
Paper Reading: Embodied AI 2
从一些 Embodied AI 相关工作中扫过。
前言#
Embodied AI 是一个比较新的领域,而且可能横跨的任务也很多,在这方面做的事情来说,可能一些和具身智能具有比较高相关度的 perception 任务,也都会放在其中。
HPT#
使用 Stem Encoder 和 Decoder 对齐 cross-embodiment 并训练一个 Transformer
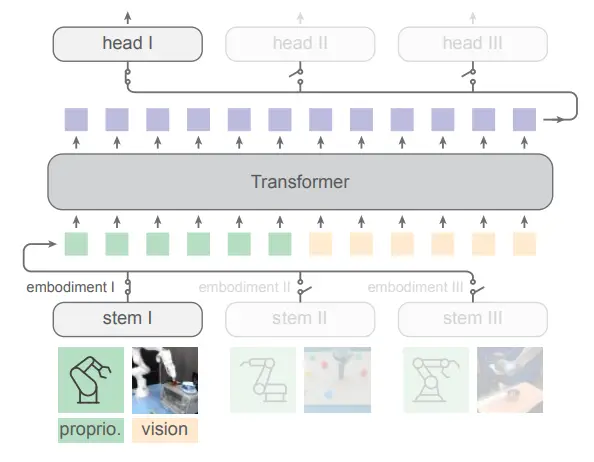
HPT 是 Kaiming He 团队在具身领域的新作,可以说是很直接地解决了 cross-embodiment 任务的问题,也就是使用在多模态领域中一贯使用的 projector 的思想。
HPT 的思想属于是看一眼 Pipeline 图就能看懂的,就是对于不同的机器人,使用不同的 stem 把他们投影到同一个空间中,可以理解为一种机器人任务空间,然后在里面进行 transformer,之后再训练不同的 MLP 来投影回 actions。假如在具有无限多数据的情况下,这种方法确实可以简单有效地进行 scaling up 并且很好地迁移到不同的机器人上,不过令我好奇的是,这种方法居然在此之前没有人提出过。
在此之前的工作中本栏目提到过一篇 Extreme Cross-Embodiment,然而是将不同的模态统一到了动作空间中,类似于无论是移动还是抓取,本质上都是位移以及旋转。HPT 更多还是聚焦在 manipulation 的任务中,直接且本质地给出了这个架构,并且在很多数据上进行了训练。
当然,问题同样存在,在预训练的语境下,使用如此多的 Action,也并没有使用 VQA 进行训练,仅仅是这些数据,依然仅能让模型被限制在预训练后在少量任务上具有不错的性能,而很难进行更高级语义的泛化,Stem 也很难决定将哪些信息 decouple 在 Transformer 中,而哪些会残留在 Stem 中,在更换 Stem 的时候被抛弃掉。
RoboDual#
使用 OpenVLA 以及 DP 组成的快慢系统,DP 用 OpenVLA 的输出作为输入
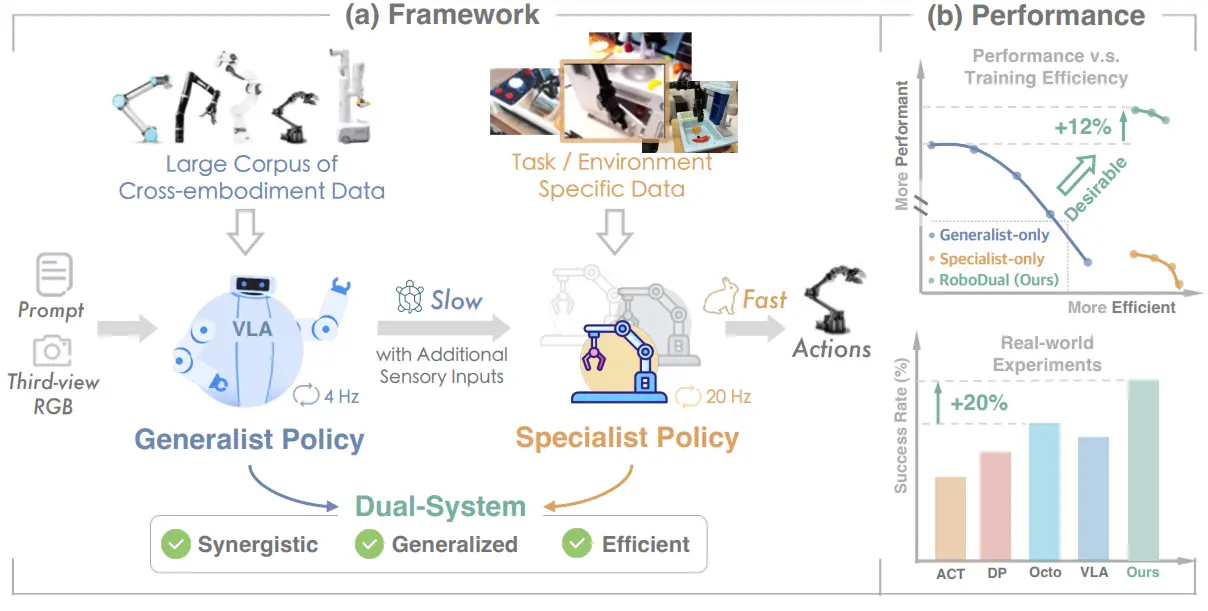
RoboDual 本质上就是使用两个模型的并行运行来代替了单一的模型,用了一个大的 OpenVLA 作为一个 high-level 的模型,之后用 DiT 去做 low-level 的 policy,其中 OpenVLA 的输出作为 conditioned input 给到 DiT 中。乍一看是一个双系统的设计,当然事实上并非如此,可能说顶多是一个快慢系统,毕竟 OpenVLA 本身的输出就已经是离散 Action 了,DiT 最多是在此基础上进行了额外的插值,所以并不是一个真正意义上的双系统。
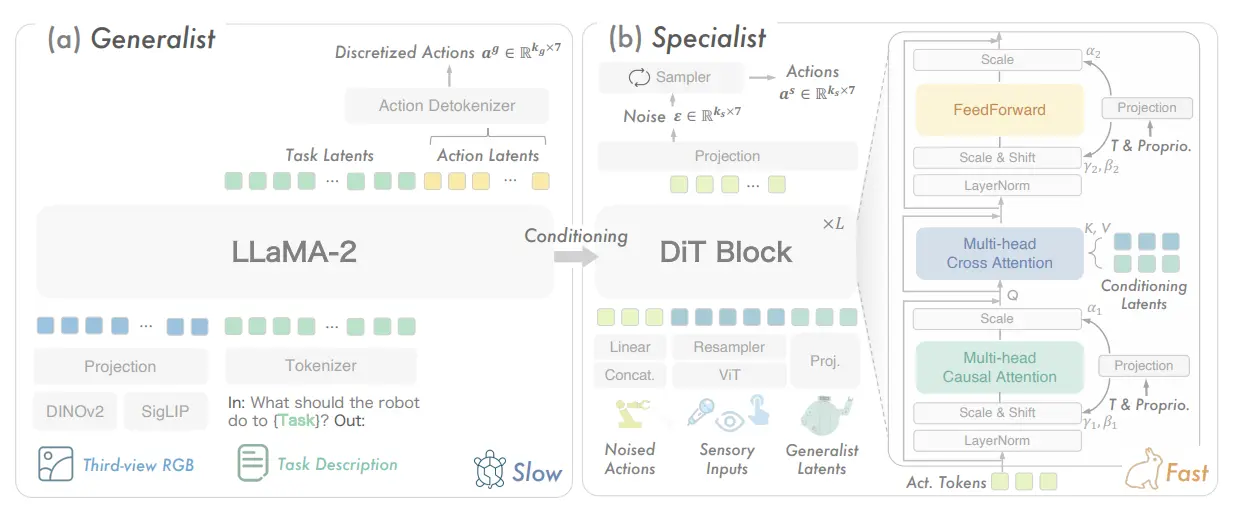
从 pipeline 中也不难看出思想的核心其实就在于把 OpenVLA 的一个 action 扩成了若干的 action,而且 DiT 负责一种扩写,而 OpenVLA 则负责泛化。不过遗憾的是,事实上 DP 的推理速度与 OpenVLA 之间并没有明显的差距,因此可能甚至不成立快慢系统的故事,不过确实包含加速,这其中与 DiT 直接输出 Action Chunk 也是有所关联的。本质上模型的框架其实和后续笔者称之为 Pi-Like,由 TinyVLA 开始的框架是一致的,不过确实从故事线上,确实双系统或者说快慢系统,是一个不错的切入点。
不过当将视线放到 Pi0.5 中,其在 VLM 中也添加了离散动作作为输出,并且下游依然是 Flow Matching 的 DP,可以说也是一种呼应了。
GR-2#
规模更大的 GR-2,展现了泛化能力

GR-2 本质上就是在之前的 GR-1 的基础上的一个拓展性的工作,在更多的数据上进行了预训练以及微调,具体的方法依然不变,还是在大量视频数据里面训练一个 World Model 之后在机器人的数据里面进行动作微调,让模型学会 Action。
Humanoid Manipulation#
对于 DP3 的 scaling up
这篇文章思想本身很直接,就是一篇对于 DP3 的 Scaling up 的论文。

文章里面提出了一种 iDP3,也就是一个 improved 的方法,但是其实就是一些 trick 的集合,在这里也进行一下介绍。第一个就是 camera centric 的 point cloud 输入,这个应该是利好数据预处理的,而且 scaling up 也比较简单;然后就是下采样少一些;以及把视觉编码器的 MLP 变成卷积,这个应该是经验之谈,可以让输出更加平滑,也可以得到更多的编码内容;以及预测更长时间,这个自然会更好。最后从结果来看,Scaling up 的结果很好,皆大欢喜。
Surfer#
使用 World Model 的 VLA 模型
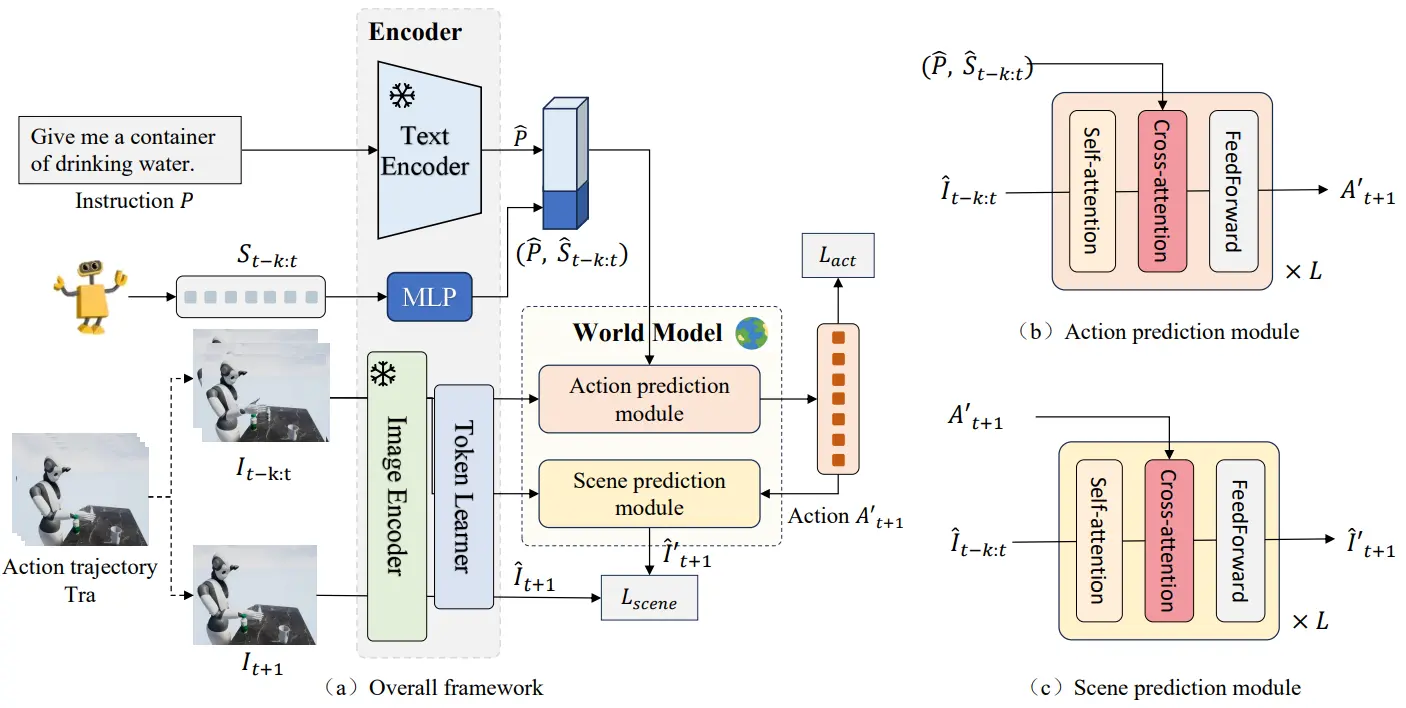
Surfer 主要提出了一个 World Model,本身就是拿了两个现成的 Encoder 把任务以及图像进行了编码,然后预测下一次的 action 以及 frame。
不过从 pipeline 来看,我其实确实不是很确定这个 next frame prediction 是否有效果。隔了一个网络然后来传梯度给 Action prediction module,本身是串行的,等于说加了一个模块以增加额外约束,这种方法肯定符合直觉,但是肯定拓展性以及潜力有限。
监督信号还是本身加在输出 action 的模型本身会好,这种可以说是一种增加监督的 trick,但是不一定在更大规模的 scaling 中好用,毕竟效率不高,增加了一个开销很大的模型。
ACT#
CVAE style 的模型,使用 Transformer 作为 encoder,DETR like 的结构作为 decoder
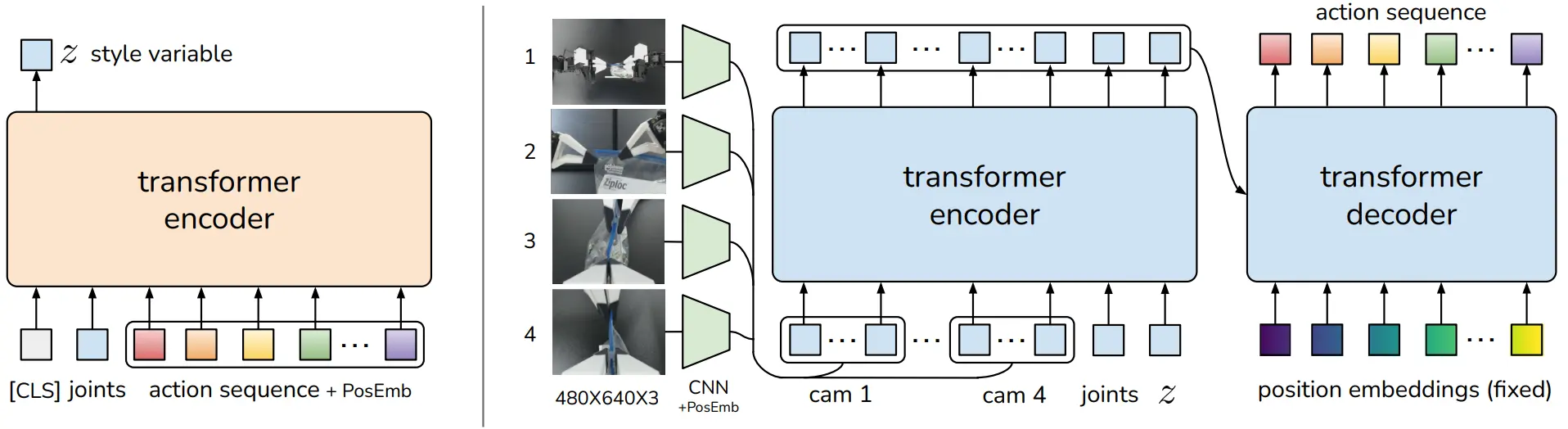
ACT 是十分经典的论文了,使用了 CVAE 的结构来运行。按照说法,CVAE 也就是 conditional VAE,使用了 VAE,并且使用图像 + joint position 作为解码器的输入。由于我没有看过 CVAE,但是大概猜测 conditional 在这个里面其实指的是 image 以及 joint position 在解码器的输入,而至于任务本身,就是重建输入到编码器里面的 action。
本身论文里面有很多的细节,包括说在 VAE 编码器的时候只使用 joint position 以及在训练的时候使用 L1 损失而非 L2,在这里就不进行展开了。
解码器的结构神似 DETR,包含一个编码器以及一个解码器,不过有必要指出的是,这里其实等于说一共有两个编码器,VAE 本身还有一个。ACT 可以说是比较优雅的 VAE 范式的解决方法,但是不得不说的是,VAE 甚至是传统 diffusion 的策略在当下来看都已经过时了,这种策略可能难以作为一个可以大量 scaling up 的一个策略存在。以及其实 ACT 并不是 language-conditioned 的模型。
SceneVerse#
一个 3D Scene 的数据集以及对应的 Caption Model
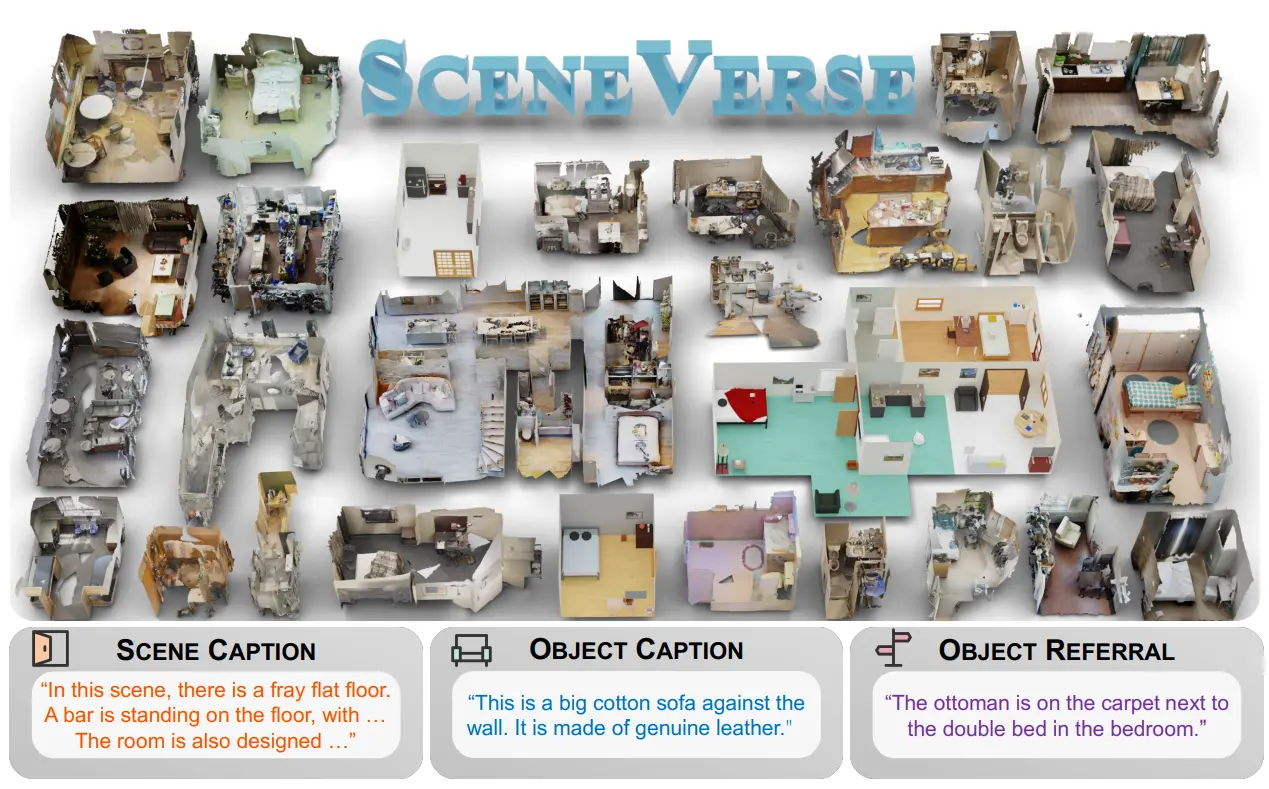
这篇工作做了一个大型的数据集,里面的全部的 scene 应该以扫描出来的为主,然后使用了不同 level 的标注,这是比较有参考价值的。也就是 Scene Level 的标注,比如说「这是一个有床和衣柜的卧室」,以及一个 object level 的标注,比如说「床」,「衣柜」,以及一个 object ref 的标注,也就是物品之间的关系,比如说「床在衣柜的左边」。其里面提出的 Scene Graph 还是很有效地可以用于表示场景中的相对关系的。
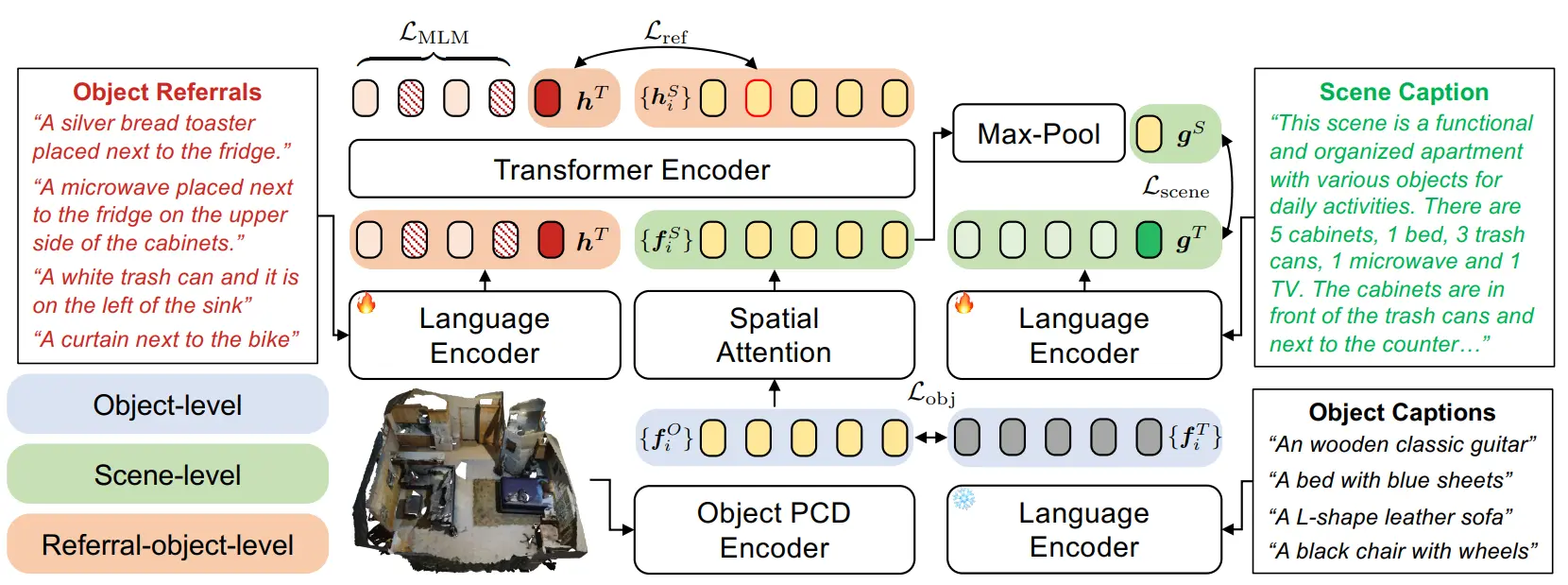
SceneVerse 同时提出了一个模型,这个图应该是画的比较好看,但是不太容易看懂。本身包括一个 PCD Encoder,以及一个 Text Encoder,之后使用一个 Transformer 进行编码,建立了四个损失,也都算是 MLLM 的比较经典设计。
一个是 ALEBF 的损失,这里面叫 ,在输入到 Transformer 之前,使用一个 MLP 来预测 object 的 3D 坐标,对齐 PCD Encoder 以及 Text Encoder 的输出。然后这里面多了一个 Spatial Attention,其实就是把 Object 的空间信息编码了一下,之后才和 Text Encoder 的信息一起输入到 Transformer 中。然后就是一个 ,以及 Transformer 之后把 PCD 和 Text 进行对齐的 。最后还有一个过了 Spatial Attention 的 。可以说各种地方都加了各种的损失。
是让 PCD Encoder 包含 Object 全部的表征, 确保 Spatial Attention 的输出和 Scene Level 的标注一致,也就是 Spatial 之后真的编码出了这个场景, 和 则是保证 Fusion 之后的信息的准确性。中规中矩,十分合理。
Robot See Robot Do#
生成 Articulated Object 的 3D 模型并生成 Demonstration 的流程

Robot See Robot Do 算是比较袖珍的 Real2Sim2Real 的流程,精致的工程的工作。简单来说,这篇的方法就是先生成 Mesh,然后进行拆分。根据人工的 Demonstration 中的动作来分析不同的部分的运动方向(比如说看到 Demonstration 中一直让一个盖子绕着某个轴旋转,那么就认为这个盖子是绕着这个轴旋转的),同时通过人工的手的位置来获得双臂机器人的爪子的放置位置,再然后就是常规的求解了。

这其中的细节还是比较多的,使用 DINO 以及 Depth 在整个视频中的输出,作为监督,约束 State 通过第一帧表征的部件。第一阶段最后的保存形式称之为 4D-可微分部件模型,这个名字比较直观,也就是将物品按照部件保存,以及对应的 Action 动作。
在部署阶段,因为上述的数据是以物体为中心的,也就是所谓的 object centric,因此可以跨 embodiment 进行部署。本身就是解析物品的姿态,恢复到录制时候的姿态,然后执行动作即可。
可以说这种论文看上去都是十分的优雅,给出了一种看上去逻辑自洽的解法,但是实在是并不具备泛化性,而且可以预见的是,其部署也不是十分的方便,仅作为参考还是可以的。不过搭建这种工程作为小的 research 也是有趣的体验,也是一种格外精致的优雅。
ReKep#
使用不同点之间的约束来生成 Action 的 Prompt-based 方法
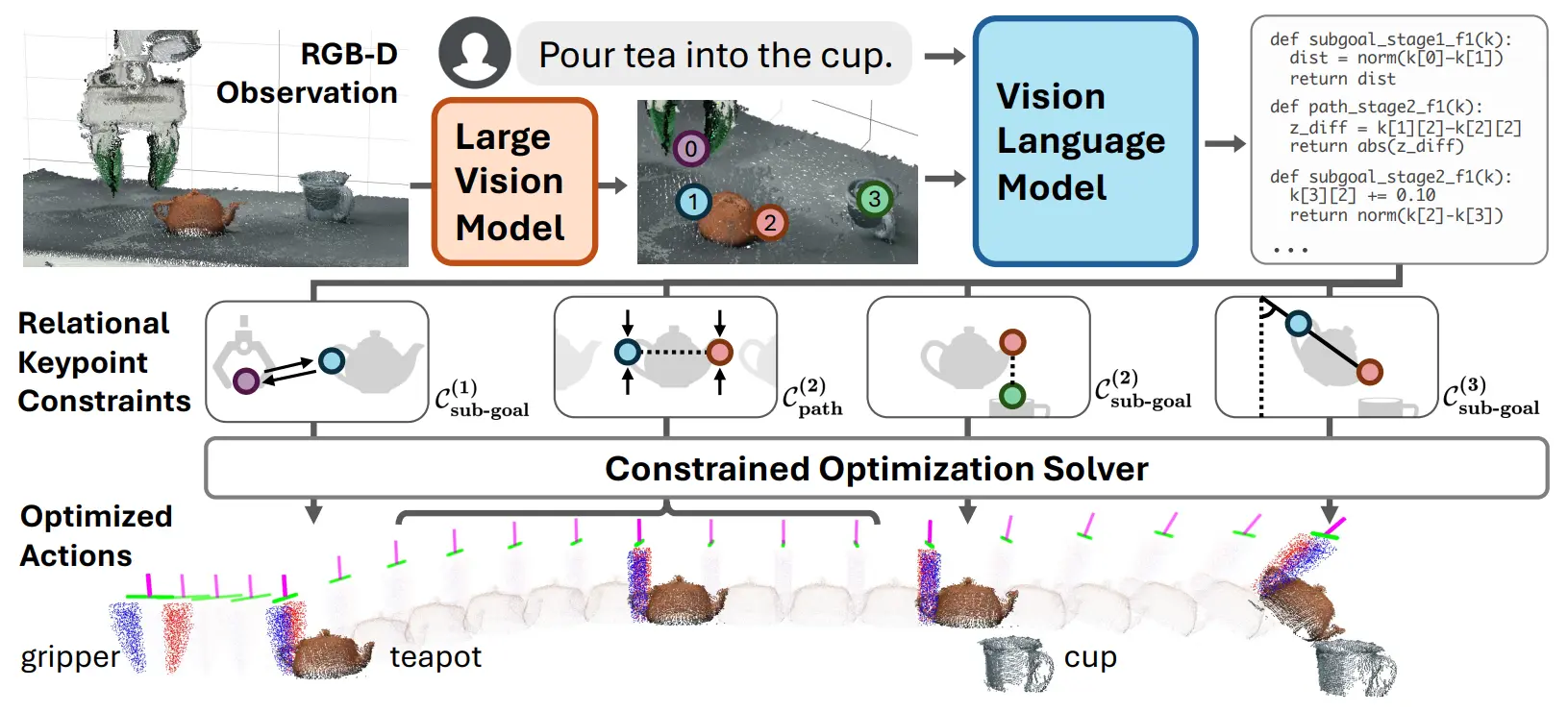
ReKep 的思路其实很直接,或者说大多数的 Prompt-based 方法都很直接,本身就是建立了一系列的点约束。比如说我现在有两个点是在一个盘子的两端,那么我约束这两个点的 z 的差等于 0,也就等价于让这个盘子平放了。
本身的 Pipeline 就是使用 VLM 标点,VLM 生成点约束,生成约束下的 Pose,生成约束下的不同 Pose 之间的 Path。通过这四个环节,就可以生成一个动作序列了。
本身这篇其实其程度和 CoPa 比较像,属于一个比较具有细粒度而且比较自由的方法,相较于 CoPa 使用向量、面等约束,两个点毕竟也能表示向量,其可实现性还更强,也具有泛化性。看上去还是很不错的,加上其中使用的工具很多(其附录中的内容),代码应该具有参考性。
OmniManip#
一种集百家之长的 Prompt-based 方法
之前已经介绍过了 ViLA, CoPa 以及 ReKep,这一篇可以说是集百家之长。
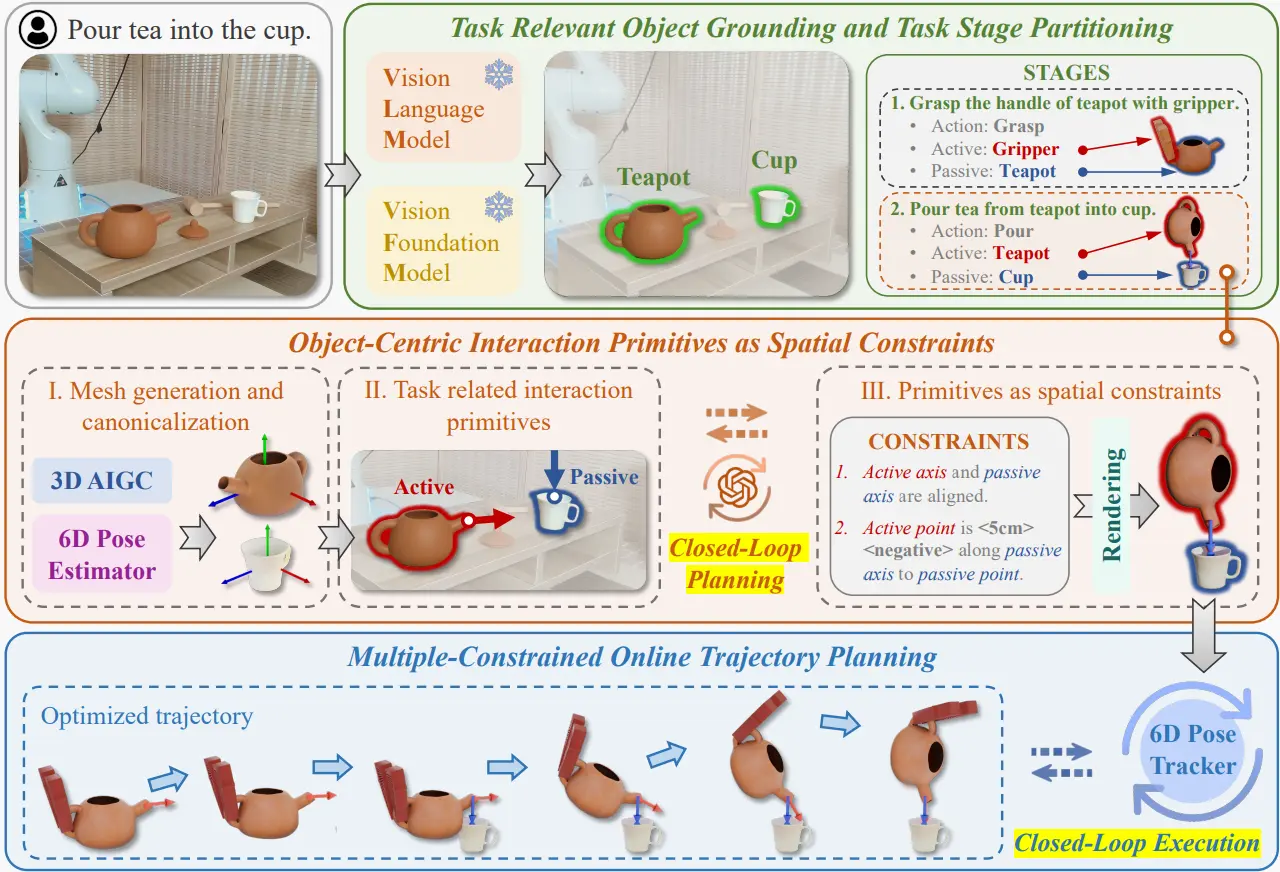
事实上从 Pipeline 的图也就可以看出来了,首先是一个大的 ViLA,包括拆分以及闭环(事实上这并非 ViLA 独有,方便理解这样说罢了),然后是一个 CoPa 的向量的约束生成,并且用这种约束的描述来生成动作,最后是一个 Optimized trajectory 的生成,这部分也和 ReKep 的思路比较像。
尽管看上去有点缝合怪,但是还是用到了他们组拿手的 6D Pose Estimator,并且同时还引入了最近比较火的 3D AIGC,可以说是很全面了。在其他领域,为了显示 novelty,大多数工作都会刻意不使用那些有效但是并非基石的方法,而转而使用自己的模型,然而 Robotics 暂时还是需要在有效性以及鲁棒性上进行进一步的探索,具有强大的 Prompt-based 方法,具有强大的数据生成能力,从而具有大量的数据,才能再谈其他。这一篇可以说通过集百家之长,验证了之前种种方法的有效性,并且获得了相当不错的效果。
DiffuserLite#
Corse to Fine 的 Diffusion 模型
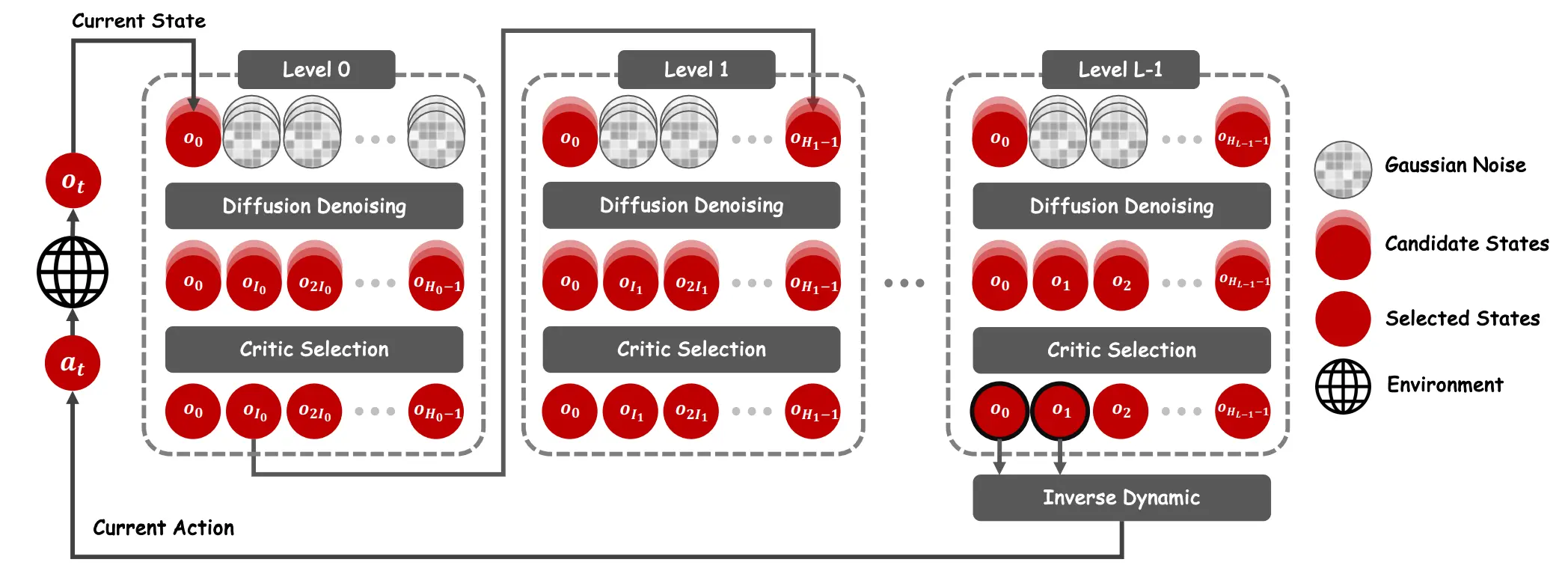
这一篇的核心思想其实和 Diffusion 关系不大,主要还是 corse to fine 的思想,使用模型生成一个粗粒度的动作预测,然后将其中前两个动作作为下一次预测的首尾,进一步预测。
举例来说,比如第一次预测 1, 8, 64, 512,第二次可以预测 1, 2, 4, 8,将第一次的 1, 8 作为condition。这种 corse-to-fine 的方法,还是很容易被理解的,多轮的优化对于精细的操作还是有好处的。不过对于论文中提到的效率优化,我对此表示怀疑。
本身其实这篇做的很早,但是和后续在 T2I 领域的 VAR 有着微弱的联系,在将来也可能被整合到更多的 VLA 之中。只是实验确实也并不 solid,只能说十分一般。
SOFAR#
训练了 3D 感知模块的 Prompt-based 方法,提出了大量的资产

SOFAR 的工作量还是很大的。首先是提出了一个标注的数据集,叫做 OrienText300K,这个数据集是一个基于 Objaverse 的数据集,使用 VLM 进行了一些三维标注,然后使用这个数据集训练了一个叫做 PointSO 的方向标注模型,类似一种 Affordance 的标注模型,输入文本就可以输出向量。接下来用这个模型进行了一个类似于 CoPA 一样的 Prompt-based 的方法,也就是 SOFAR。
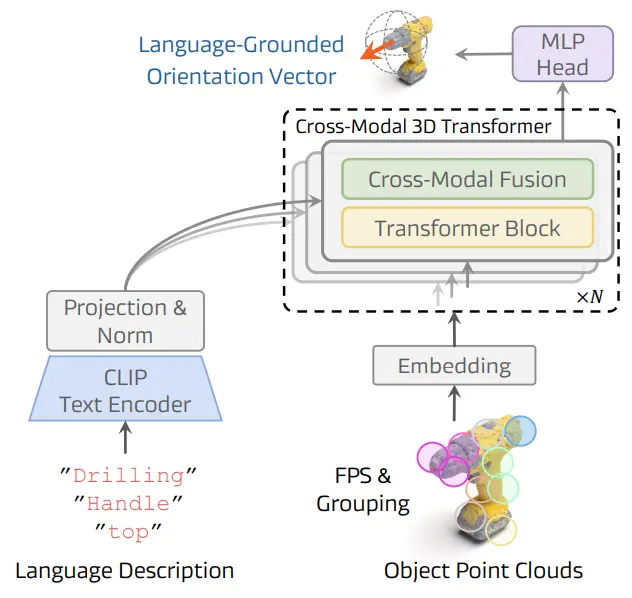
本质上 PointSO 的效果就是给你一组点云,并且说出来自己想要标注什么(比如说把手),然后 PointSO 会给你标注出这个内容的一个向量。而其结构本身就是比较经典的多模态的一个 Transformer 的结构。

SOFAR 的流程如图中所示,本身 affordance 由 GPT 分析,然后交给 PointSO 进行标注,之后回到 GPT 里面去进一步分析,给出始末位置,之后直接生成动作,感觉是可行的。
同时很吸引人的一点在于,这个模型确实做了大量的实验,本身工作是 Galbot 的,只能说工业界的积累确实足,大量的在 OXE 训练过的模型,确实不一般。
PIVOT-R#
Surfer 的后续工作,使用异步多模型进行任务拆解、场景预测、动作预测
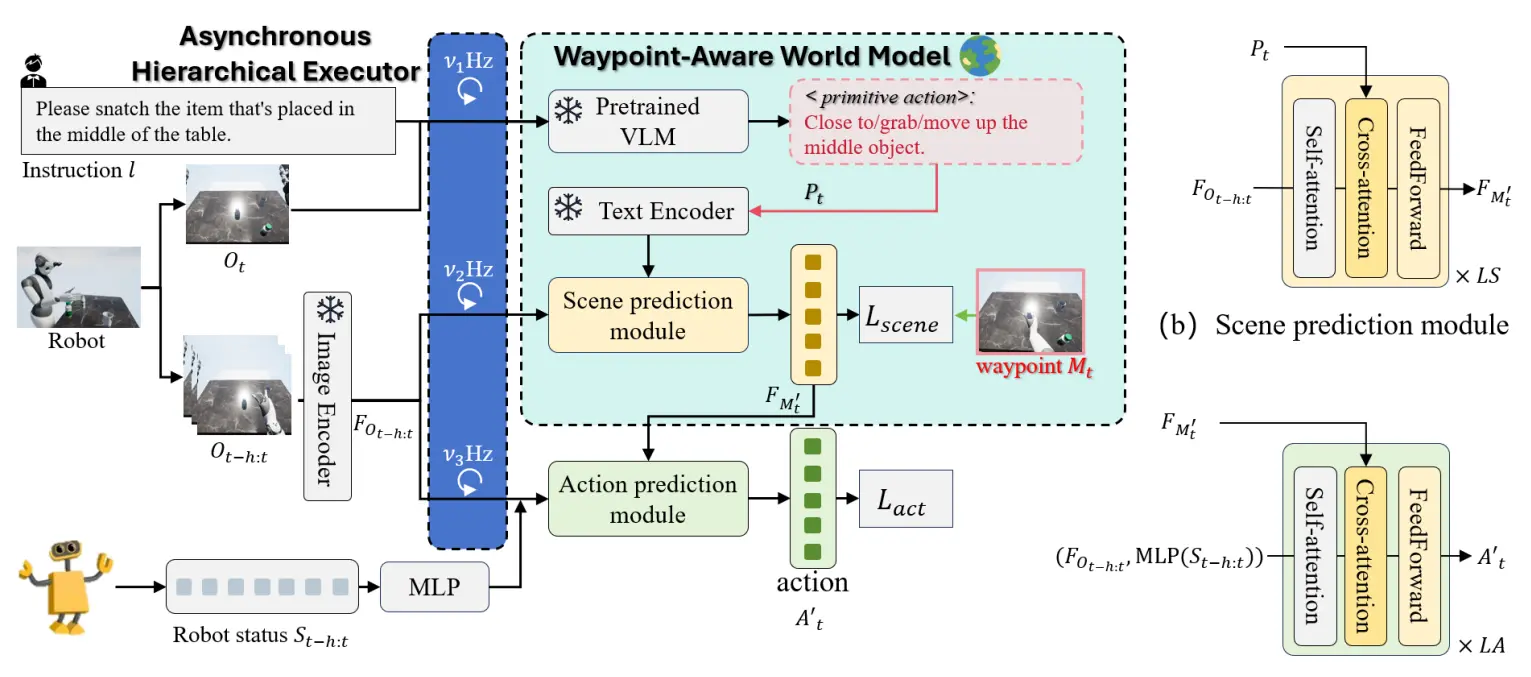
PIVOT-R 的画图一眼就似曾相识了,果然是 Surfer 的后续工作。
直接在宏观上 Diff 一下,一个是引入了异步的机制,本身的三个模块,任务拆解、场景预测、动作预测,都是异步的,可以用不同的速度来运行。可以想到的是任务拆解最慢,场景预测其次,动作预测最快,符合直觉。另一个不同点则在于相比起之前将 action 预测的 token 喂给场景预测,这一次将场景预测的输出喂给了动作预测,可以说是终于符合直觉了,毕竟这是一个动作预测,而不是一个图像生成模型。
不过鉴于 PIVOT-R 依然是一个传统的 Policy 模型,整体的结构依然是比较复杂,三个异步的模型,确实没有什么可以参考的点。
ManipGen#
蒸馏 RL Expert 作为 Policy 并使用 VLM 进行 Long Horizon 的任务执行
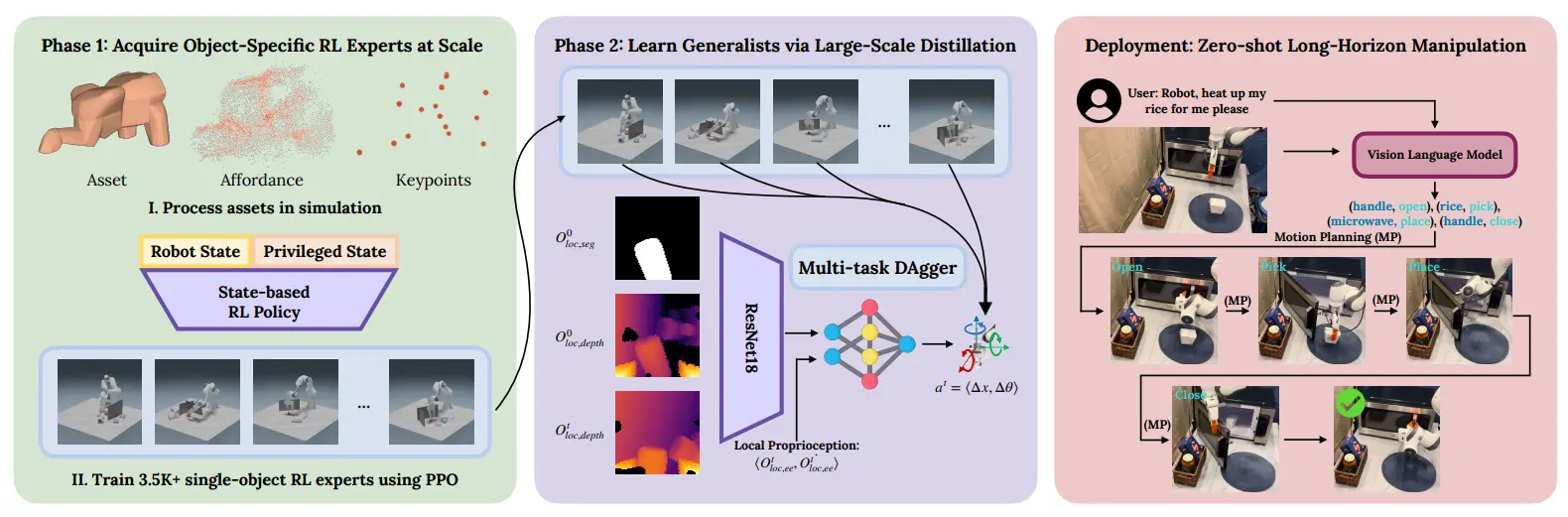
ManipGen 基本上可以说是一图以蔽之。首先在仿真中训练了一堆的 RL Experts,然后都蒸馏到一个模型里面,这里面值得一提的是一个经典的 Sim2Real 方法,就是使用 SegMask/Depth 等作为中间表征。这种思想的本质上都是认为 Sim2Real 的最大 Gap 在于视觉区别,而当中间表征作为输入的时候,这种 Gap 自然也就降低了,因此也就可以更好地进行 Transfer 了。
ManipGen 使用大量的 RL 进行整合,理论上还是 scalable 的,不过是在是仿真在 Manipulation 中依然是由 Limitations 的,生成更多的任务也是困难的。在这里简单为不知道的读者提一下 DAgger,也就是 Data Aggregation 的思路,说白了就是不止使用 Ground Truth 来进行监督,同时也通过一些专家的策略来生成数据,然后训练模型。这种思路也是比较常见的。
DemoGen#
使用 Replay 进行数据生成
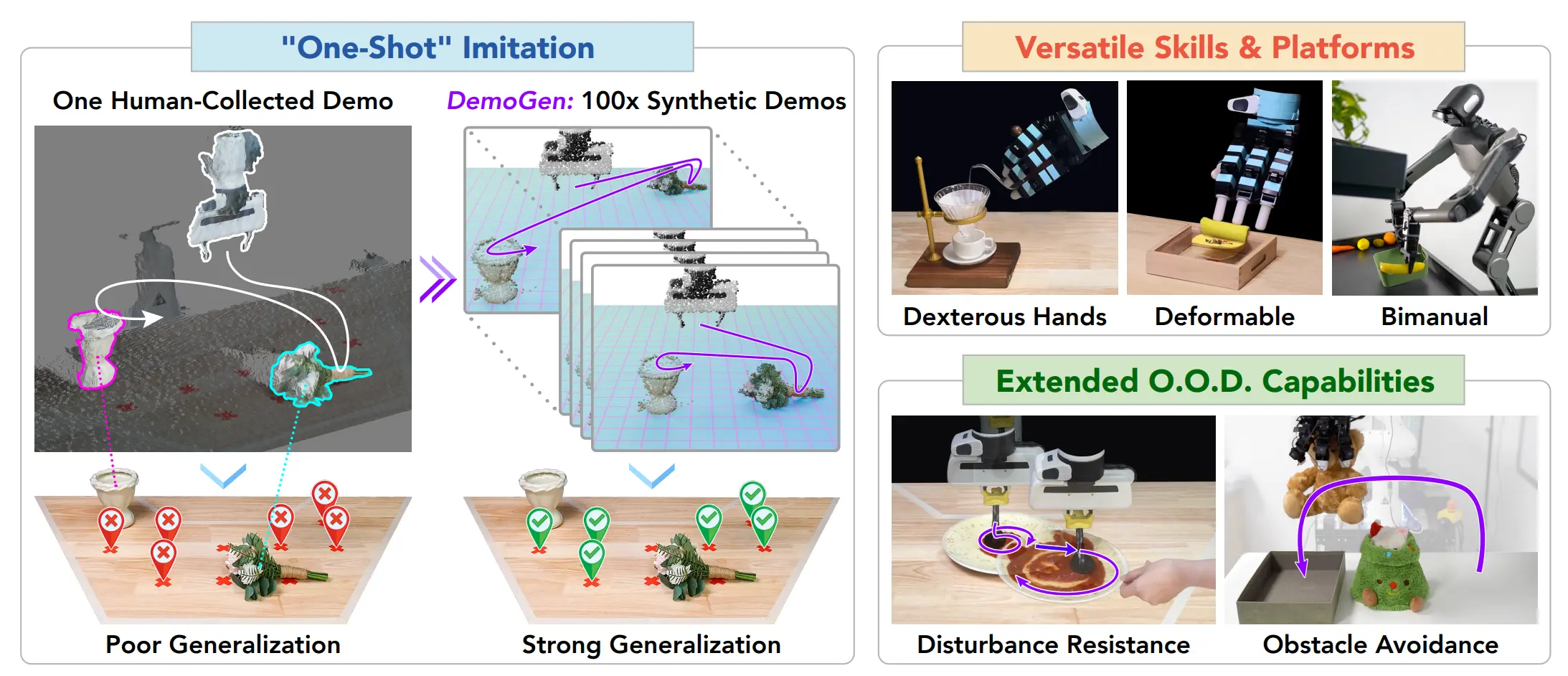
DemoGen 也算是一篇比较直观的论文,通过 Object-centric 的思路进行数据生成,检测物体的位置,并且生成连续的点云数据。这里因为训练的是 DP3D,所以说只需要对于点云进行 crop 以及变换,不需要对于画面进行补全,也会更加简洁。

本身的 Pipeline 在其中引入了一些 SAM 之类的来做 PCD 的 semantic 分割,然后用类似于 MimicGen 的思路,将不同的动作片段进行切分,然后可以进行 Layout 的 randomization,还是通过变换将不同的部分整合在一起,不连贯的头尾之间使用 Motion Planning 衔接在一起,Action 也用 Motion Planner 来获得就好。因此 DemoGen 直接合成数据,无需 replay,从效果上来看还挺不错的。
ArticuBot#
使用 articulation object 的 axis 进行数据生成
ArticuBot 提了一个方法和一个数据生成流程,方法本身依然是常规的 Policy,在这里并不聚焦于这个点,而是主要看数据生成的流程。

Articulation object,比如说笔记本或者柜子其实是大多数的,这些物体都只有一个自由度,因此假如说你标注了一个可以抓握的 pose,你就可以用这个轴进行旋转,并且通过变换得到旋转后的 Pose,进而组成 action 序列,然后生成数据。这是一个简单有效的方法,我很早之前也提出过这个 idea,但是目前他们做出来了。抓住绝大多数 articulation 物体只有一个自由度,然后对这个自由度施加变换是一个很本质的事情,并且可以借此直接解决绝大多数 articulation 数据生成的问题。
LAPA#
可以用 Video 数据来进行预训练
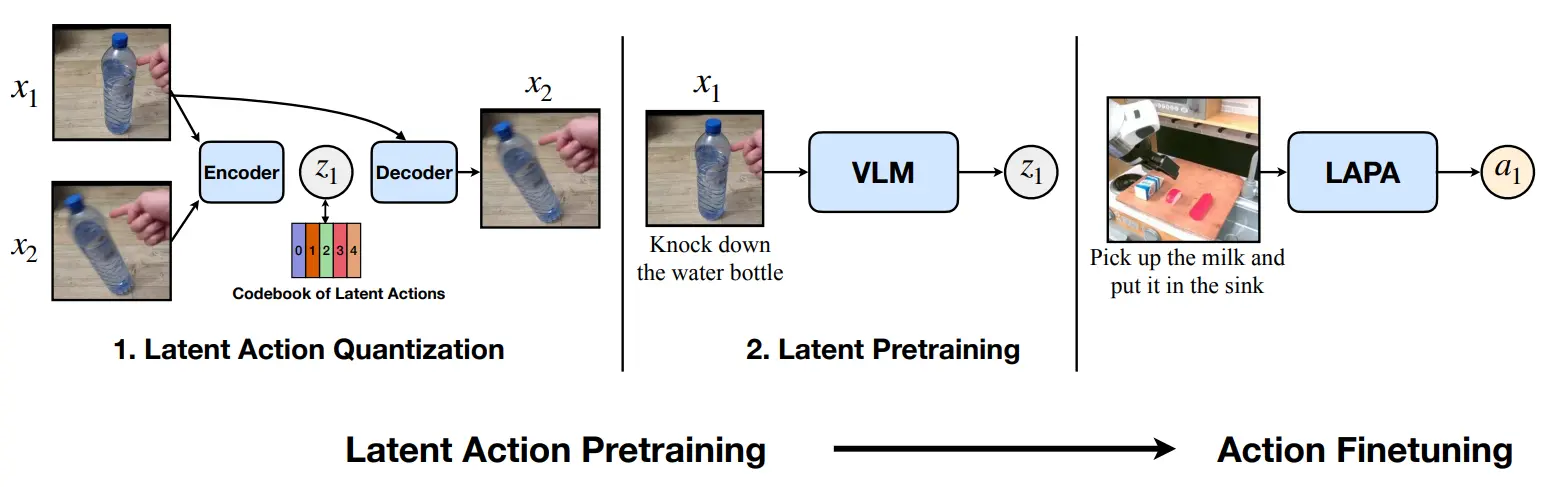
LAPA 可以作为 GR00T 的前置来看,分为了三个步骤,分别是 action 的 pretrain,VLA 的 pretrain 以及一个 finetune。本身最有意思的还是第一个环节,也就是用 VQ-VAE 来生成 latent action 的这个操作。
如图中所示, 和 是相隔了几帧的图片,输入到 encoder 里面求出来 z,之后用 和 恢复 。这个流程有趣的地方是,我们可以获得这样一个比喻,本质上 encoder 做的事情就是求逆运动学,也就是已知当前和目标,求中间的动作;而 decoder 做的事情就是求正运动学,也就是已知当前和动作,求目标。这个流程之后,我们就已经给全部的 Video 数据凭空标注了 action 信息了,这种 action 称之为 latent action。需要注意的是,latent action 并不是某种类似于 action 经过 embedding 之后转化为了 latent,而是可以理解为描述了某种抽象的 embodiment 的 action。即,latent action 和诸如 franka action 等是一个 level 的。
之后就是第二阶段,本身可以理解为在用 Video 的 V 以及 GPT 标注的 L 以及这里获得的 A 来将 VLM 预训练为 VLA,之后最后第三阶段,在真实的数据集上去 finetune。
GR00T#
解决了数据金字塔的端到端 VLA
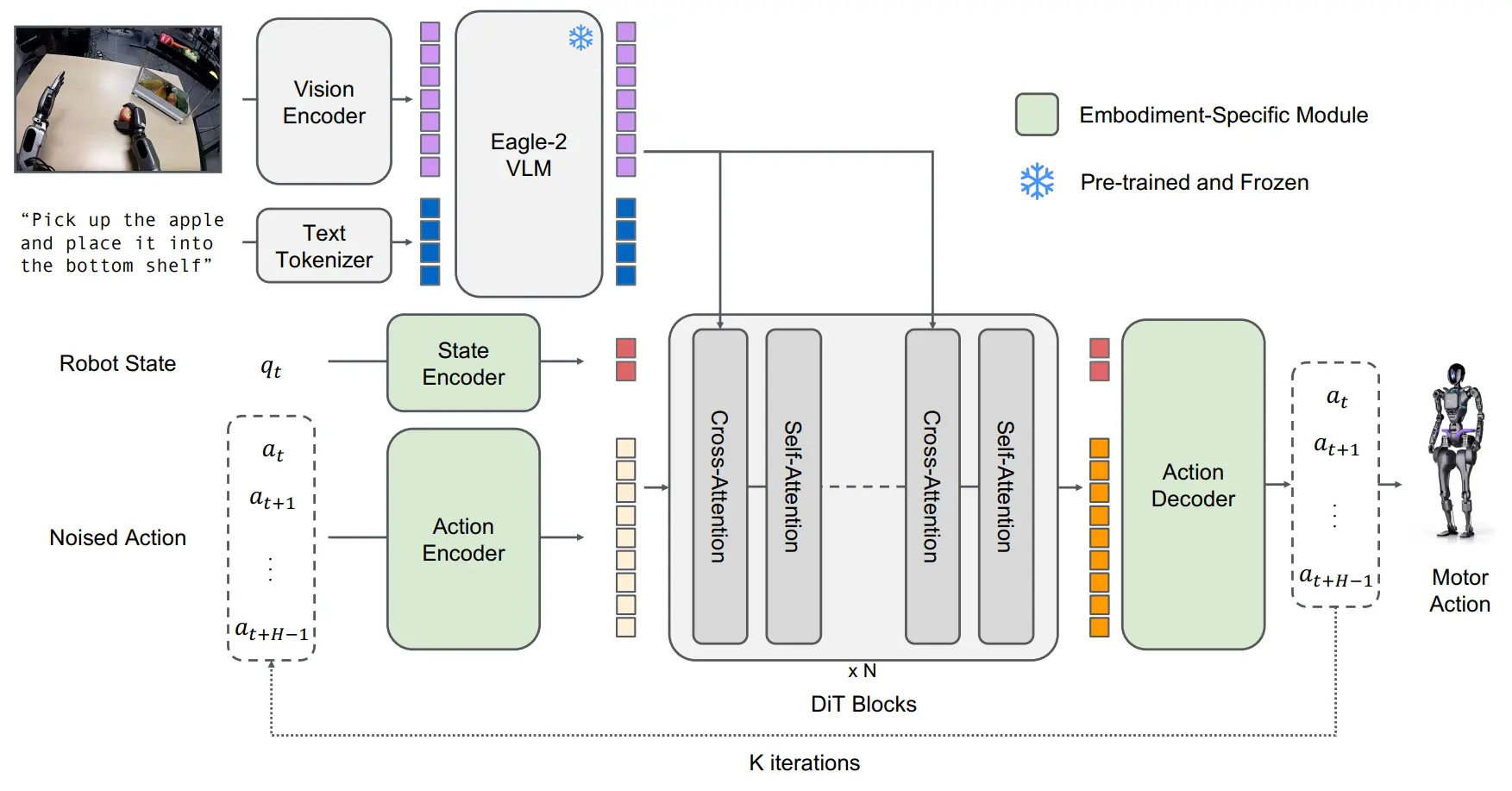
GR00T 的 pipeline 乍一看很像是某种双系统,具有一定的误导性,而且论文中也可以看到类似频率差异的表述,但是实际上只是一个快慢系统罢了。其中 VLM 只是一个 VL encoder,而下面的部分则是 action encoder,最后放到一起 fusion。
很有趣的一点是,这篇使用了 LAPA 的方法来做 Web Video 数据的标注,从而将数据金字塔,即 Real-World Data + Synthetic Data + Web Data & Human Videos 都统一为了相同的 VLA 格式。之后就是直接预训练了,没啥问题。
GR00T 的 Codebase 基于 LeRobo,使用了 Modality 的设计,非常好用,后续我们的 InternManip 从中解耦了这一框架,并且做成了训测一体的框架。
RoboVerse#
联通多个仿真平台
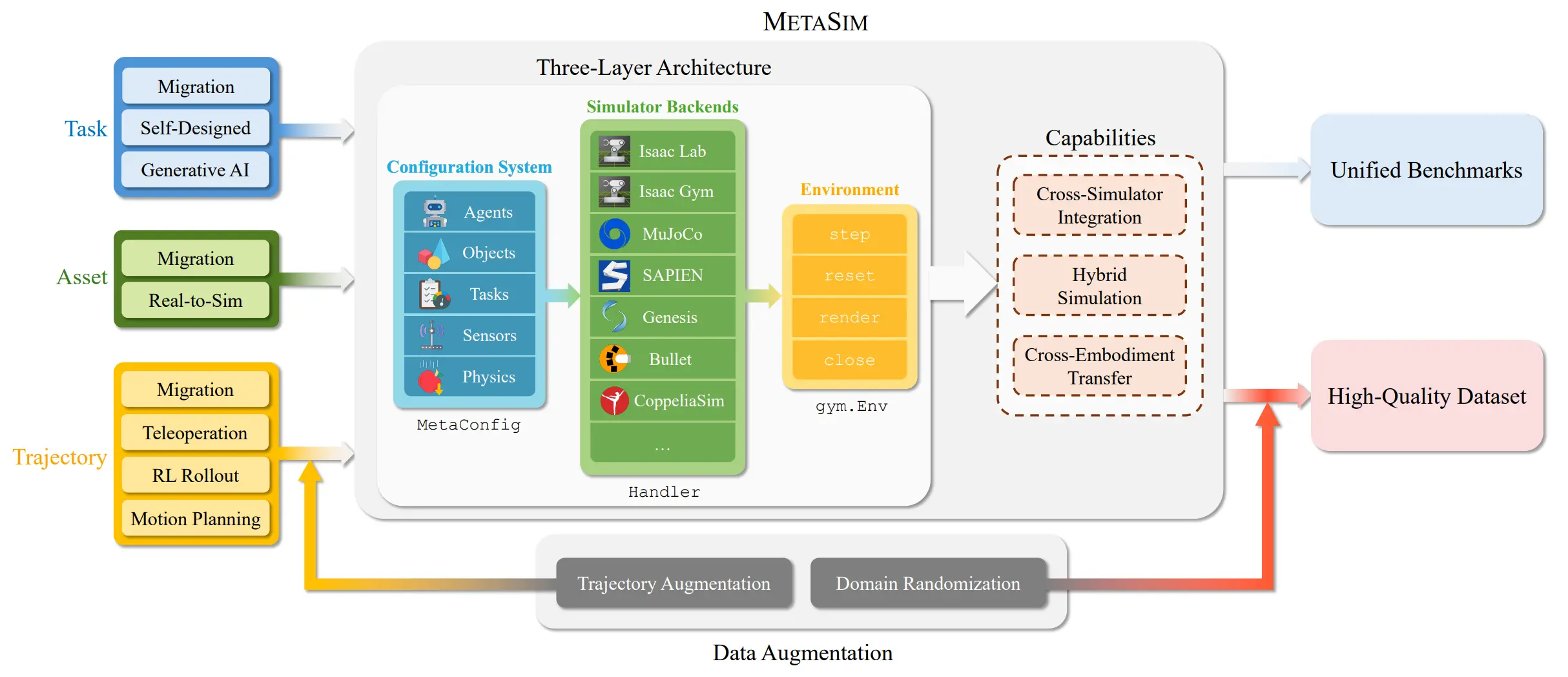
RoboVerse 是一篇工作量很大的工作。比如说近期的一些巨型工作,GRUtopia 是纯基于 IsaacSim,更多的是资产以及平台;Genesis 基于 Taichi 的技术做了仿真平台;而 RoboVerse 则是直接 Base 别的仿真平台,将它们彼此串联在了一起。所以说其看上去有很多的 contribution,但是要是说真正的核心,其实在我看来就是做了这个所谓的 MetaSim 或者说 hybrid_sim 的东西。
说白了就是在众多的仿真之间找了一种中间表征,比如说对于刚体仿真来说,就是全部的 world pose 以及 articulation joint position,这样可以将 physics 的仿真和 render decouple 开,比如可以将 mujoco 的 physics 和 IsaacSim 的 render 结合起来。但是事实上这个东西很难做 solid,毕竟不同的仿真的物理层面的内容都是不同的,比如说有的仿真支持软体,有的压根就不支持。本身的愿景很不错,但是诸如上面所说的,依然存在不少的 Limitation,更何况有谁需要比如说 Isaac 的物理 + Sapien 的渲染,确实是并未从第一性原理出发,但是依然是很不错的工作。
AgiBot World Colosseo#
MOE LAPA-like 模型
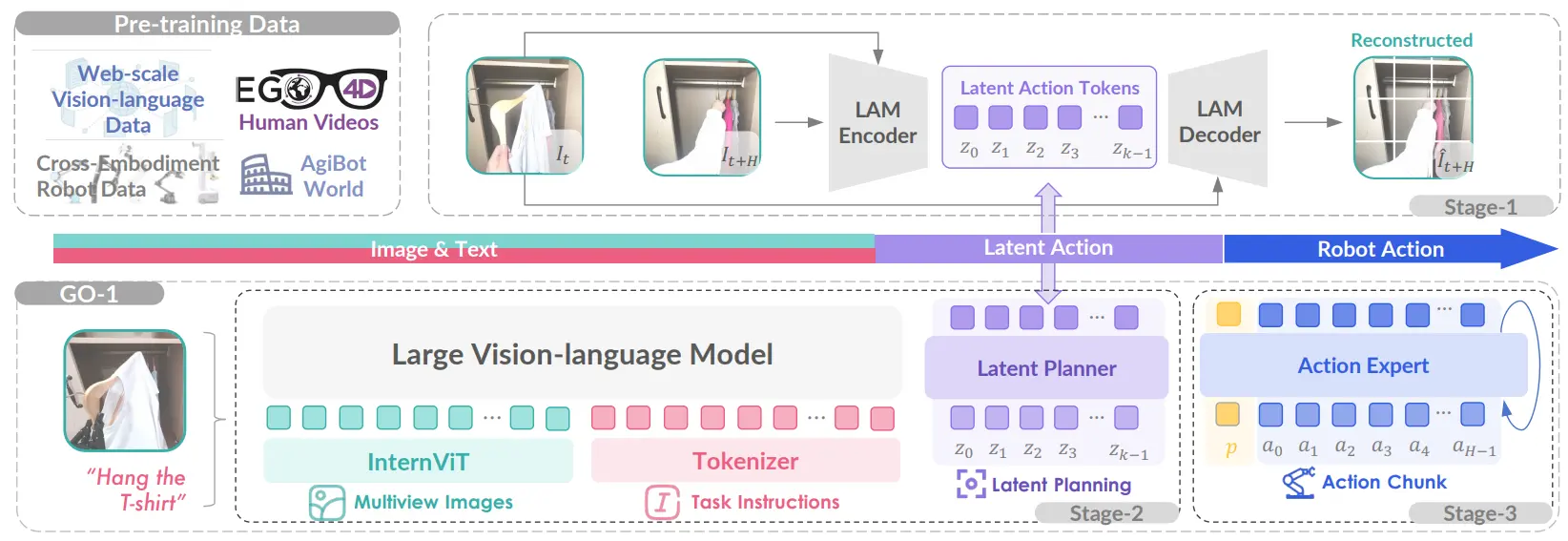
GO-1 本质上和 GR00T 还是比较类似的,本身的思想还是如何使用互联网的视频数据,而在这里也很直接的给出了解释,即将 VQVAE 的 encoder 和 decoder 解释为了前向/逆向运动学。这里面称之为 LAM,用来在 latent planner 中作为中间表征的输出。这里的 pipeline 让人感觉其实是三个不同的模型,然后在分别进行推理,之后整合成一个串行的流水线。然而事实上虽然最后实际上也是串行的,但是并非三个不同的模型。
实际上 GO-1 使用的三个模型都是同一个模型,至少进行了 MOE 设计,如下:
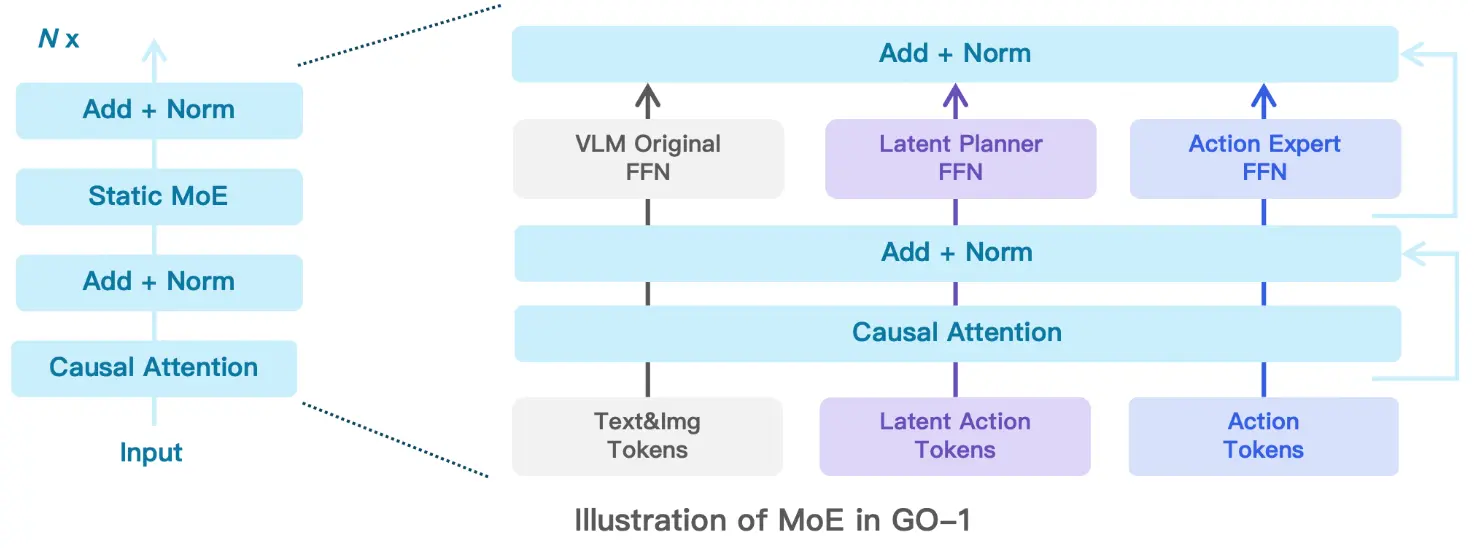
不难看出就是使用了不同的 FFN 之类的,某种程度上确实算是端到端模型,也是优雅了不少。而同时作为一个大模型,在推理的过程中也十分的有趣,是在一次推理中先预测 latent action,之后再进行降噪,感觉是人为设置了 FFN 的切换操作。
GO-1 其实相对于 GR00T 来说更加优雅。首先是使用了 MOE,可以用一个完整的模型来完成所有任务,优雅的切换不同的 FFN 也很 make sense。其次他们其实有做 latent action 的消融实验,证明了这一部分的重要性。虽然说目前感觉大家都没有 fully leverage 互联网数据,但是使用 latent 的这种表征形式来统一不同的机器人本体以及网络数据,目前来看是 promising 的,就像之前介绍的,这种使用前向以及逆向运动学来解释 VQVAE 的思路听上去就十分的有道理。同时他们也有一个巨大的开源数据集。
UniVLA#
动作解耦的 LAPA like 模型
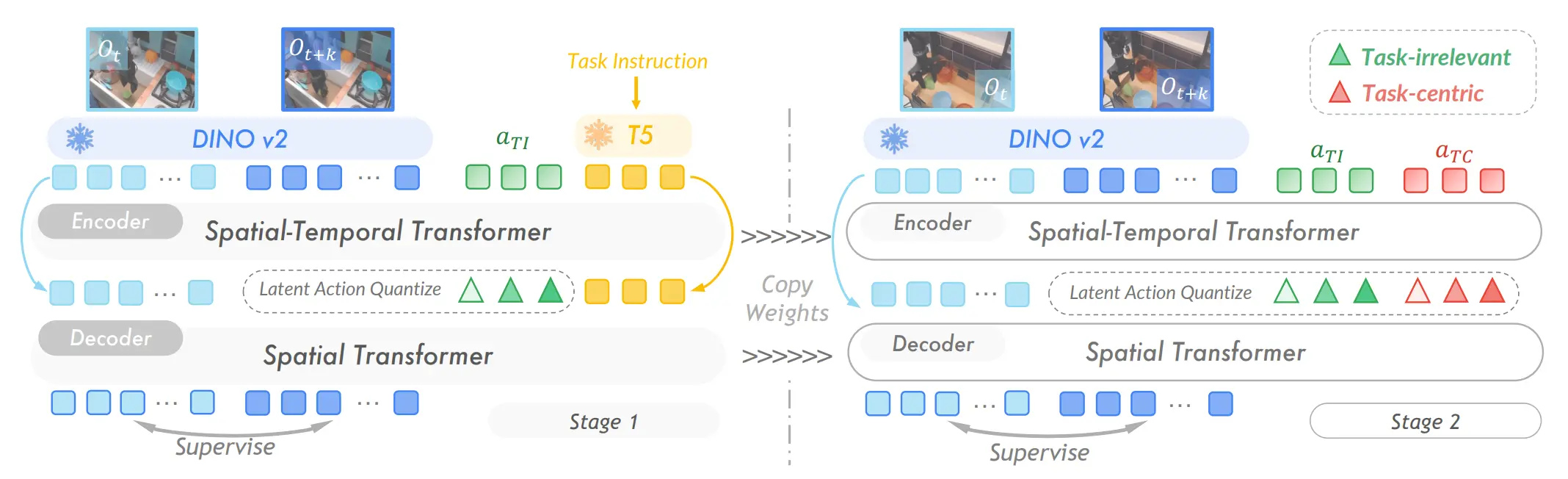
LAPA 里面很重要的问题就是并不对齐。按照这个故事来说,LAM 是一个逆运动学,但是只是通过图像做 VQVAE 来获得 Latent Action,自然里面就除了本体本身的 Action 之外引入了别的信息。其实我之前在看了 LAPA 之后提出了一个 idea,但是一直因为时间问题没有上手,把里面的理解搬过来。
事实上导致画面变化的原因有很多,我们可以归纳为以下三点,即环境变化、Action 以及 Camera 变化。其中自然环境变化包含了环境自身的变化(其他的个体也算是环境的一部分)以及 Embodiment 与环境交互导致的环境变化。预测环境变化是一个不错的能力,但是属于 World Model,在 VLA 的 A 中属于冗余的信息,并且和正规 VLA 数据一起使用的时候,信息量的不统一可能导致 co-training 的结果不好。
在 UniVLA 里面比较不错地解决了这个问题。首先用 T 和一些可学习的 Token 一起作为输入,并且这时候认为这些 Token 里面吸收了全部的与任务无关的东西,之后把这部分 frozen 住,再学任务有关的 token。在这样子处理之后,也就得到了更好的 Action Token 了。
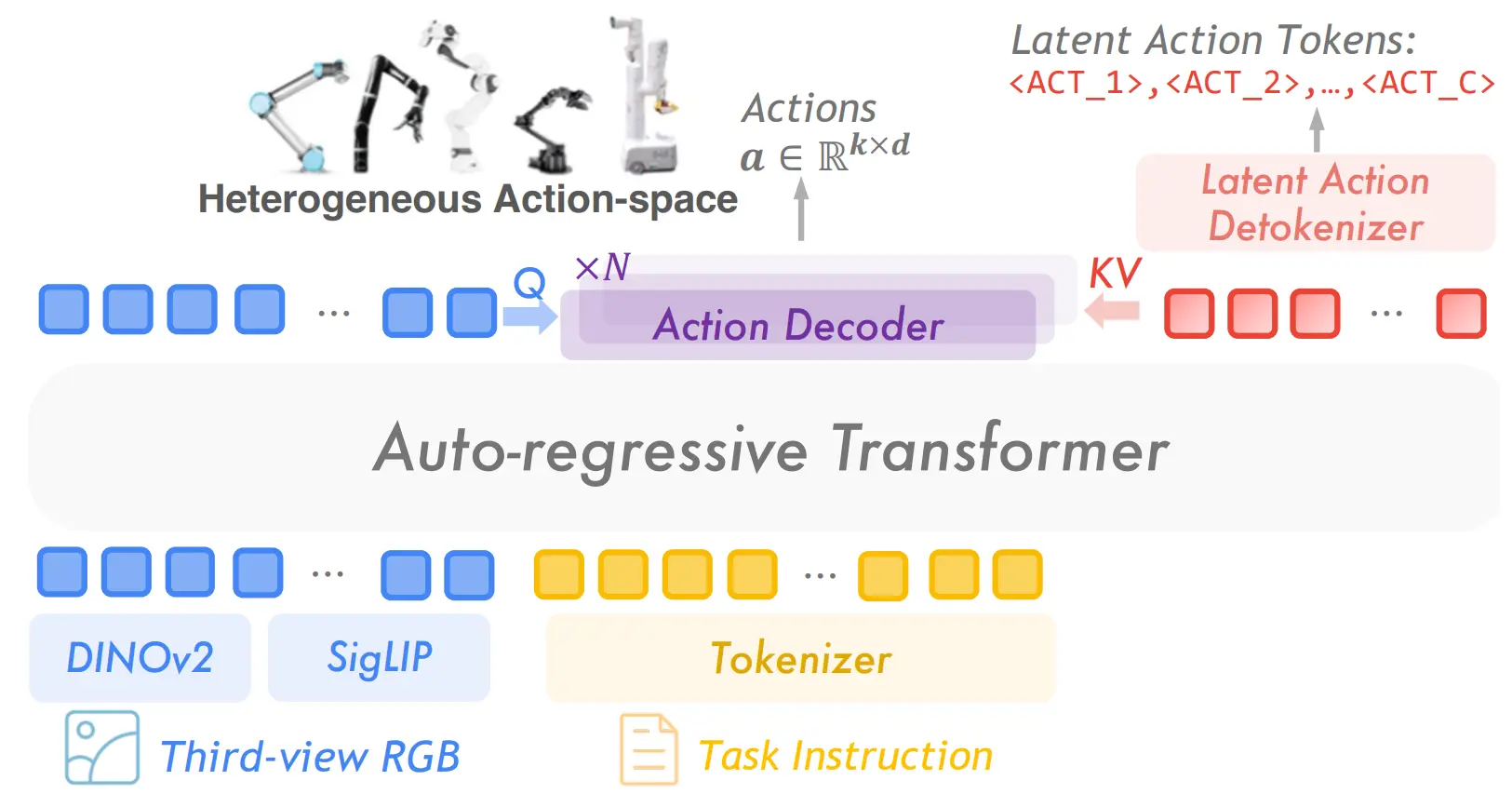
之后其实就是 OpenVLA 的范式,输出的也是 Latent Action,再过一个 Action decoder,从而输出动作。
Pi0#
VLM + Flow matching 经典之作
经典之作。简单理解一下 Pi-like 的范式,也就是图像/语言/状态编码成 token → 输入 VLM → 得到上下文 token;之后动作 token(随机初始化)在 action expert 中作为「预测目标」,这里面上下文 Token 来作为 cross attention 来当作 condition;使用 flow matching loss,训练模型将噪声 token 转化为真实动作轨迹。
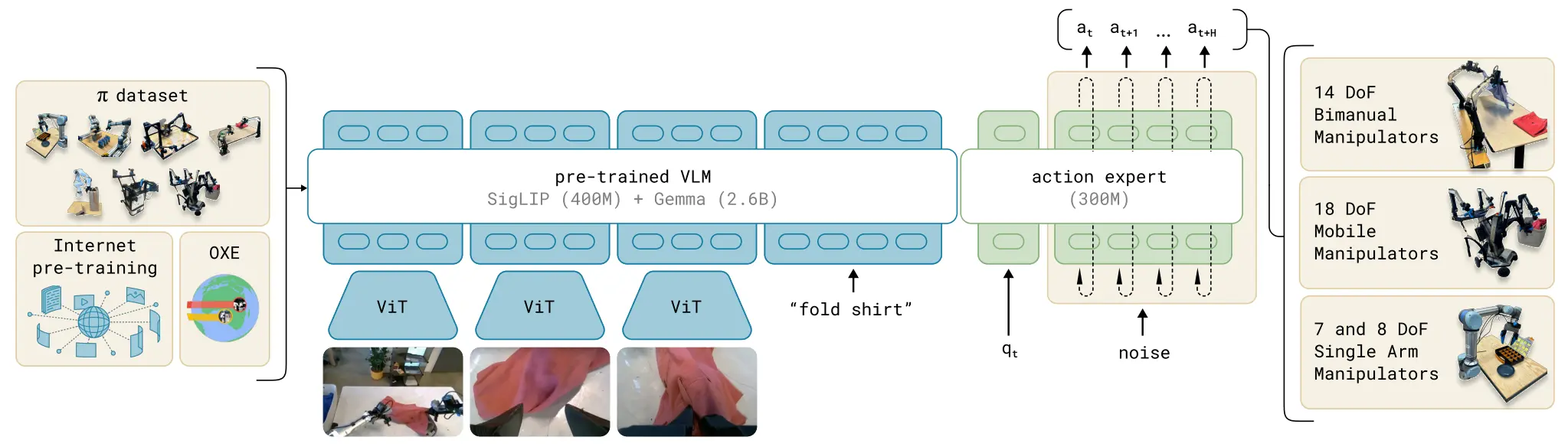
Pi0 的 Flow Matching 使用的实际上是 MoT 的方案,直观上来说,就是 VLM 先 Forward,但是会进行 KV cache,然后 Action model 本身是用 VLM + 自己的 VQ 一起进行 Self-attention 的,并且对输出来进行 Flow Matching Loss 的迭代。
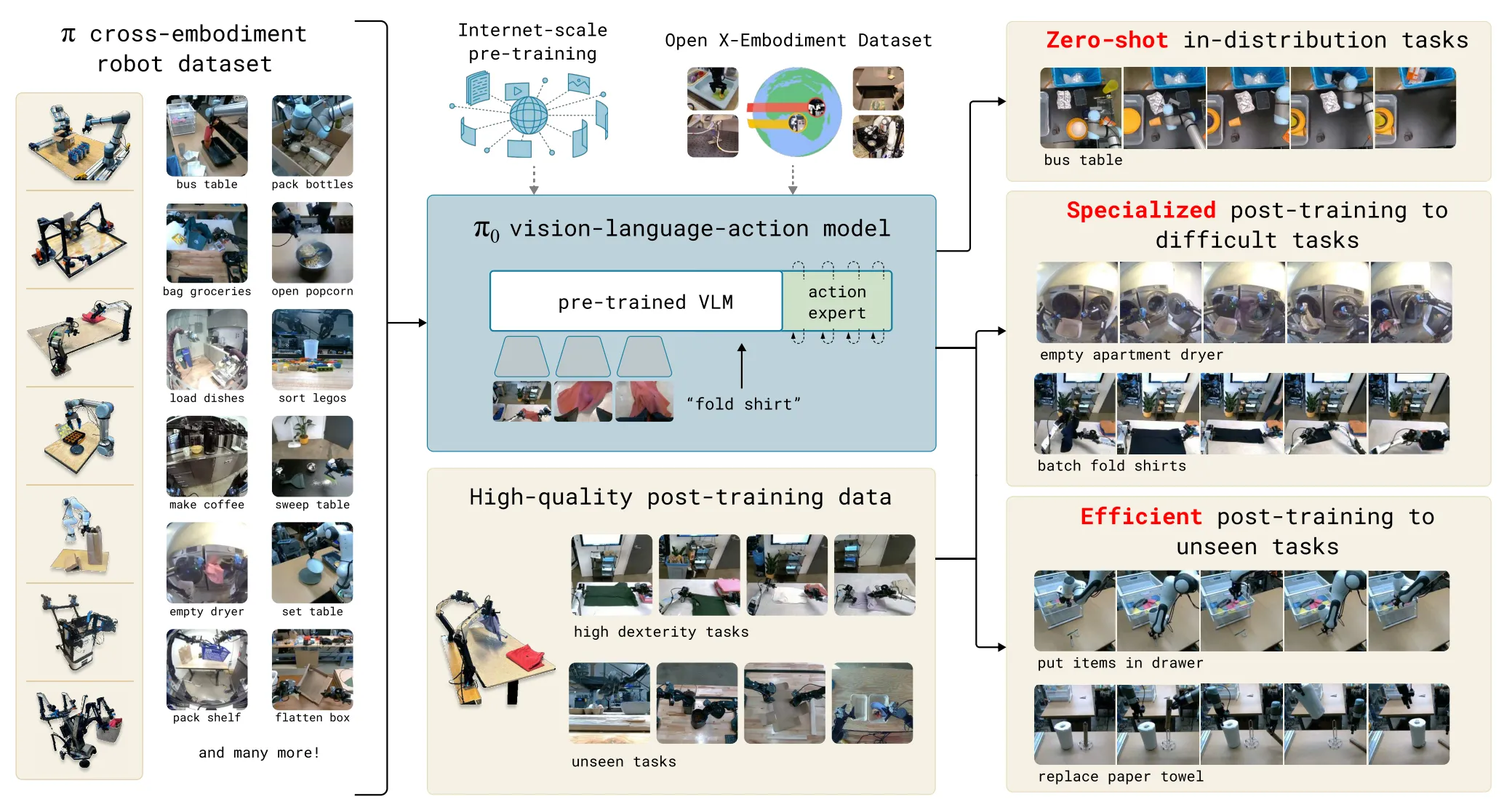
Pi0 用了巨量的真机数据(10,000 小时),两秒一个长度的语言标注,产出的是目前几乎是最好的 VLA 模型。
Pi0.5#
VLM + Flow matching 经典续作

Pi0.5 的 Pipeline 在总体上和 Pi0 还是比较相似的,依然是采用了 MoT 的设计,以及 VLM + DP 的结构。
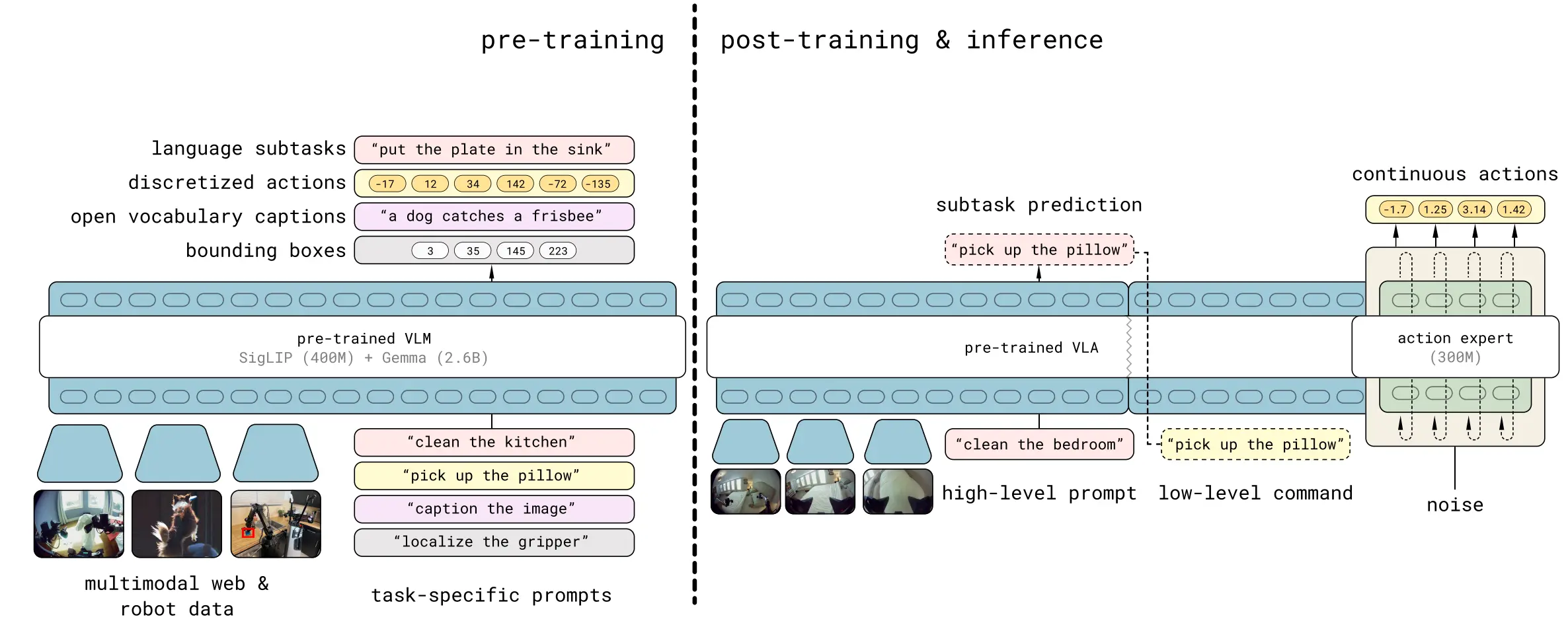
主要的改动点包括两个。
其中之一是在 VLM 上进行大量的 Pre training。包括使用 VQA, discretized actions, sub tasks 以及 bounding boxes。这一改动使得在 inference 的过程中,可以让 VLM 使用两次,第一次是直接使用 VLM 来拆解 Subtasks,第二次才是类似于 Pi0 的正常 MoT 推理流程。
另一个则是使用了 FAST 编码器,并且让 VLM 已经可以输出离散动作了,这里可以看出 Pi 系列工作的一个趋势或者说认知,他们正在让 Action 能力本身从「尾部」的 DP 迁移到「头部」的 VLM 中,从而更加让 VLM 将之前先验以及后续 co training 进来的 VLM 能力和 Action 能力耦合在一起,而不是显式 decouple 开,从而增强模型的泛化能力。
GraspVLA#
使用大量仿真数据训练多阶段 VLA
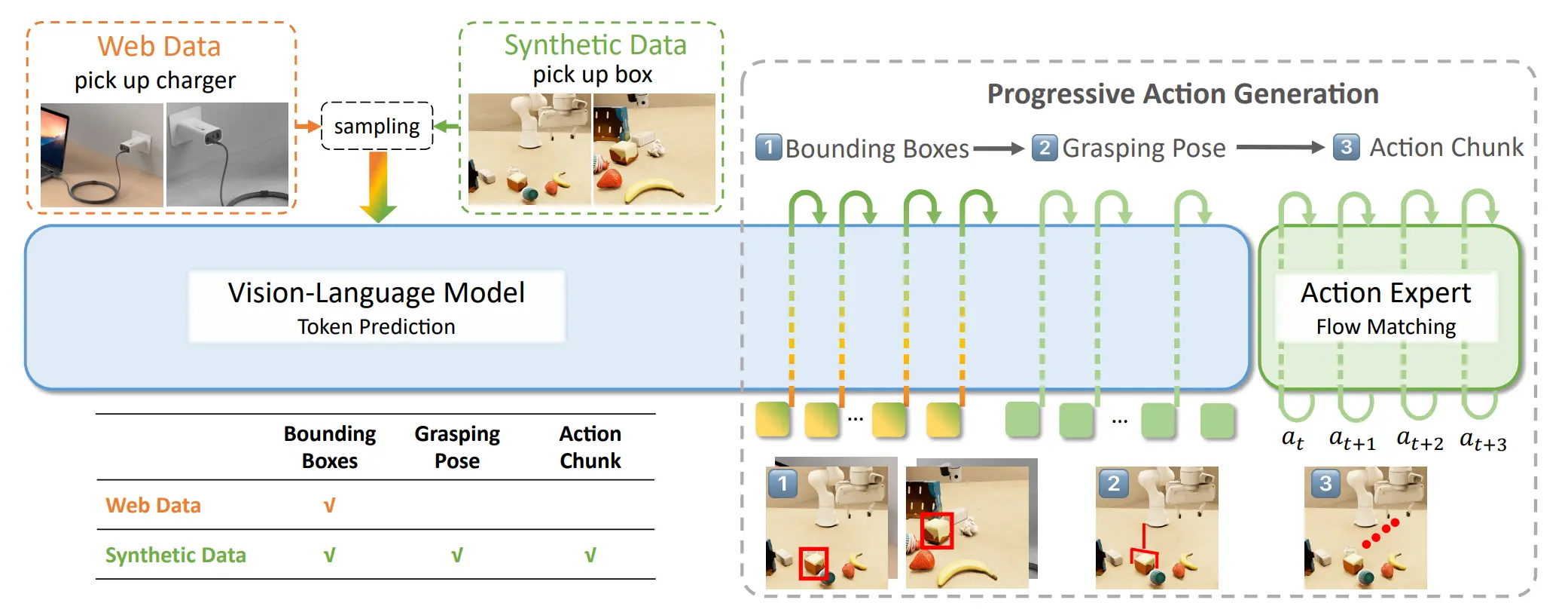
本身模型不难理解,VLM 被训练去预测 2D bounding box;同时对于合成数据,VLM 进一步预测抓取位姿(在机器人 base frame 中),以及对于合成数据,Action Expert 会根据VLM 的 KV cache 以及输入图像 & 文本和中间推理的 box 和 grasp tokens,来生成一个连续的动作段(action chunk)。所以说模型在 bbox 阶段还是利用好了大量的互联网数据,以及本身也有依然是 VLM + DP 的范式。
这个事情的 Highlight 其实在于利用了大量的 Grasp 的仿真数据。实际上这件事实现上并不是那么困难,但是能做 work,还是证明了这条道路的可行性,出于个人的私心来看,确实非常喜欢。
GRAPE#
使用强化学习进行轨迹级别的学习,即 TPO
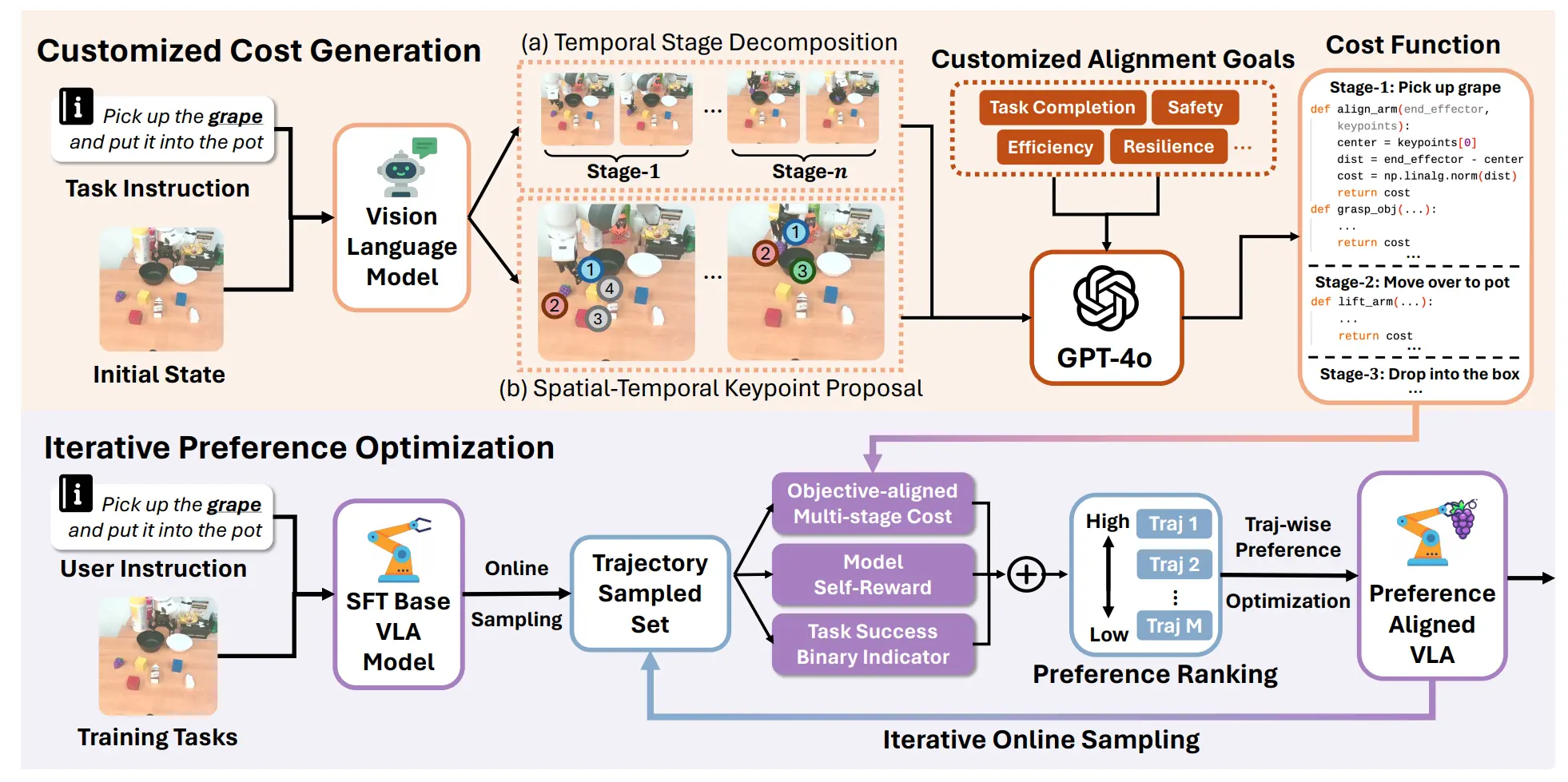
GRAPE 大致上还是比较有趣的,流程大概是先训练一个 SFT 的模型出来,之后用这个模型生成一批数据,这一批数据可以用大模型生成的 Goal(比如说平滑度或者接近物体之类的)进行打分(这里面先拆分 stages,之后分别打分等,有一套自动流程),和模型自己评估的分数以及是否成功结合起来成为总分,之后按照分数进行排序,用一个他们写的 TPO 公式来训练。
公式很好理解,就是偏向 w 不偏向 l,这里面 w 和 l 都是轨迹,w 是好的,l 是差的,组成了 pair。
总的来说还算是有意思,这样子的训练某种程度上也算是经典的左脚踩右脚了(或者说其实就是以经典强化学习 offline 的算法外面套了一层 [X]PO 的故事),不过本身不断积累成功,而且多训练了不少的 steps,本来就可以带来性能提升,本身依然不 scalable。
这里面有意思的反而是他说的故事,人类采集的数据里面包含了大量的偏好,然而这些偏好没有明显标注,因此有必要加入额外约束。奈何我现在更加看重泛化,到了更加追求成功率的阶段,RLHF 或者 RL Goal F 的范式确实是很有意思的。比方说在随机生成数据的时候,会发现某些完成方式的成功率更高,那么我不会选择保持多样性,而是把成功率低的完成方式的数据 filter 掉,追求模型的 awareness of 更好的完成方式。