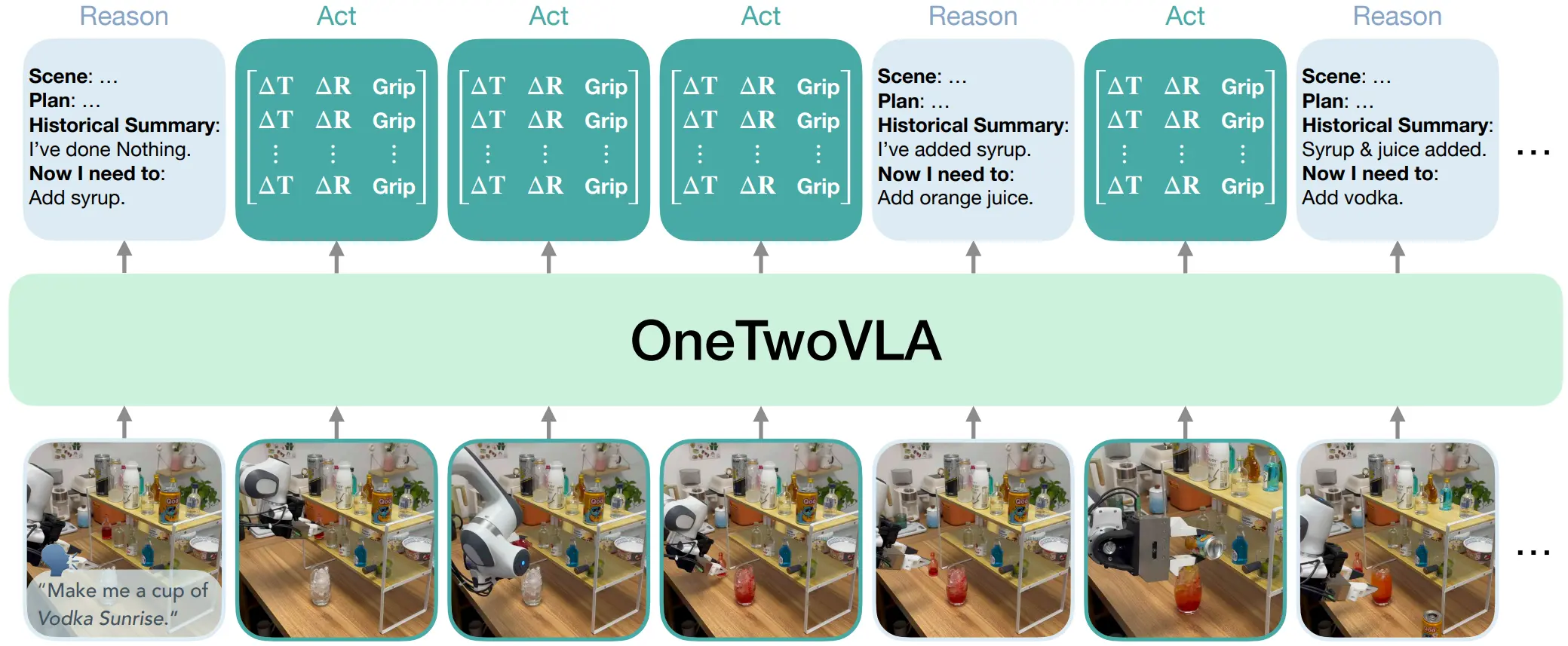
OneTwoVLA 算是比较有意思的 VLA 工作,可以自由切换 Reasoning 和 Action 的能力,本身就是根据输出 Begin Token,也就是 BOR 和 BOA 来决定处于哪个模式。本身假如说每一个 Action Chunk 执行完之后,还没有执行完 Action,VLM 那一部分会直接输出 BOA 然后继续输出 Action。
整体的模型的流程就是用 Pi0 的方式,但是支持了动态切换 Reasoning 和 Action。本身 Reasoning 的内容也值得参考,包括四类:详细场景描述,即突出任务相关物体的位置;高层计划,即逐步列出完成任务的操作;历史总结,即保持上下文感知;下一步计划,即接下来需要执行的操作。
本身方法还提供了一个生成 Reasoning 数据的 Pipeline,可以理解为就是 Gemini 负责 Reasoning,然后 Flux 1.x 负责图片生成。
Diffusion Policy#
Diffusion for Action Policy
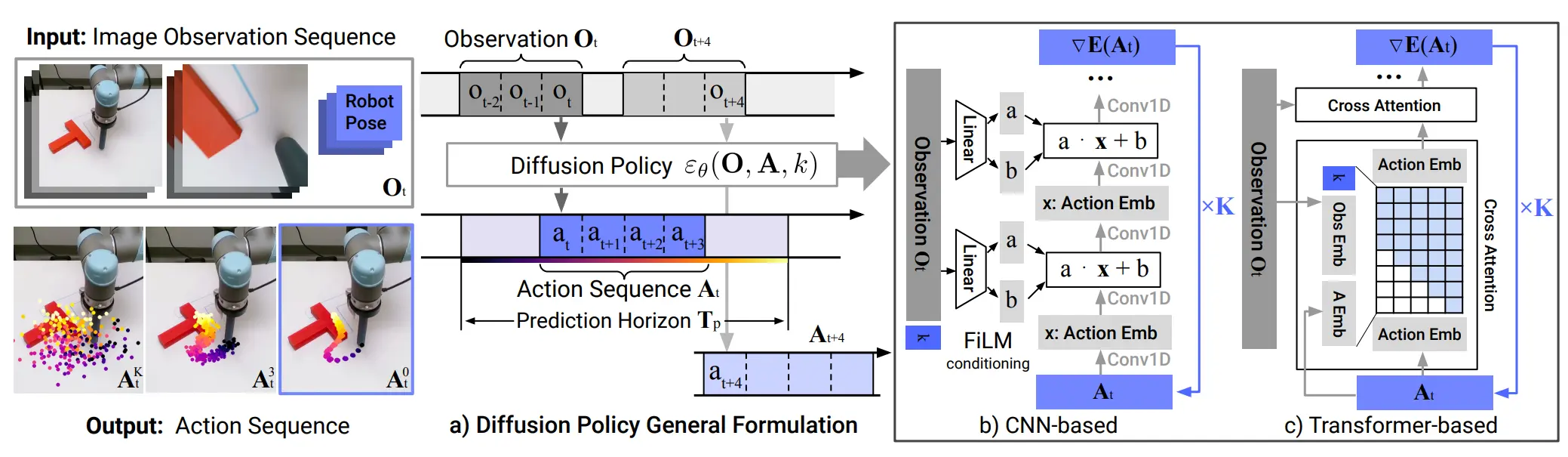
经典之作。用 Diffusion 做 Action 预测,输入是 Noise,输出是 Action Chunk,支持 CNN 以及 DiT 的两种变体。
鉴于 Diffusion 可以一次性输出一个 Action Chunk,在某种程度上推理速度更快,同时也支持 Condition,因此各种如 VLM 的 Hidden state 等可以被用作 Condition,从而在整个的 Manipulation 领域中被广泛应用。
RDT-1B#
大 DP
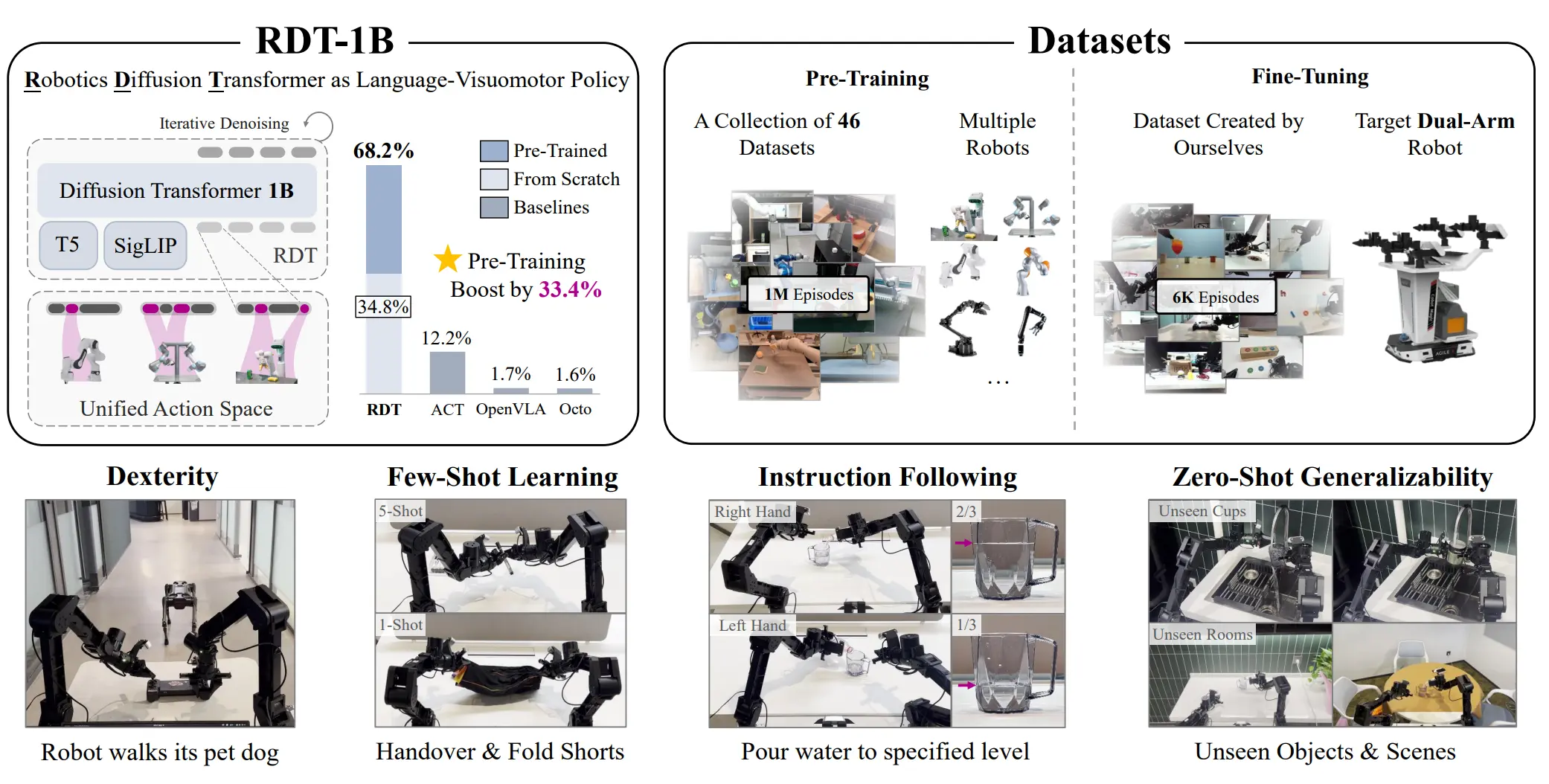
RDT-1B 本质上就是在多本体的数据集上训练的超大 DP。
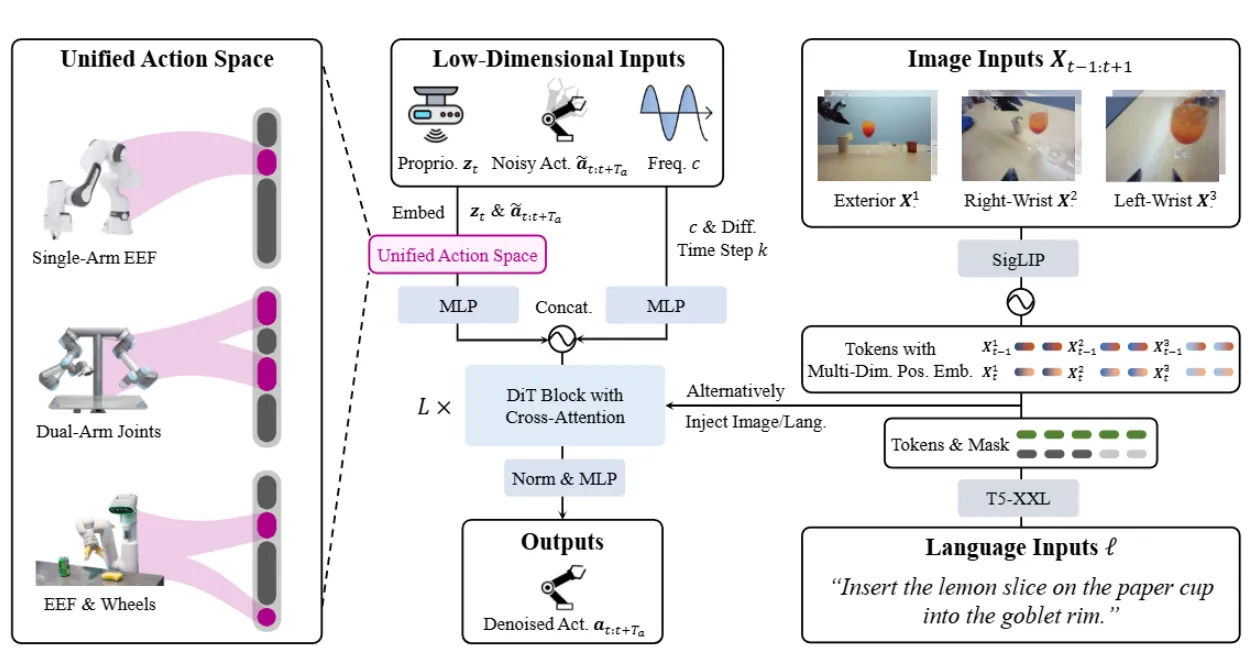
对于不同的本体,RDT 使用了叫做 Unify Action Space 的方案,也就是将不同本体的 Action 映射到一个很长的 Action Space 上的不同位置上。在此基础上,RDT-1B 依然是使用 DP 的范式,通过一个 Transformer 来预测 Action Chunk。
Octo#
History + Hidden state transformer 接 Action head
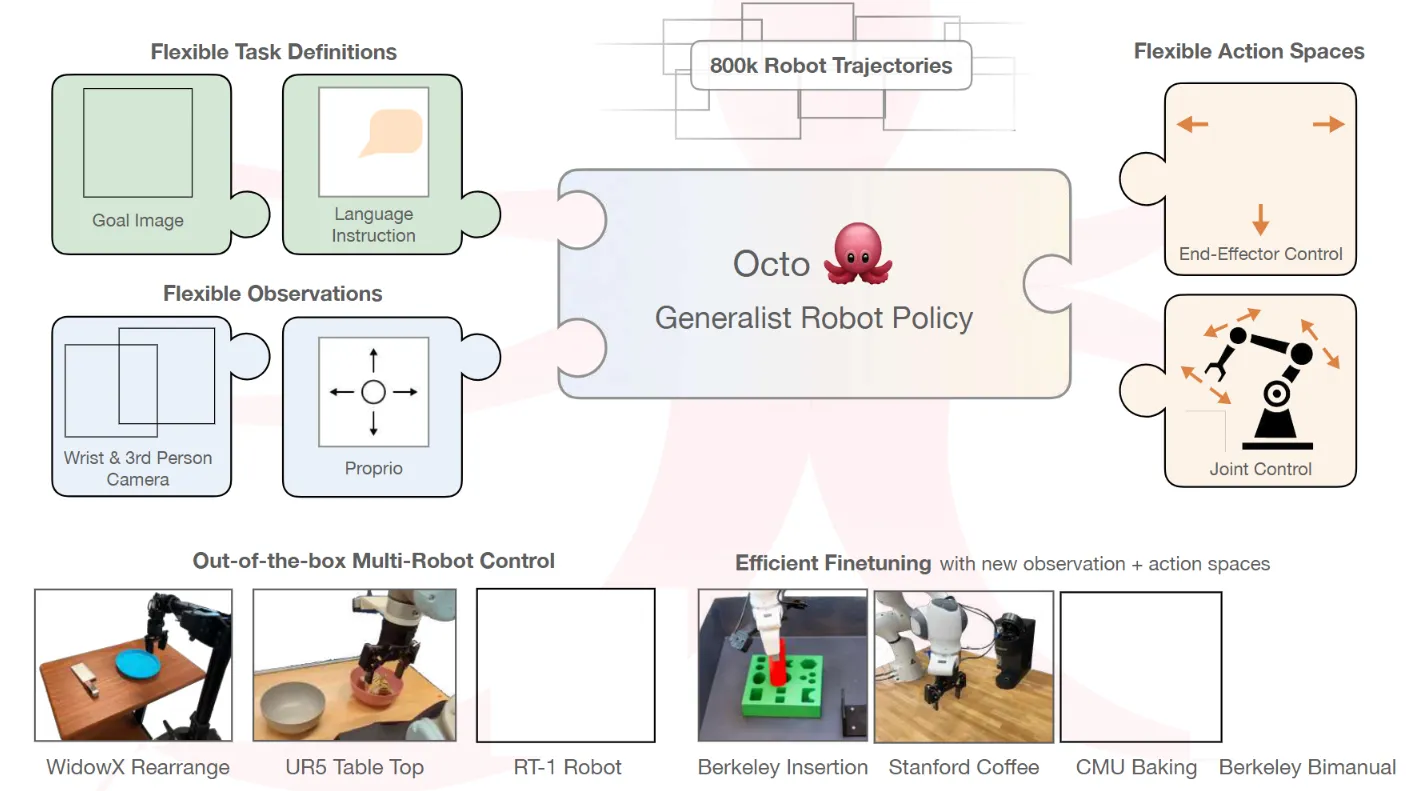
Octo 本身也是比较正常的设计。语言过 Text encoder,图像过 CNN,组成 OBS Chunk,可变长度,输出 Readout Token,类似于一种 hidden state,后面接一个 action Head。
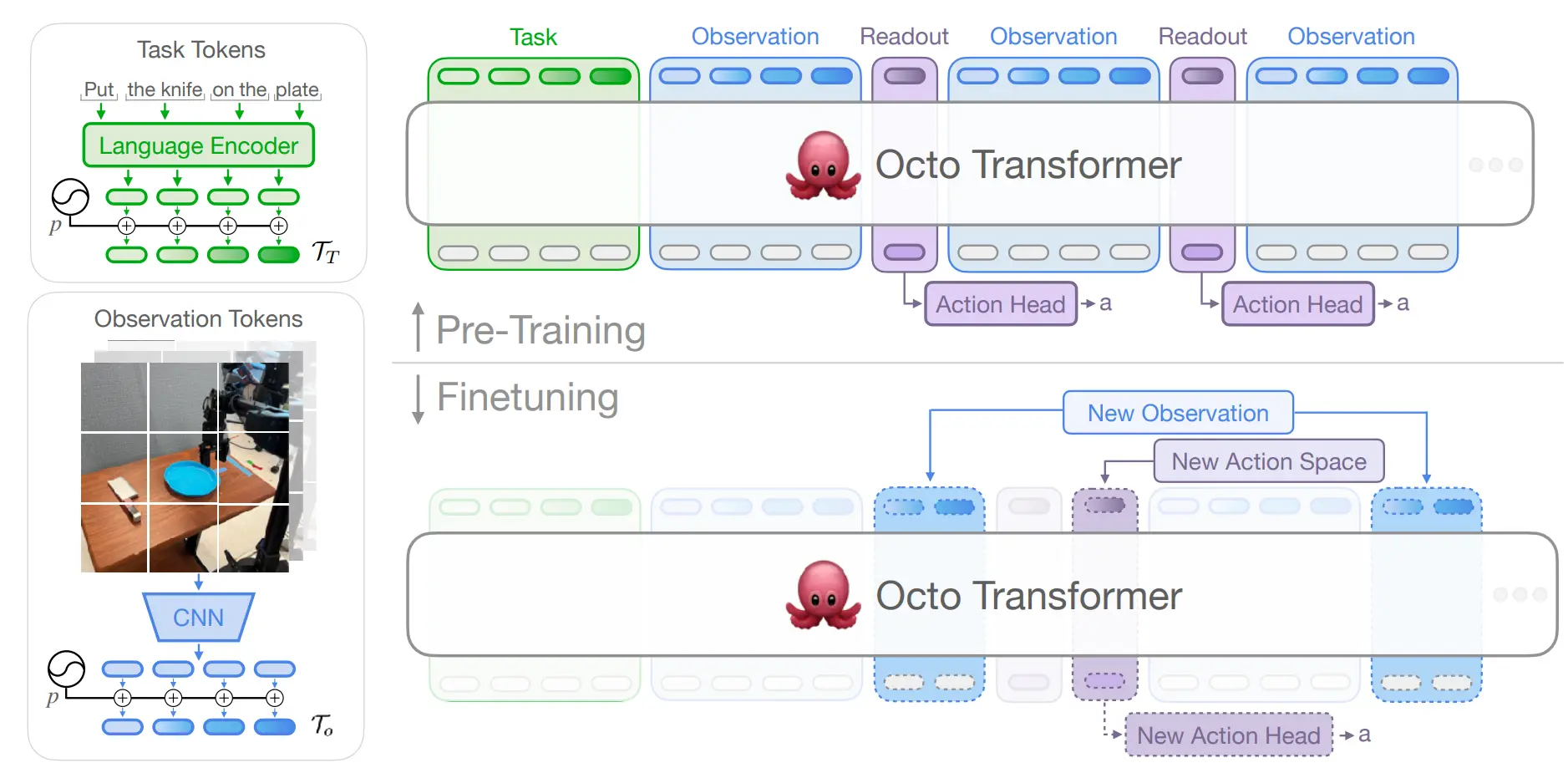
在切换本体之类的时候,直接换 action head 就好,同时也因此可以在多本体的数据集上进行训练。
CogACT#
VLM 输出 Cognition Token,之后接 DiT
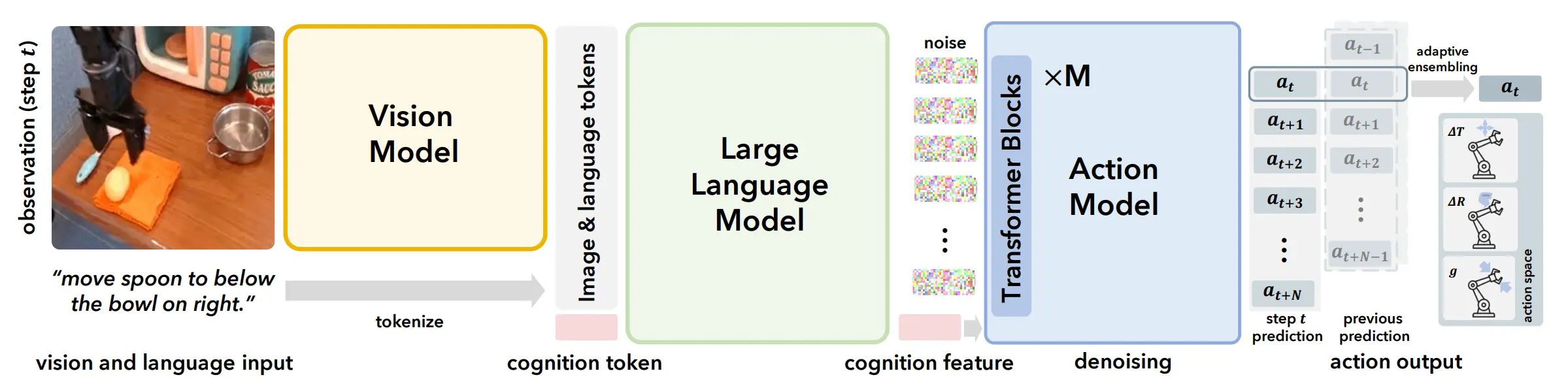
CogACT 本身算是在 TinyVLA 等一系列的 Pi-like 的工作中对于架构的另一次探索。本身 CogACT 遵循的思想,本质上还是希望尽可能 decouple VLM 和 DP 各自的职能。因此从架构上来看,CogACT 本身就是 VLM 之后输出包含一个 Cog Feature,说白了就是一个类似于 bert 的 cls token 一样的东西,然后和 noise 一起作为输入来让一个 DiT 的 DP 来生成 Action Chunk。
CogACT 本身在 Simpler Env 的 Benchmark 上取得了非常 impressive 的性能,证明了其可以在 OXE 级别的较大的数据集上进行训练并且在多任务中取得很高的性能,在此之后的一系列模型都在 Simpler 上进行训练,并且遵循 Pi-like 的范式,很大程度上也是因 CogACT 而起的。
Helix#
双系统模型
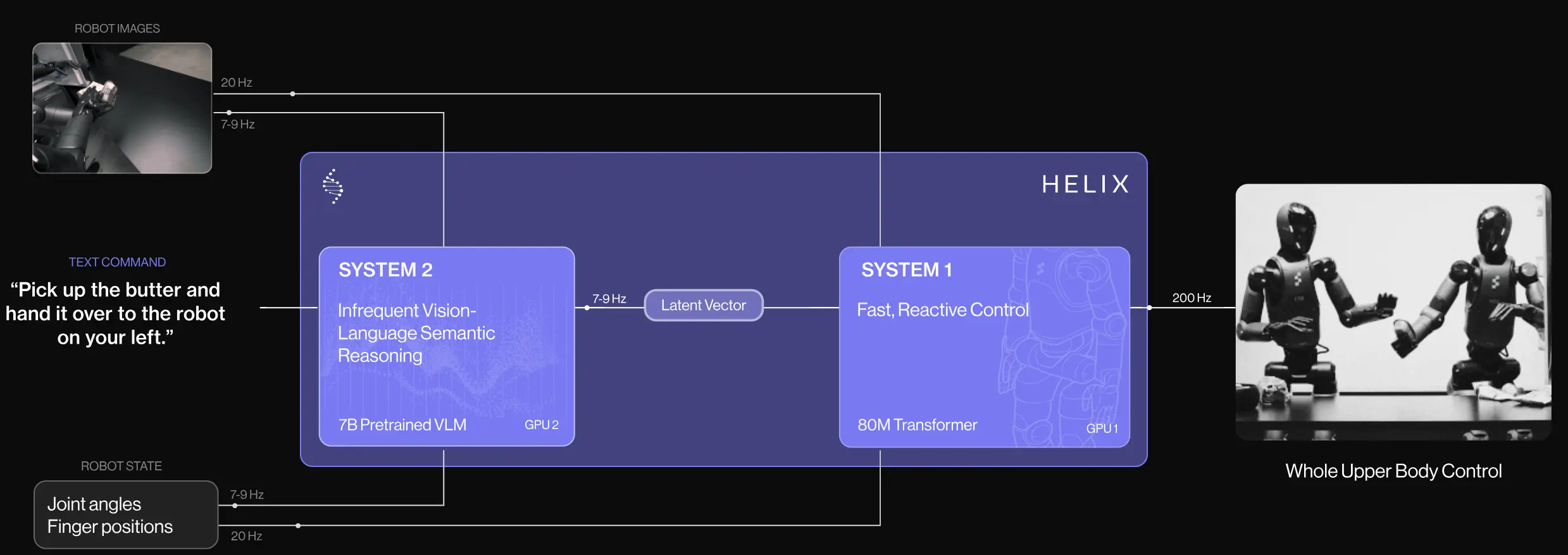
Helix 属于是双系统中较早的,两个模型分别推理,频率不同。从 demo 上,一个模型控制两个上身,比较 impressive,但是没有相关的 report,不评价。
FAST#
进行 DCT 的 Tokenizer
因为离散 Action 进行量化的方法生成的 Action token 效果不好,尤其是采样率越高,越容易退化为复读机,因此提出了 FAST Tokenizer。流程是先归一化 Action,之后 DCT 变换,按低频优先顺序展平不同维度的数据,然后用 BPE 压缩为稠密,这些操作都是可逆的。在经历上述操作之后,收敛效率更高,性能不掉。
FAST 本身在 Action token 的 embedding 上做出了新的范式,而并非简单的量化,其中的数学细节对于感兴趣的读者可以自行阅读,本身这一模块已经进行了封装,可以直接使用。
Magma#
大型的包含 Action 以及中间表征 SoM/ToM 的 pretrain 模型
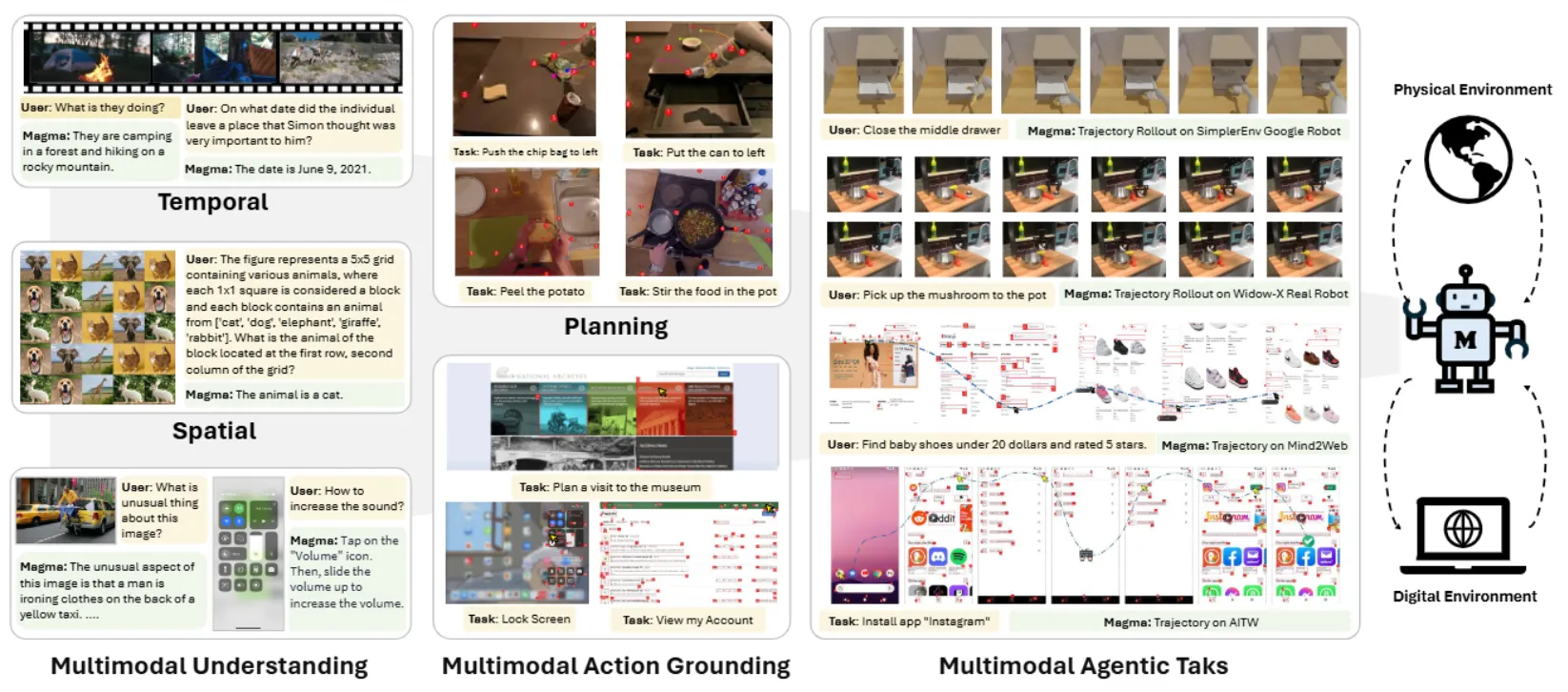
Magma 是较早提出 Generalist VLA 的模型。尽管在此之前,从 OpenVLA 开始,大量的模型就已经使用了 VLM 作为 pre-training 了,但是显式提出了模型需要在 General VQA 等任务上需要进行泛化,Magma 还是较早的。
本身 Magma 包含三个不同的任务,也就是多模态理解、UI 操作以及机器人操作。
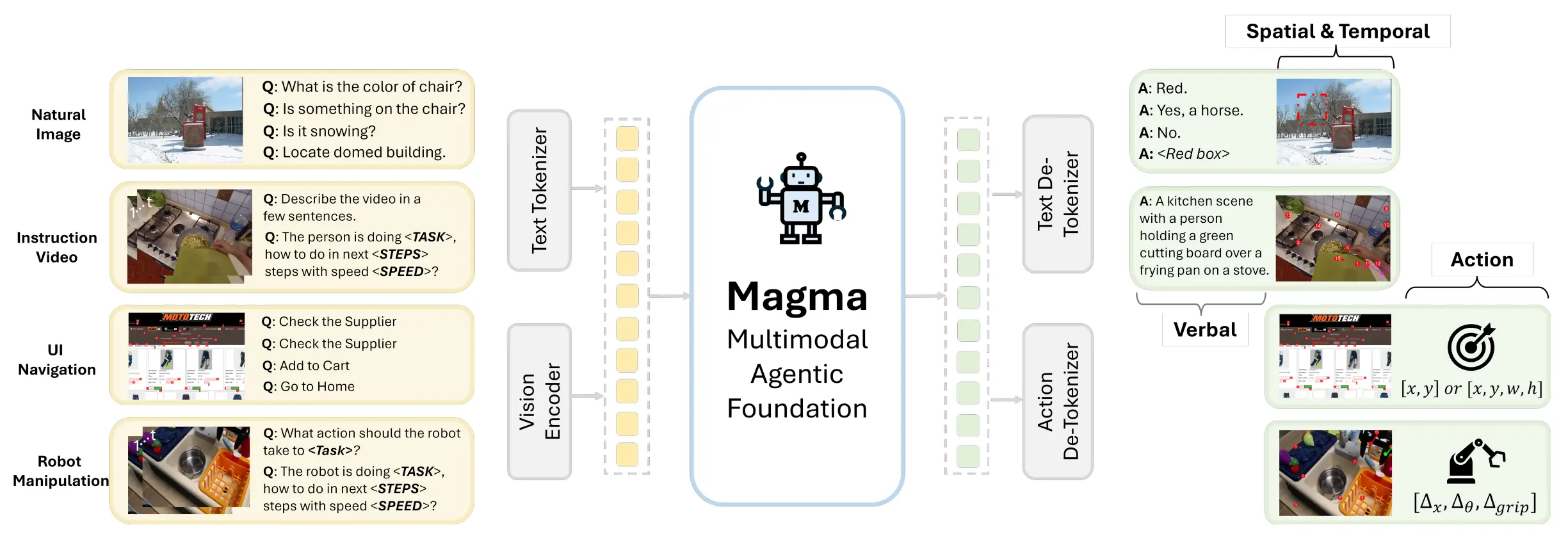
Magma 使用 LLaMa 3 作为 Backbone 进行训练,同时提出了 SoM 以及 ToM 的表征形式,也就是使用一系列的点来进行物体以及轨迹的表征,从而统一 UI 以及 Manipualtion 的接口,最后还是在全部的数据中进行训练,并且在 Manipulation 任务中再进行 finetune。对于 Manipulation 依然是 follow 的 OpenVLA 的量化 Action 范式。
ChatVLA#
MOE VLA
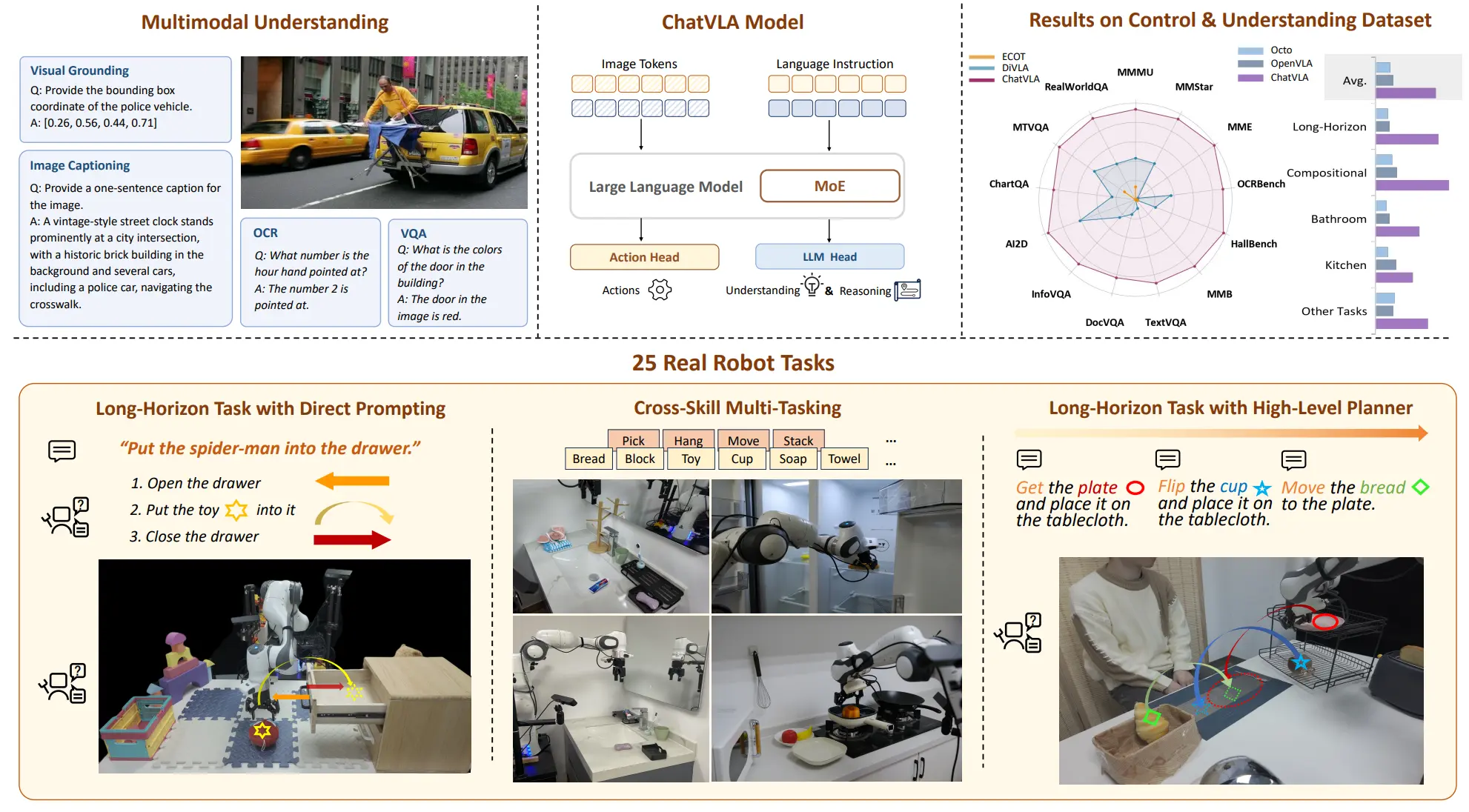
ChatVLA 本身依然是使用了 OpenVLA 的范式,加入了共享 Transformer 但是不共享 FFN 的 MOE,这里的 MOE 是静态的路由,在不同的数据时激活不同的 Expert。
ChatVLA 同时使用了两阶段训练,第一阶段只使用机器人数据,第二阶段加入推理数据 co-train。整体来说也是试图 leverage VLM 的能力到 VLA,并且性能也算说得过去。
ChatVLA-2#
Dynamic MOE VLA
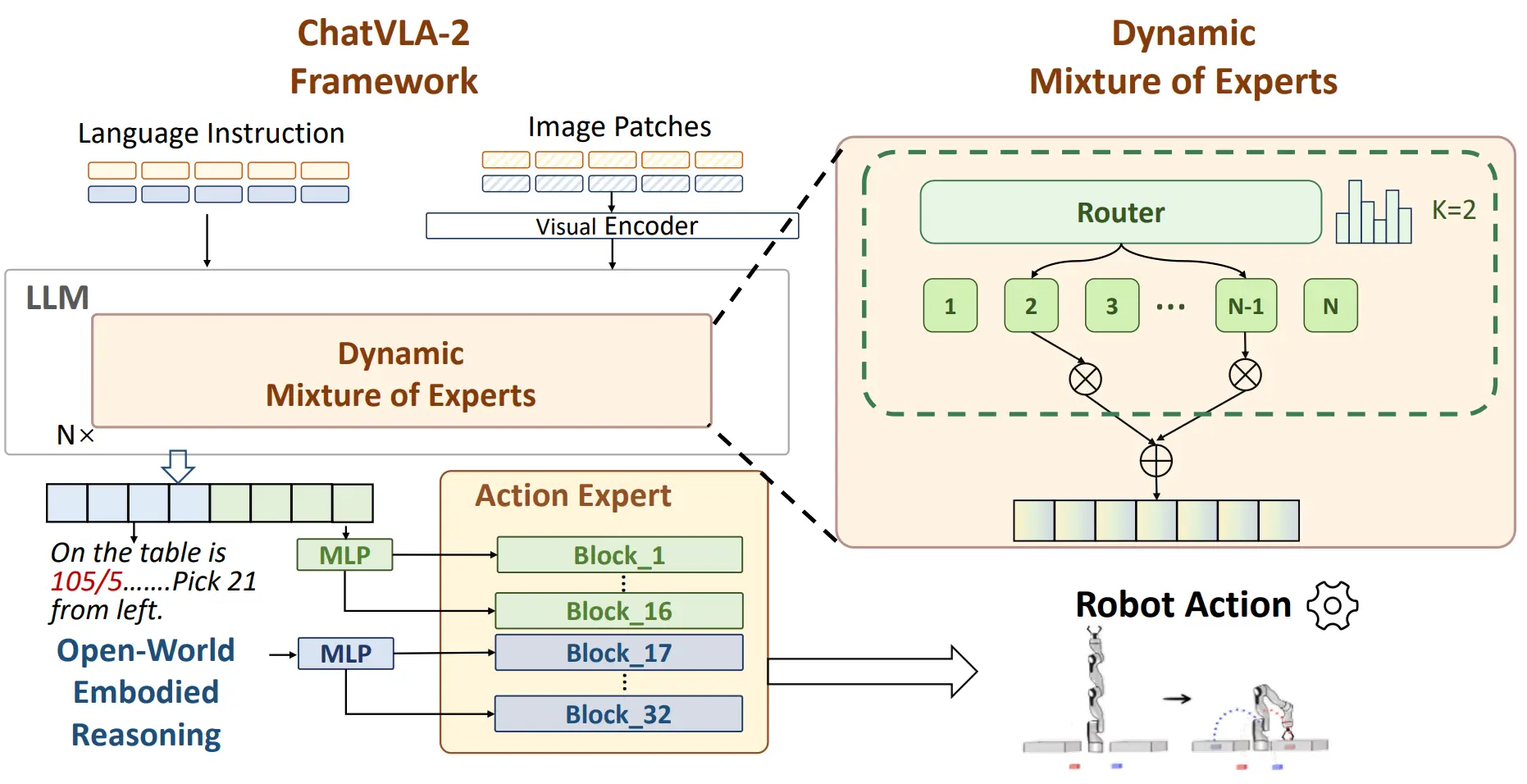
ChatVLA 系列的前作的 MOE 是静态的,也就是根据训练选择激活哪些,这里的 ChatVLA2 使用动态 MOE,也就是由路由网络来选择激活哪些 FFN,并且在后面接了一个 Action Expert。这种选择逐渐显示,学界逐渐都开始发现,不能让 VLM 直接输出 Action,而是应该是双层模型,不然会有很大的代价,即损失 VLM 的通用能力。
ChatVLA2 同时把本来的推理信息作为 condition 嵌入了 Action Expert 中。这次的两个阶段,第一阶段是 co-train,第二阶段 freeze VLM 然后训练 Action Expert。
RoboBrain#
用了两个 LoRA 大量训练的 VLM
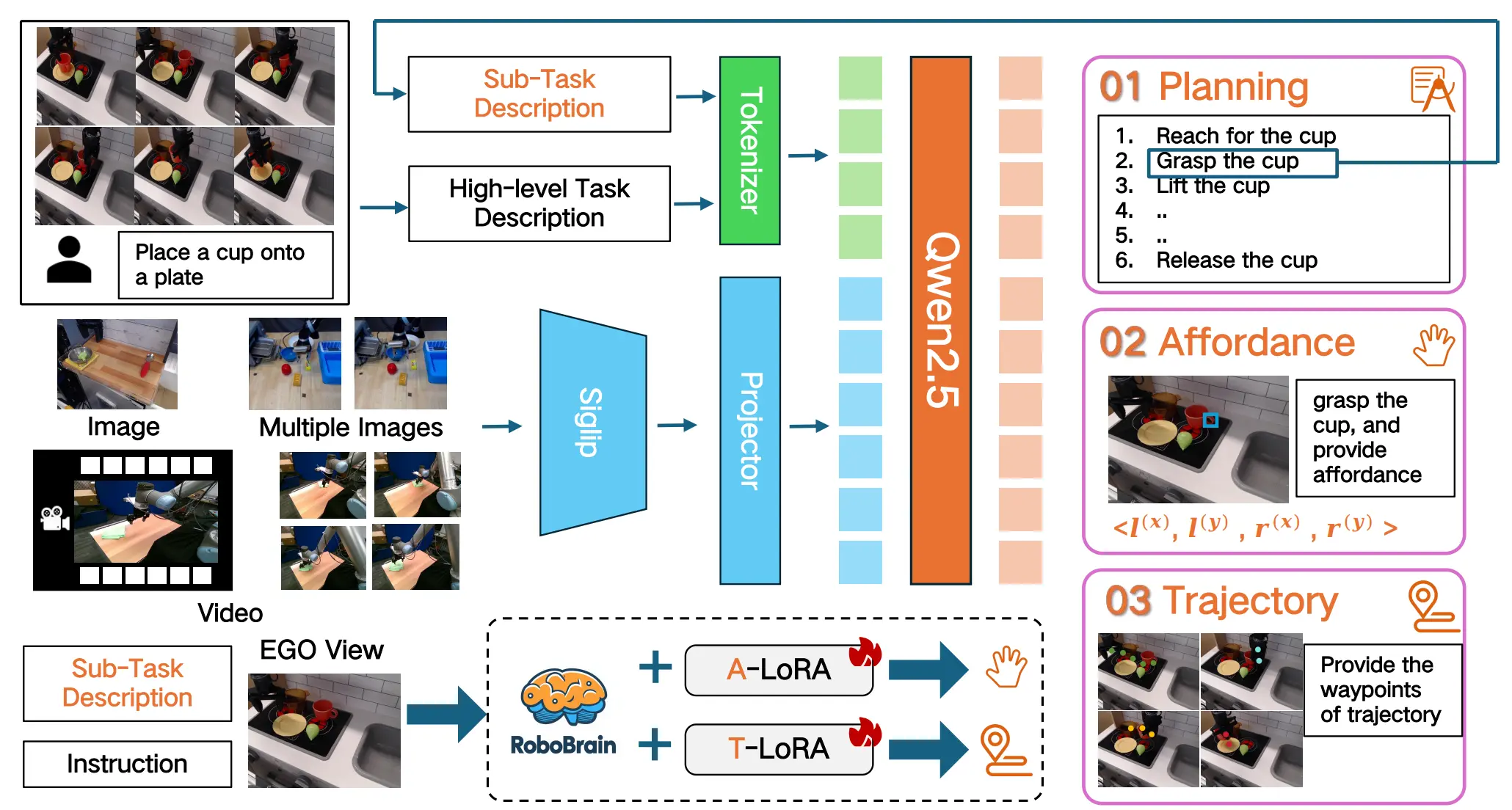
RoboBrain 本质上就是加入了 Planning, Grounding 以及 Trace 数据进行 finetune 的 Qwen,加入了两个 LoRA 分别处理 Grounding 和 Trace 的任务,本身 VLM 可以做 Planning,并且在大量的数据上进行了 Finetune。不过从结果上来看,RoboBrain 本身在 Point affordance 上进行了比较多的 overfit,在一些别的任务上并不是那么的 impressive。
CoT-VLA#
生成图片再用图片作为 Condition 生成动作的 VLA

CoT-VLA 本身还是正常的 VLA 的配置。本身的思路是先生成图片之后再使用图片来作为 condition 来生成动作。
CoT-VLA 的思路看似引入了 World model,可以让模型引入对于动态的认知,使得这个想法确实看上去十分的诱人,但是事实上并非如此。首先其本身使用的是 VILA-U 这一模型,虽然说我对于 Unified 领域并不是那么了解,本身对于语言与文本模态同时在理解与生成进行 alignment 貌似已经存在 trade off,况且还要加入动作,对齐上却没有进行比较多的研究,似乎有些草率了。
Interleave-VLA#
Interleave 输入的 VLA
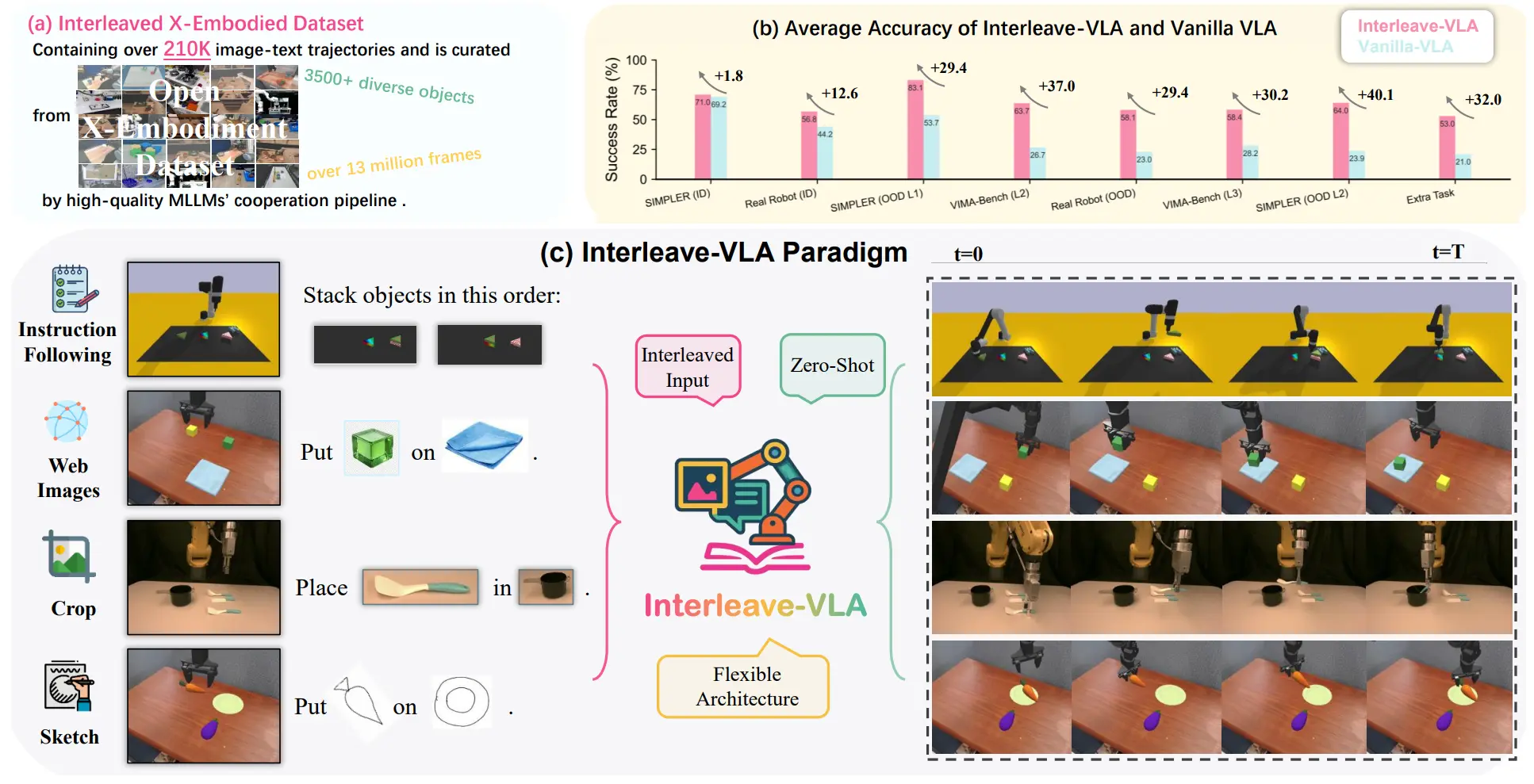
Interleave-VLA 本身就是在 VLA 中沿用了之前 VIMA 的思路,大概的意思就是改成输入为 put <image of apple> on the <image of plate> 的 VLA,从结果上有效果。同时一个有意思的现象也体现在 teaser 中,也可以使用不同形式的文本来作为 condition 输入,除了标准的使用如 SAM2 等流程来进行 crop,还可以以如草图等内容进行输入。
Knowledge Insulating Vision-Language-Action Models#
在 VLM + DP 中禁用梯度回传依然提升性能
Pi0.5-KI 本身是在 Pi0 的基础上进行了一系列的 study。Pi0 在 Pre training 之后的后训练过程中禁用了梯度回传,但是依然提升了性能。Frozen VLM 的做法其实不少的模型都有做过,但是其实很少有 Pi0.5-KI 的效果。这意味着,假如说我们认为 VLM 其中包括的是多任务中的泛化能力,而 DP 中是更多的动作能力,在经过了对于 VLM 使用 FAST 编码后的离散动作进行训练后,在相当恐怖的数量级的预训练之后,Pi0 确实已经具备了非常强大的泛化能力了,使得 VLM 中就已经具有了相当多的 Action 能力,而 Action 能力也开始逐渐像 VLM 汇聚。
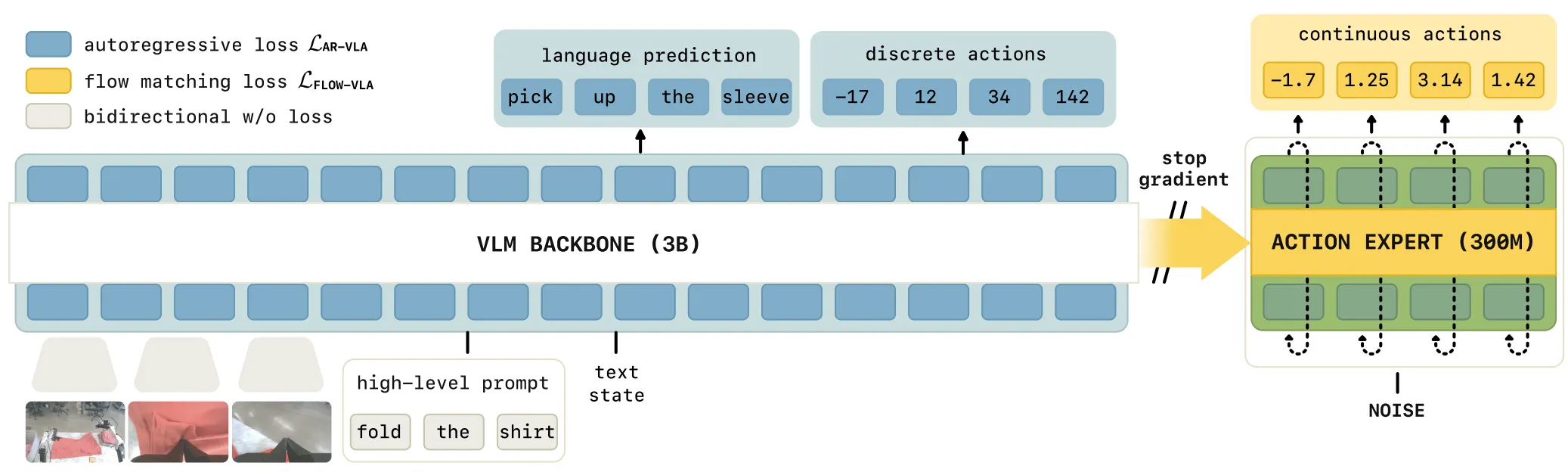
最后简明说一下值得 Highlight 的策略,一方面使用了 FAST 编码器,一方面使用了 Co-training,使用离散 action 以及 VQA 数据训练 VLM,同时使用 DP 来训练 Action,并且禁止 DP 的梯度回传。具体细节推荐读者亲自品读。
Hi Robot#
双系统 VLA

Hi Robot 本身描述了一种双系统的图景,并且做出来了有效的 Demo,不过更多是 infra 方面的设计,并没有过多的训练。简单来说,Hi Robot 也是双系统,其中 System 2 是 VLM,system 1 是 VLA,并且是两个系统同时推理并且可以异步。
论文中有意思的或者可以感兴趣的反而是一些任务的设置或者说认为 system 2 需要具备的能力,假如你也对 system 2 感兴趣,可以参考。同时还包括一些如何设置模型的可供参考,比如说对于 VLM 何时被触发,可以每秒触发一次以及在有语音唤醒的时候触发。在这些方面对于同样的架构来说,target 是什么,可以参考。
Scenethesis#
Image generation + 约束生成 3D 场景
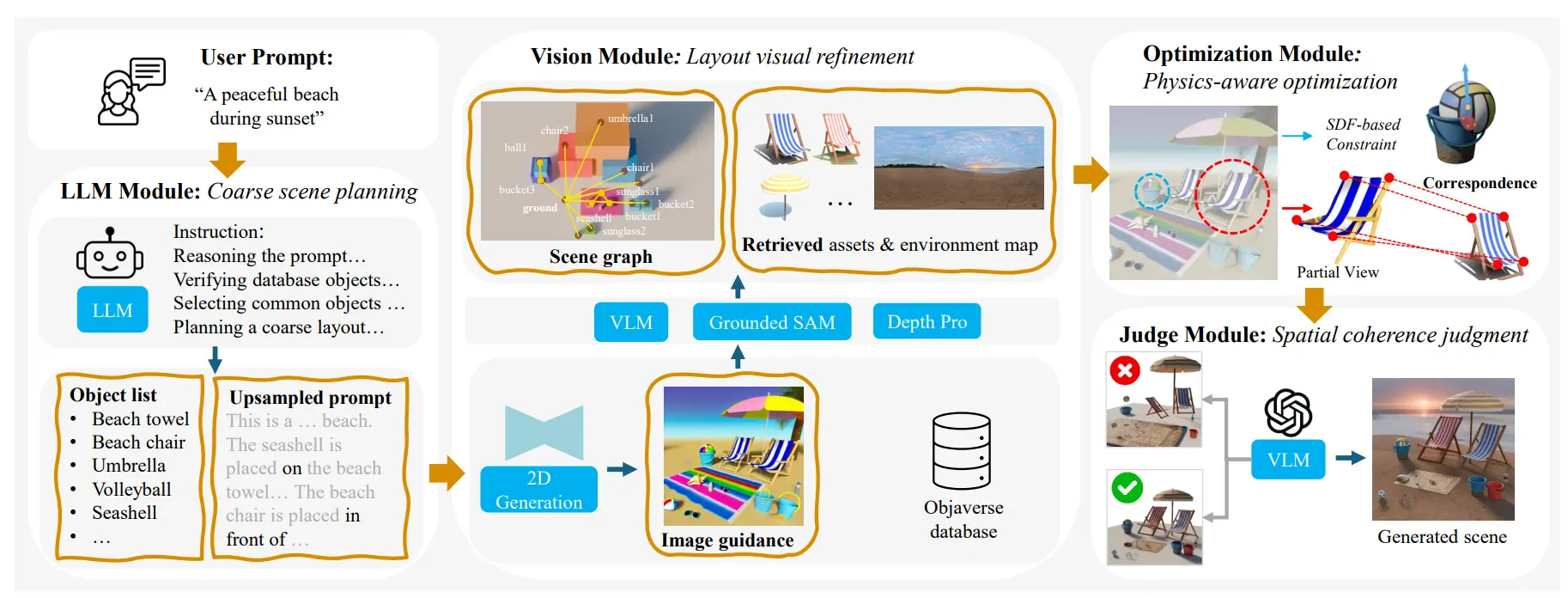
因为具身这及 3D 场景资产,所以 Scenethesis 也勉强算是具身的 scope。本身出自 Nvidia,基本的思路看图就好。
本身的输入是需求,先使用 AIGC 根据需求生成一张图片,之后用 VLM 输出 Scene graph,以及 retrieve 一些 3D 资产,之后进行优化,得到合理的布局。不过因为我觉得这方面本身他们也是在用 Objaverse,甚至 demo 中还出现过我常用的模型,这说明 Objaverse 确实很脏,大家选出来的资产也都大差不差了,同时在资产这方面也没有本质的突破。同时 scene graph 对于 Top 之类的关系的处理也往往不会特别合理。不过从结果上来看,demo 展现的还可以。
LBM#
一个大规模的 pretrain 的 Diffusion based 模型
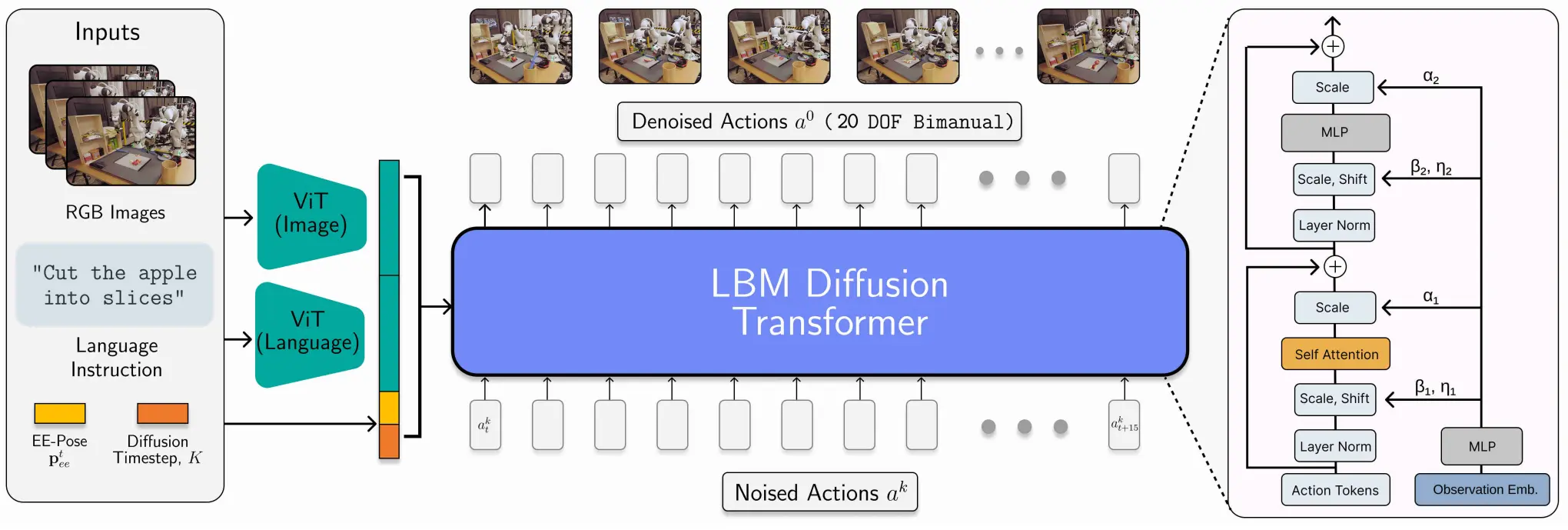
LBM 从效果上来看确实还不错,但是论文实在是有点乱。本质上就是在 DP 的基础上进行了修改,并且评估了大量的 scaling 以及预训练的效果,使用了大量的数据等,从根本的形式上类似于 RDT-1B。建议读者看下他们 网站 里的 demo,非常 impressive。
UniVLA#
更加像是 Uni 的 VLA,使用离散 Token 进行自回归训练
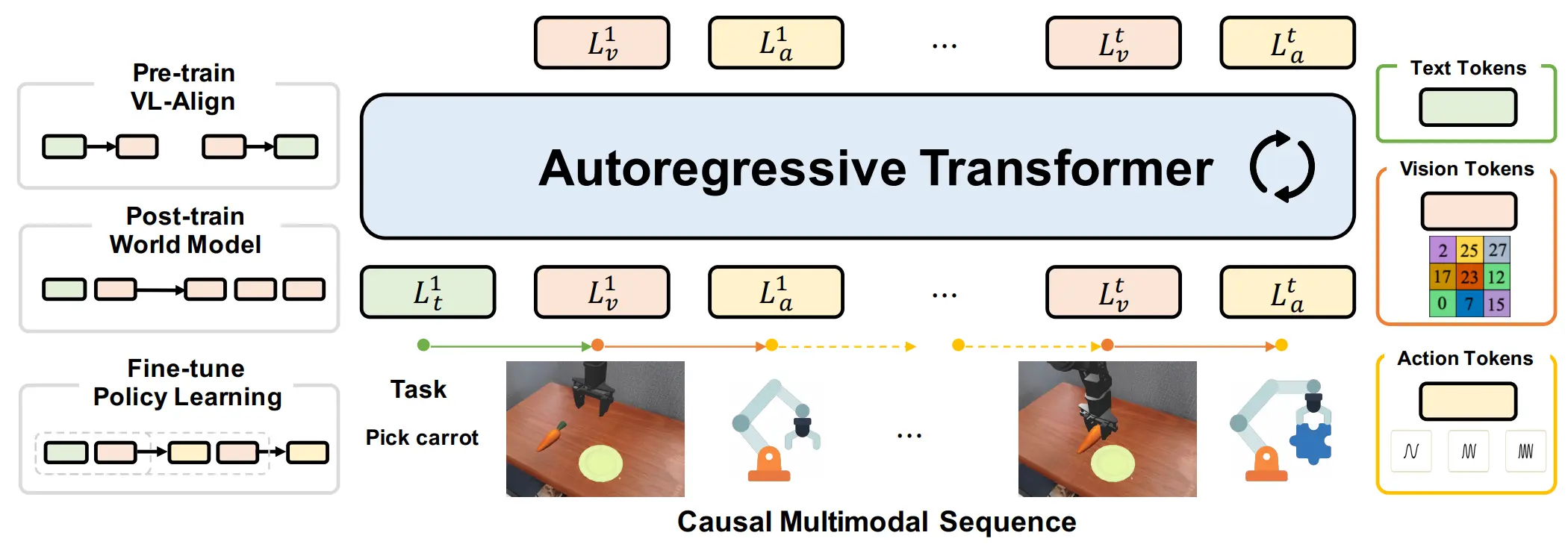
UniVLA 使用 emu3 的 tokenizer 处理文本和图像,用 FAST 处理动作,使用离散 token 进行自回归训练。在输入的时候会使用 boi eoi boa eoa 来标记图像和动作的开始和结束。本身训练用 emu3 初始化之后,先用视频进行后训练,之后再用 Action 数据微调。Action 输出的过程中包括预测 image。将三个不同的模态进行联合训练,这种看上去更加符合 Uni 的思路。
GR-3#
VLM + Action Head 的 VLA
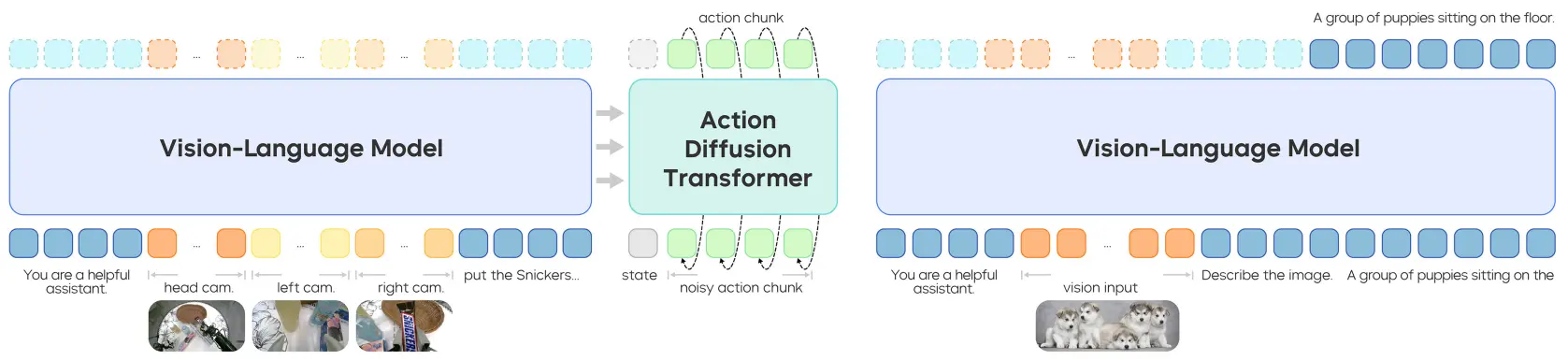
GR-3 本身在 VLM 后面接 Flow Matching 的 Action Head,可以理解为基本上 follow 的 Pi 的架构,因为用了 Qwen,所以看上去效果也还不错。基本上这种 Pi-like 的架构,几乎算是一个主流思路了,毕竟 VLA 一定要借助 VLM 的通用能力,而且不能破坏输入的 distribution,也就只能在 VLM 之后做文章,也就是接入 Action Head。
SmolVLA#
Pi-like VLA,轻量化,异步并行
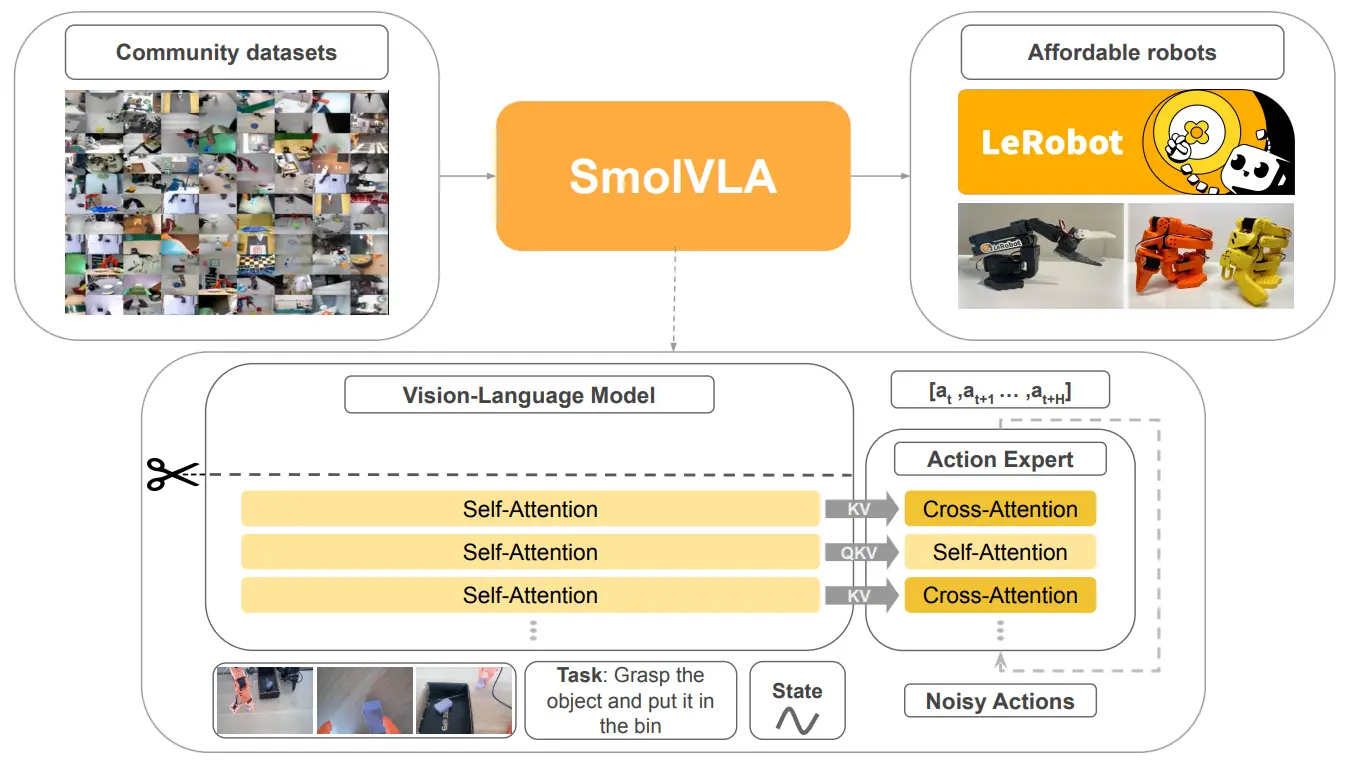
Huggingface 出品,用了社区的大量数据集,说明 LeRobot 的社区生态还是不错的。本身效果看上去也还可以的。细节在于 DP 里面的交错 Attention,交替使用 Cross/Self Attention,可以提升成功率并加速推理,特别是 SA 层有助于生成更加平滑的动作序列。
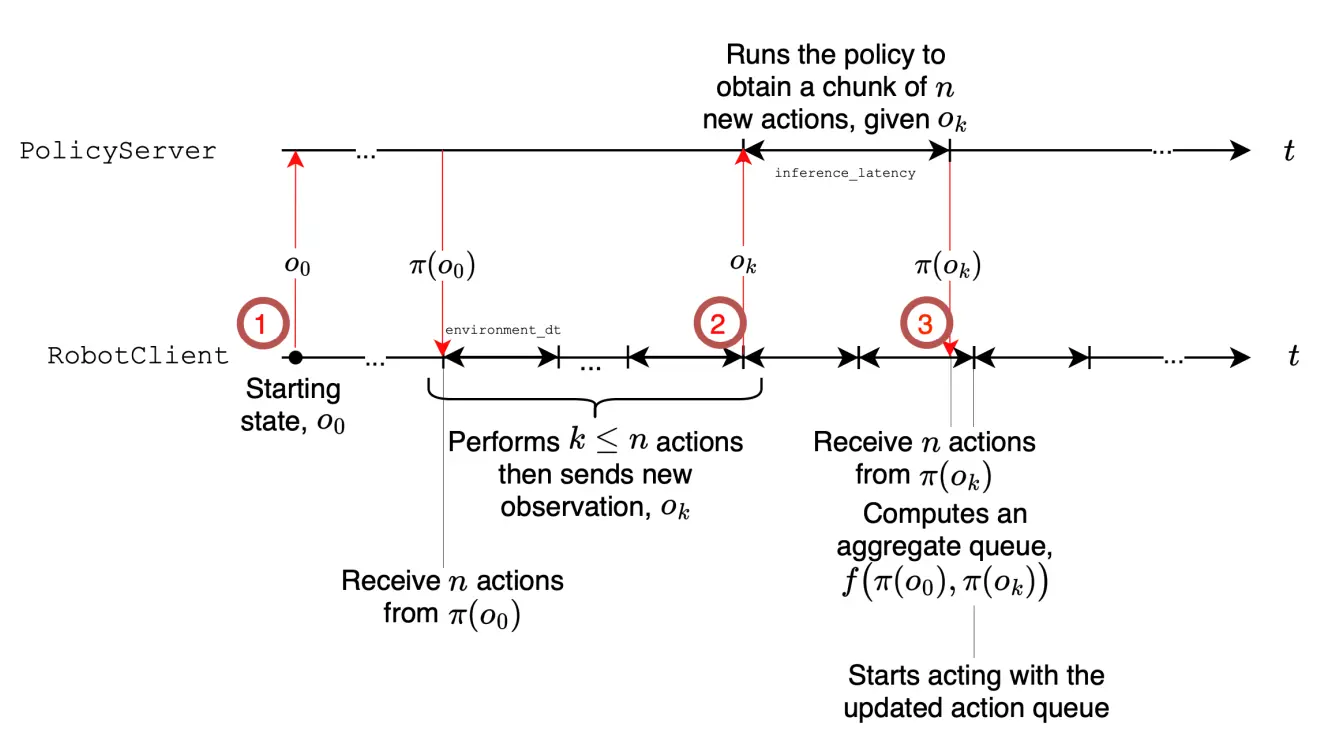
另外一个亮点在于使用了异步并行的方式,可以提升推理速度。大概意思就是,模型推理 n 步,但是执行 k 步之后就让模型推理下一次,可能说推理花了两步对应的时间,之后将新推理的从第二步开始以及旧的里面的从第 k + 2 步开始进行聚合,在旧的用完了之后就完全执行新的。这样子确实可以让 VLA 不再一顿一顿的。
ThinkAct#
Pi-like VLA,对于 VLM 用轨迹奖励函数使用 GRPO
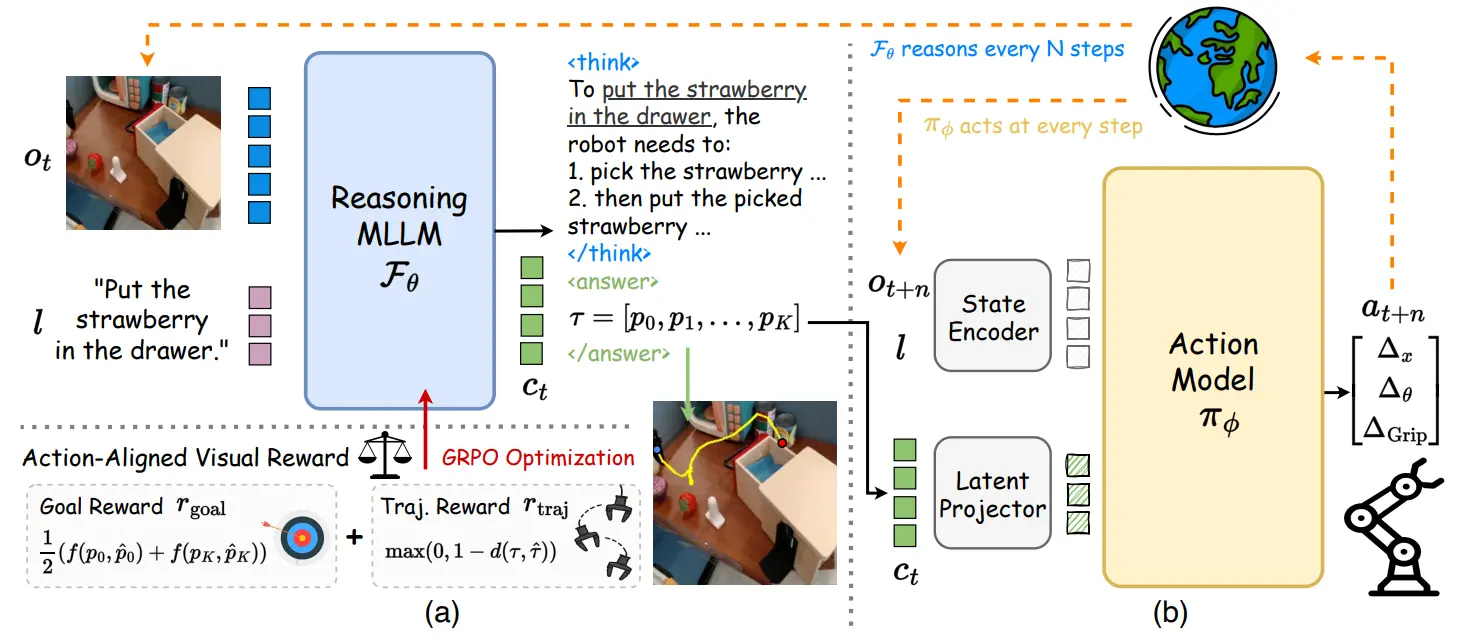
ThinkAct 本身依然是 Pi-like 的架构,VLM 是 Qwen 2.5 7B,Action head 经过 OXE pre-train,然后第一波先用 GRPO 训练 VLM,因为会要求 VLM 输出动作的 2D 轨迹,在此基础上可以计算 Reward。之后 frozen VLM,用 Action 训练 DP。
VIDAR#
World Model + 逆运动学生成动作
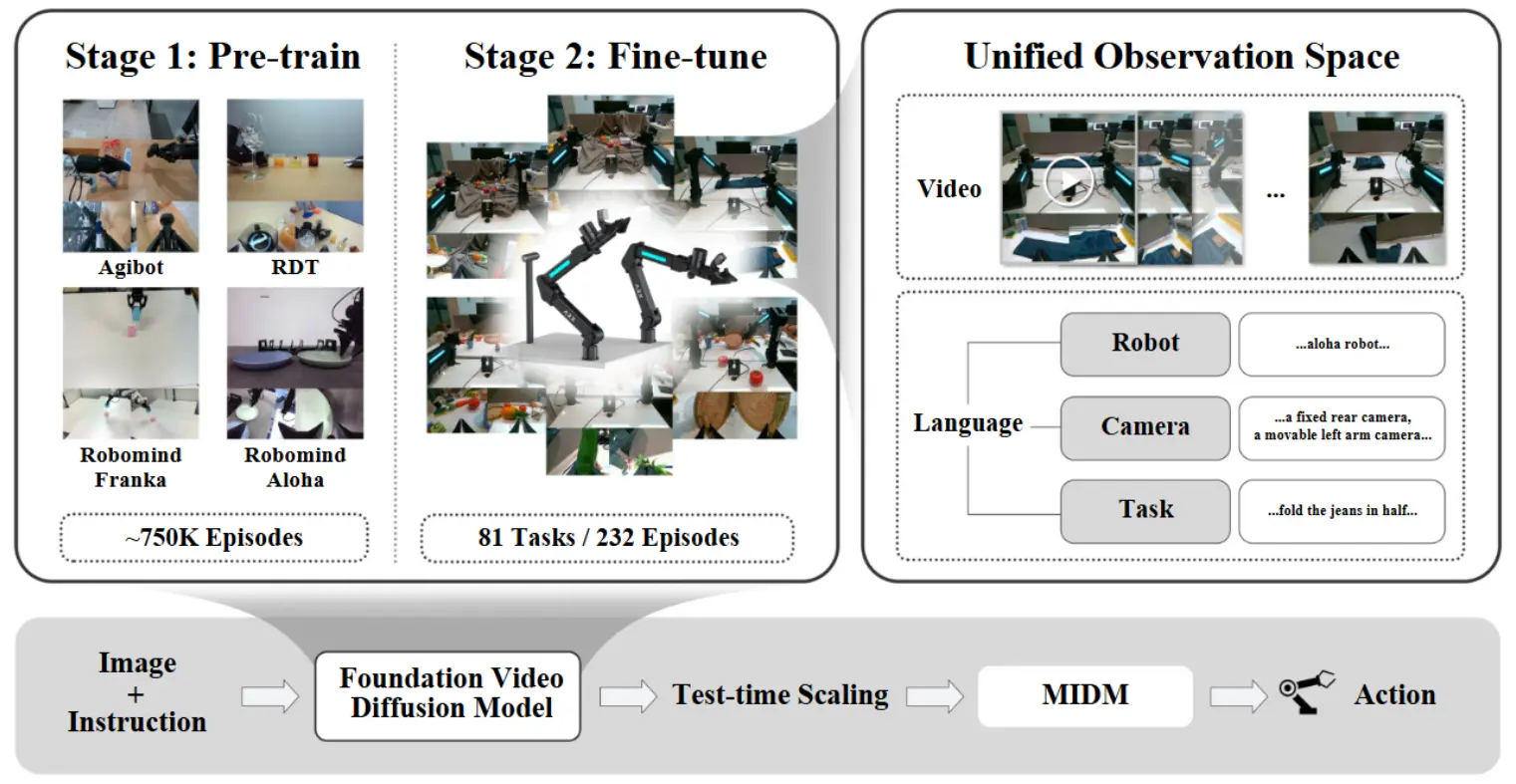
VIDAR 本质上就是 pretrain 了一个 Video 生成模型,然后生成图片。同时另一个模型,也就是图中的 MIDM,大概流程就是先从 Image 学出来一种 hidden 编码,然后 hidden state 去生成 action。本身论文中并没有说很多的细节,因此也很难给出更加细节的理解,不过本身这种做法显然并不是处于第一性原理,使用 Image 作为某种中间表征,必然带来了额外的学习难度,并且表征本身也不能完全 focus 在 action 信息中。
DreamVLA#
预测语义/Depth/动态区域的 World Model + VLA
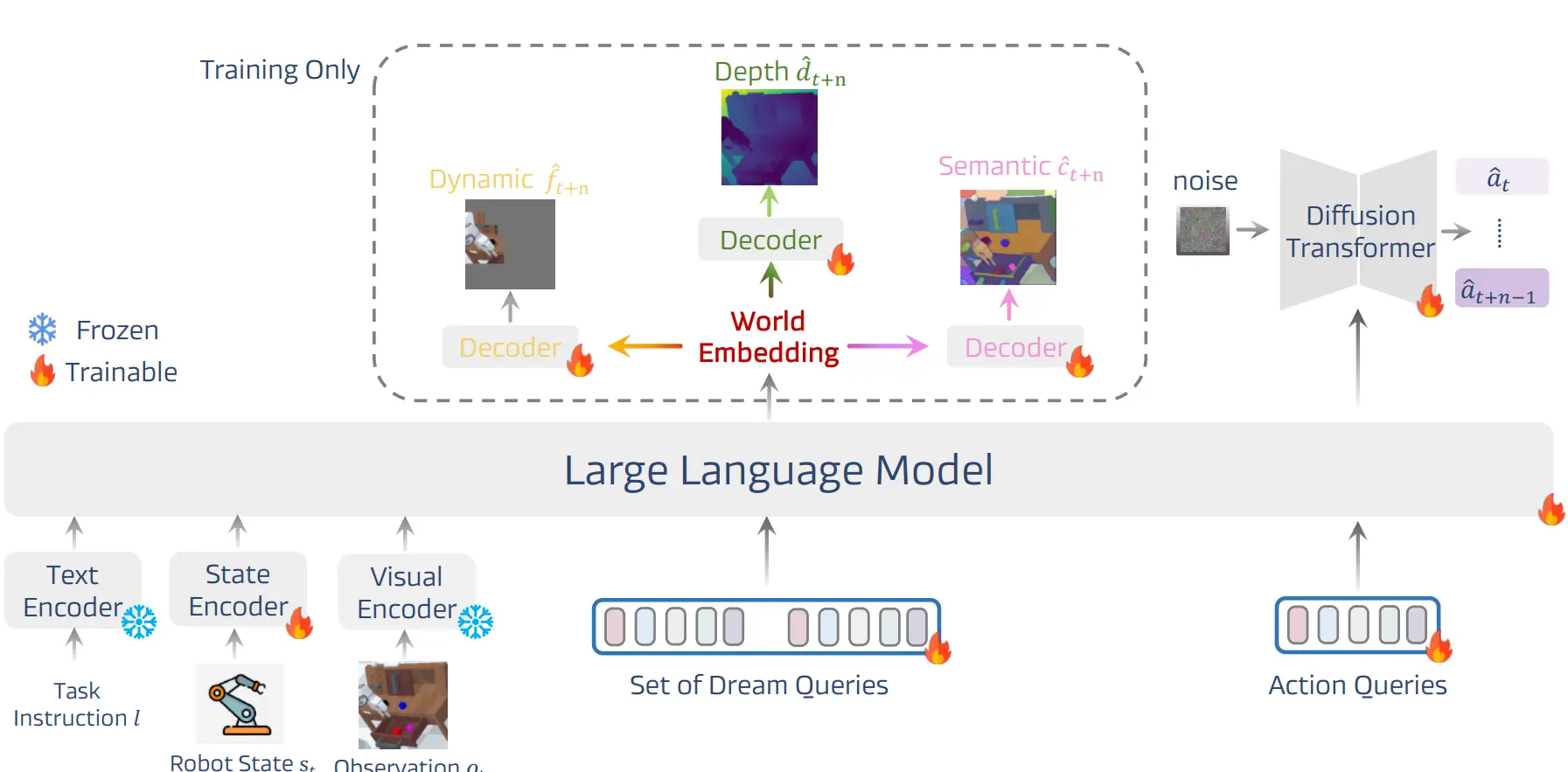
DreamVLA 本身还是很有意思的,预测的是动态区域以及 Depth 和 Semantic Mask,可以说学习了更多的知识。比较神奇的是,居然本身的 Transformer 用的是 GPT-2,可以说基本上都是完全重头预训练了,居然可以训练出来,不知道是否是处于什么考量使用的。本身架构上有可学习的 Set of Dream Queries。对于动作,将包含预测未来动态、深度和语义的潜在嵌入聚合成一个紧凑的动作嵌入,作为 DP 的条件输入。
Pi0.6#
Reward-conditioned SFT 的 Pi-like VLA
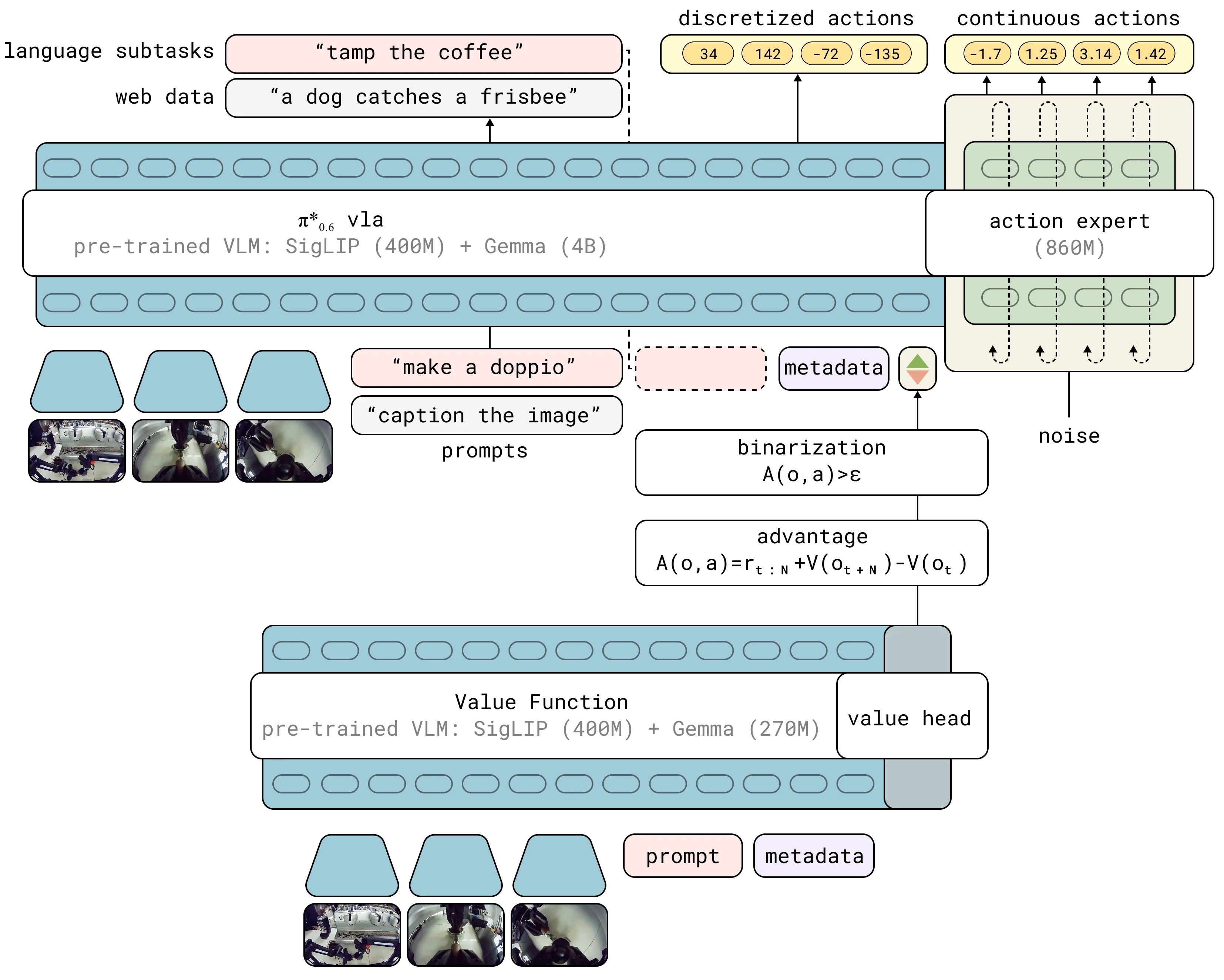
Pi0.6 算是 Pi 系列的新作,主要提出了所谓的 RL 框架,将成功率推上去了不少,算是在为 RL 目标的解决最后一公里做出了一些努力。然而同时有必要强调的是,Pi0.6 本质上并非 RL,而是 Reward-conditioned SFT。简答来说,如图中所示,Pi0.6 基于 VLM 训练了一个 Reward Model,之后使用这个 Reward Model 来对 SFT 的数据进行打标,之后全部的数据无论好坏都用来 SFT,只是模型的输入里面同时包括了 Observation 和 Reward。本身从直觉上理解,可以理解为模型会学习到,输入好的 Reward 的时候要输出好 Action,而输入坏的 Reward 的时候要输出坏 Action,因此在推理的时候将 Reward 写死一个好的常数,就可以有好的效果。论文中有一些内容证明了离散 Action 使用似然,加上 FM Loss,是整体动作似然的一个下界,从而也可以进行 RL 基于动作似然的优化。
从内容上来说,Pi0.6 算是令人满意,但是不如前作更加来的 solid。一些新加入的模块比较有效地让模型的性能提高,同时也在大规模的数据中进行了训练,算是中规中矩的好论文,对于正常 SFT 的模型来说是一个不错的参考,但是确实对于本质那套 online 的真机 RL 来说其实没有很大的参考价值。