
具身十日谈:VLA 为什么需要 VLM
VLA 相较于其他 Manipulation 模型,最显著的区别便是引入了 L(anguage) 作为 condition,主流的范式至今为止仍然 VLM 作为核心组件,而我们为什么需要 VLM,如何利用 VLM,这对应着一系列的思考。
前言#
诸如 ACT1 以及 DP2 等早期 Manipulation 模型,本质上均保持着 Vision-Action 的输入输出模态,也就是通常所说的 VA Model,缺少 Language Condition,这意味着本质上此类模型的目的并非训练一个通用的模型并且进行任务间的泛化,而模型本身的改进也聚焦于如何更快进行单一任务的拟合以及对于 Position 等内容的泛化。
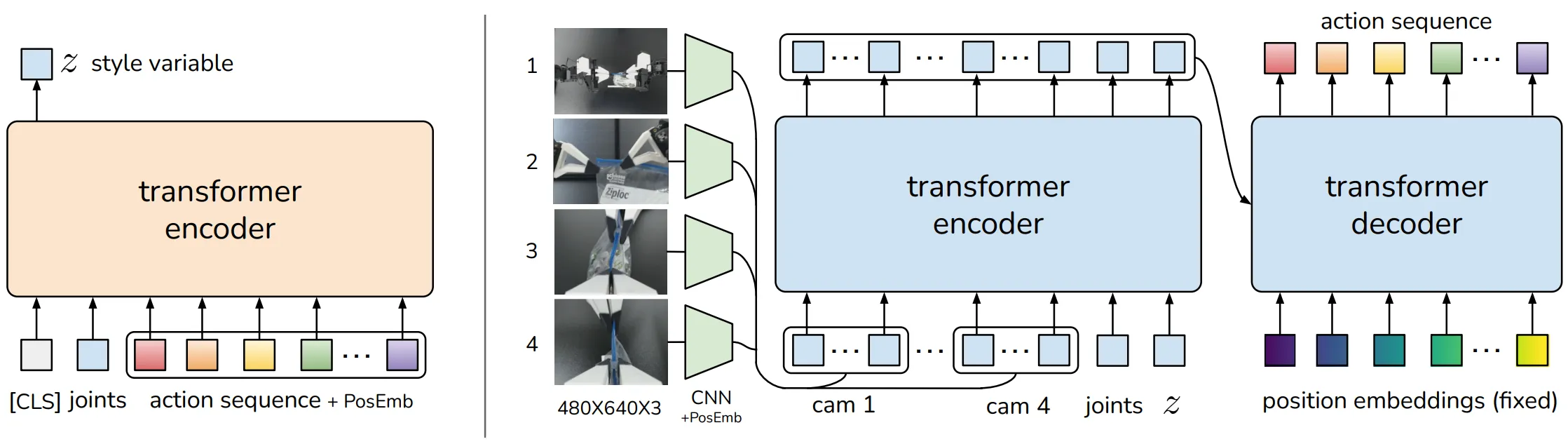
伴随着 LLM 的兴起,Scaling law 展现了其可能性,谷歌的 Robotics 团队以及 Everyday Robots 采集了大量的真机数据,并且训练了鼎鼎大名的 RT-13,尽管 RT-1 出于时代的局限性并未采取 VLM 的多 Encoder + Transformer 作为 Fusion 的架构,但是依然展现了跨语言的泛化能力。
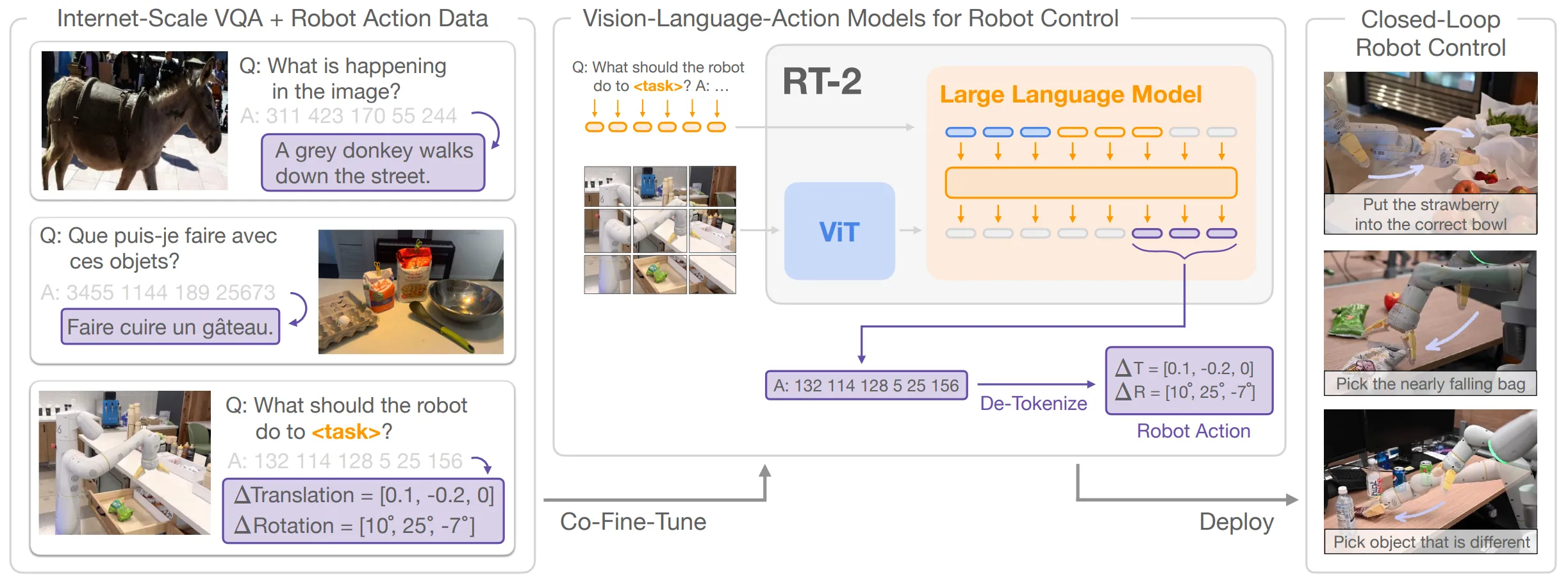
RT-24 依然由谷歌团队提出,并且使用了标准的 VLM 架构,而后的 OpenVLA5 将这一架构的开源实现提供给了整个学界,自此将 VLM 作为核心组件的范式开始流行。
为什么我们需要 VLM#
正如 上一篇博客 所提及的,数据是具身智能的基石,而基于各种方案生成的数据质量,决定了模型可以走多远,但是一个残酷的事实是,在 LLM 以及 VLM 领域中发展的漫长时间中,最为庞大且体现 Scaling law 以及泛化的模型,都是基于数十 Million 起步,乃至数十 Billion 数据训练的庞大模型,而其中每一份数据都是在彼此之间具有多样性的。
我们希望某个具身大模型,可以具备和 VLM 同等,甚至在具身相关的任务(比如说 Planning/Grounding/Trajectory/etc.)中获得更强的理解以及泛化能力,这毫无疑问意味着在语言作为任务描述的情况下,我们需要数以百万的 diversity 的 Tasks 才可以获得一个自己定义架构的 pre-trained VLA。

更何况这一点事实上现在对于 VLM 的数据体量尚且不现实,以至于 VLM 需要基于 LLM 的预训练权重进行训练,更何况 VLA,因此我们一定要引入 VLM 在整体的框架中,这是毫无疑问的。毕竟不说百万 Diversity 的 Tasks 了,诸如 OXE6 等提供了百万量级的数据,但是绝大多数数据依然是短程的单一 Tasks 上重复采集的数据。尽管学习动作信息对于 VLA 同样至关重要,但是仅仅从 VLA 数据中获得 VLM 级别的理解以及泛化,这并不现实。
引入 VLM 的方案是一种 VLA 的设计思路,而显然另一种范式的兴起也不可忽视,也就是 World Model 的范式,或者说,使用 Video Prediction Model 作为 VLA 的主干部分,并且辅佐以 DP 或者 Detokenizer 进行 Action 的输出。
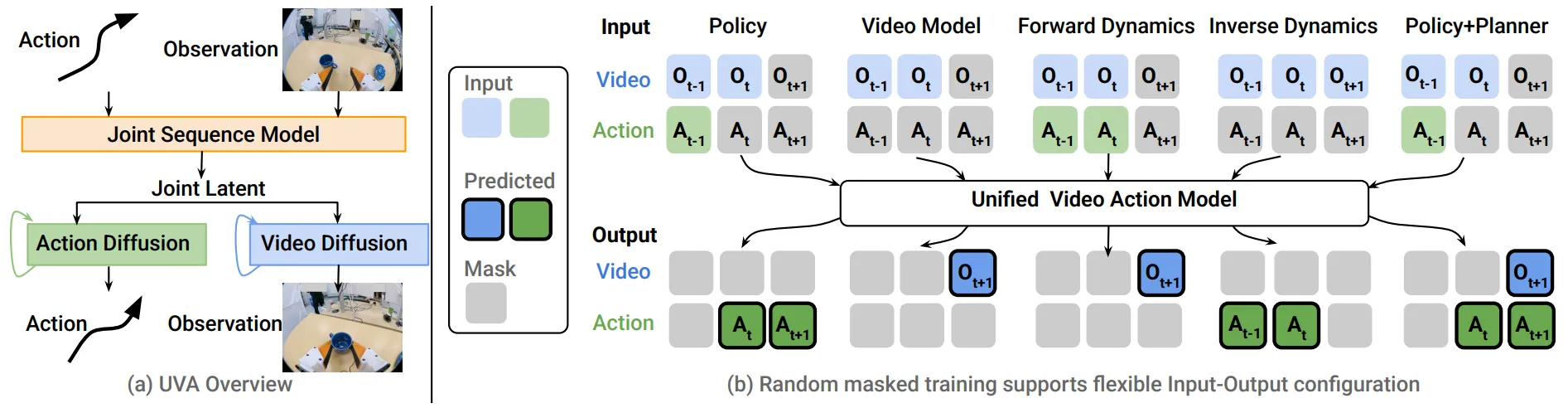
相关领域的代表工作包括 Unified Video Action Model7 以及 Genie Envisioner8 等,而正如上一篇 博客 所提及的,Video Gen 的泛化性以及质量,对于 VLA 来说依然是一个有待解决的问题,更何况作为一个 VLA 模型,需要进行推理并且执行复杂指令。
综上来看,不难看出,在 VLA 中引入一个 VLM 作为主干,是短时间内的刚需。
VLM 的两种范式#
对于将 VLM 加入 VLA 的范式,主要包含两种流派,依照整个领域中最有影响力的相关工作,我将其概括为,OpenVLA-like 的架构以及 Pi-like 的架构,并且在此基础上,包含了大量的变种。
两种 VLA 范式,其主要区别便在于,在 VLA 输入 Image, Language 以及 State(可选,当前部分模型无需输入当前 State)后,VLM 是否直接输出 Action。
OpenVLA-like#
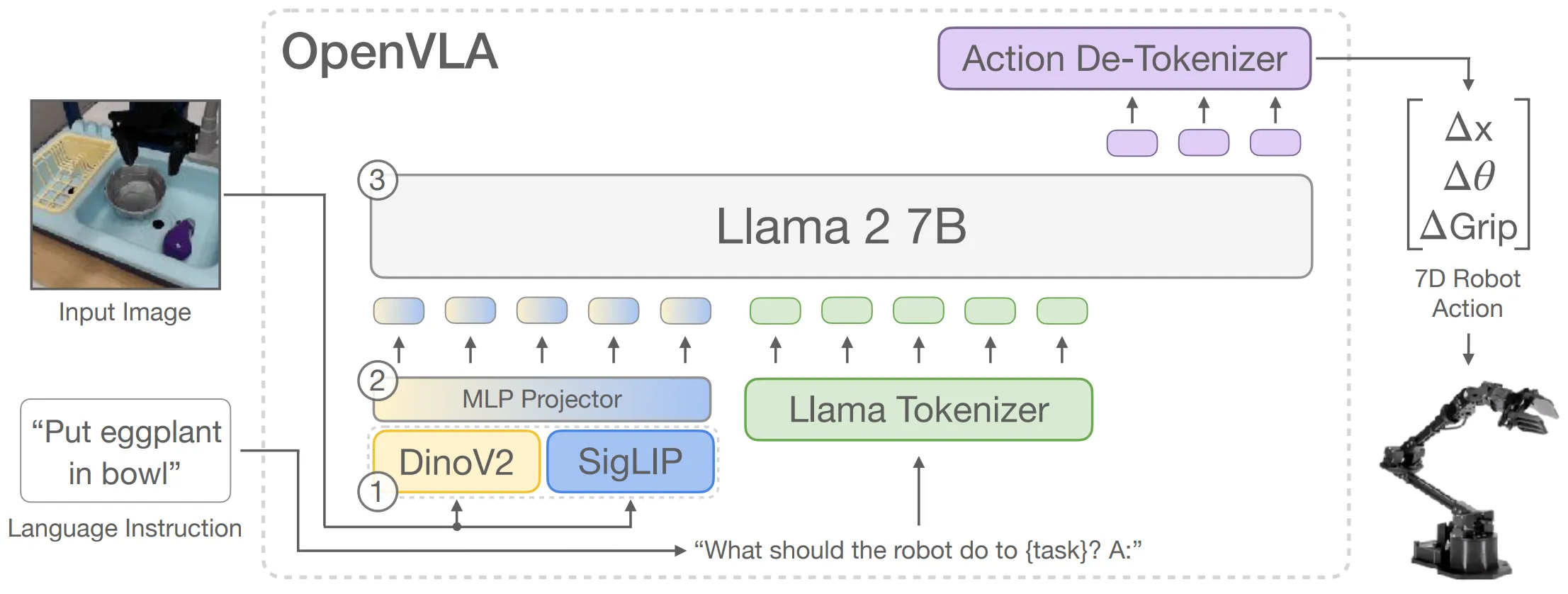
OpenVLA 的结构简洁明了,如图所示,这种结构受到诸如 RT-2 等模型的启发。图像同时经过 DinoV2 以及 SigLIP 作为 Vision Encoder,之后 Concat 进入 Projector,作为模型的视觉 token,而语言部分则经过 Llama2 的 tokenizer,并且二者 concat 之后输入 Llama2 的 backbone。这一 Setting Follow 了 Prismatic VLMs9 的 Setting。
OpenVLA 的核心在于让模型直接输出 Action token,这一过程实际上是将动作维度离散化为 256 个区间,并且使用 Llama 分词器中使用频率最低的 256 个 token 表示。
事实上在笔者看来,直接使用 Llama 输出 Action token 是十分有风险的,毕竟本身的 Action token 并不是和语言 token 在统一语义空间,直接使用 action token 会导致模型本来输出的 logits 里面概率最低的 256 个词汇如今概率需要是最高的一批,这导致模型在 Finetune 的过程中几乎要推翻自己之前学到的分布。而同时,在 co-training VQA 以及 VLA 数据的时候,此时一方面 VQA 中这些 Token 概率需要接近 0,一方面 VLA 中需要接近 1,这使得模型在强行学习双峰分布。
Pi-like#
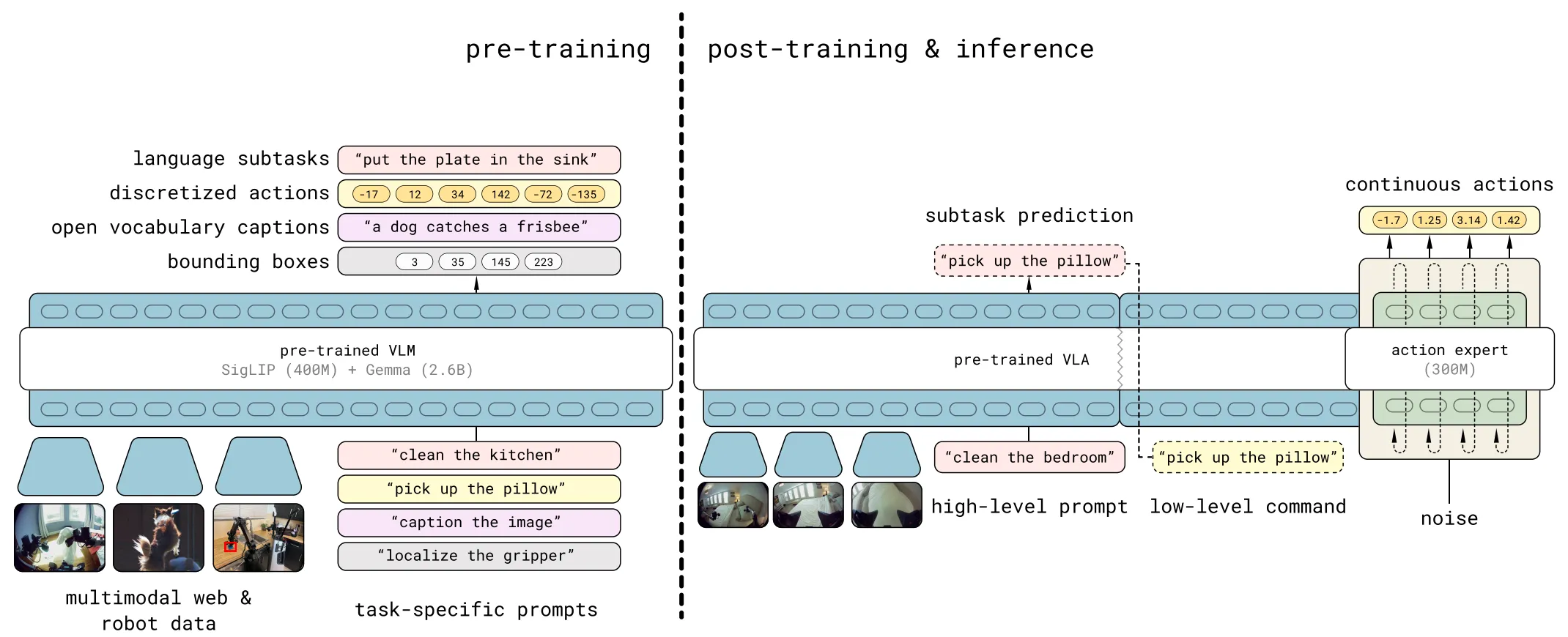
Pi-010 以及 Pi-0.511 的范式则同样本质,且某种程度上与 Unified Model 当前的范式基本一致,VLM 在训练 VLA 数据的过程中输出 hidden state,之后使用 hidden state 作为 condition,并且使用 DP/Flow Matching 进行 Action 的输出。
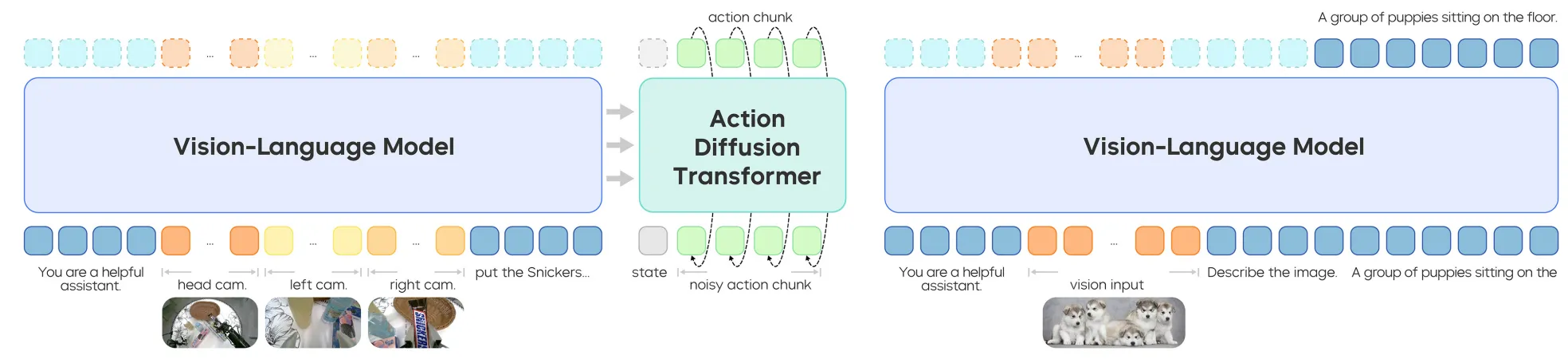
而向前追溯,则可以溯源到 2024 年的 TinyVLA12 以及 CogACT13 等,均是使用相同的思路。相似范式的模型还包括 GR-314 以及 InstrucVLA15 等,均使用 VLM 作为 backbone,并且使用 DP/Flow Matching 进行 Action 的输出。
这套框架之所以本质,包括两个特点。
其一,完整的 VLM 保留了 VLM 完整的能力,使得模型可以在多个训练 Stage 中对于具身相关的 VQA 任务先进行预训练(在这些数据集上进行 Finetune),再之后进行 VLA 的训练,使用 Hidden state 进行 Action 的输出。一方面这可以让模型在 VLA 相关任务上具有更好的性能,另一方面不存在 OpenVLA 类似的多峰问题,可以进行 co-training。
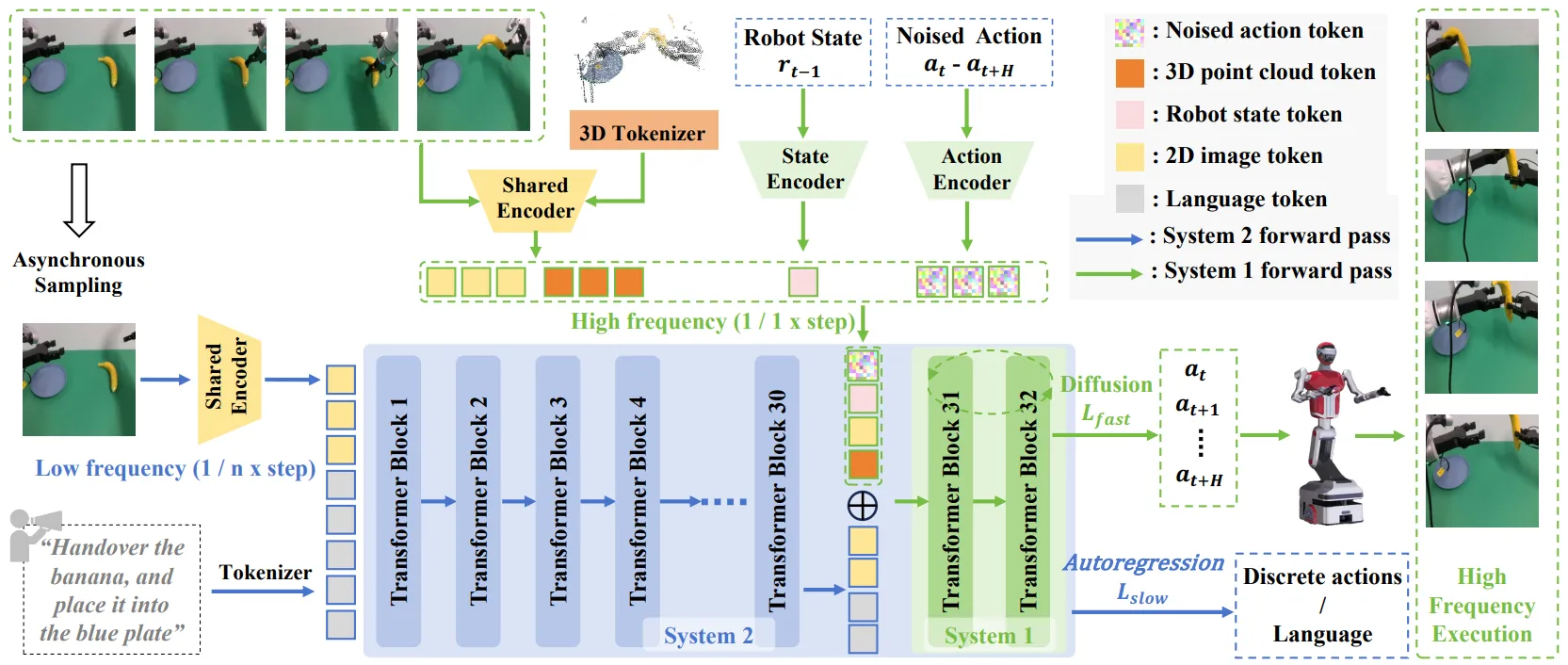
其二,使用 DP 或者 Flow Matching 进行 Action 的输出,这使得模型可以更快输出更大的 Action chunk,增大了模型的推理速度。同时对于模型来说,使用 Condition 为后续的特征融合提供了更丰富的信息。诸如最近 DinoV316 横空出世,自然就可以将 Vision 信息 concat 在 hidden state 上,而诸如三维感知等内容,如果在 VLM 的前端输入,对应的细粒度信息难以从 hidden state 中传达,而是主要剩余 semantic 信息,但是对于可以将 3D encoder 的输出 concat 在 hidden state 上,这使得模型可以获得更丰富的空间感知能力,如 FiS-VLA17 便是采用了此方案。
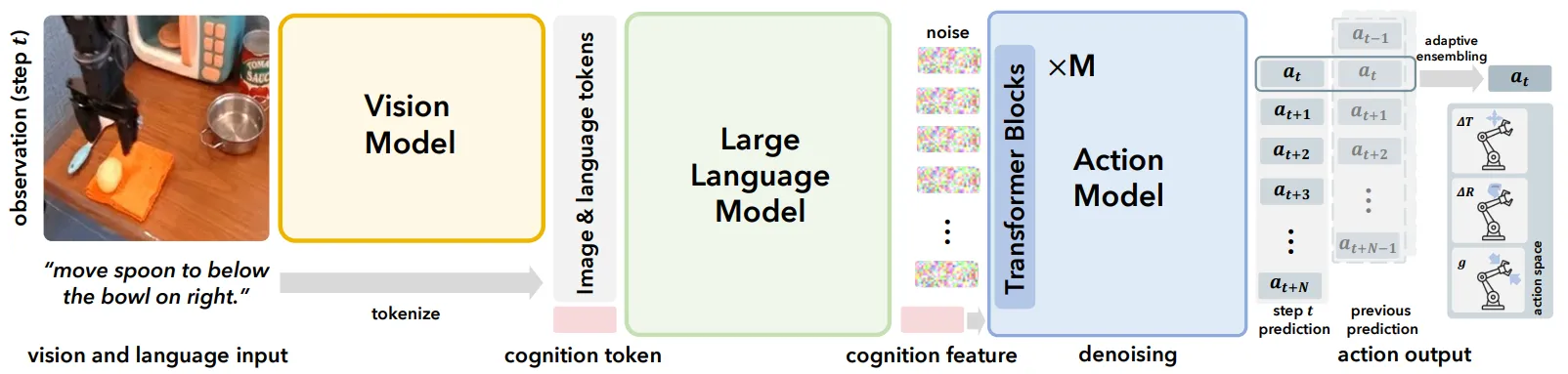
在此基础上,实际上 Pi-like 的范式在 VLM 与 DP 的连接方式,以及整体的训练流程上均进行了大量的讨论。早期的 TinyVLA 在一阶段的 VQA 预训练之后用 LoRA 进行 finetune,将 VLM 的 embedding 直接作为 DP 的 Condition;而之后 CogACT 则将连接的方式换为了 Cognition Token,也就是类似于 Bert 的 CLS Token;Pi-0 以及 Pi-0.5 使用 MoT 作为连接方式,也就是对于 VLM 的推理保留其 KV Cache,并且将 KV 和 Diffusion 的 KV 进行 Concat,一起进行 denoise 的学习。
假如说使用 Pi-like 的范式搭建模型是更加本质的,那么剩下的事情其实就很明显了,对于模型来说,留给我们的无非是几个关键问题:
- 如何引入 VLM 的先验知识
- 我们是否需要保留全部的先验知识,还是选择性地保留,如果需要选择,保留哪些
- 我们需要以何种方式将 VLM 的信息传递给 Action Expert,例如,什么结构或者传递哪些信息
- 我们如何设计一套训练流程,比如 KI,比如 Co-training,比如 Multi-stage training
- 如何具有更好的具身操作能力
- 我们是否需要用 VLA 数据进行预训练,如果是,如何训练,哪些数据是关键的
- 我们是否应该引入其他的表征信息,如果是,引入哪些,比如深度或者触觉
- 以及一些别的问题
- 我们是否需要进行强化学习,这是否是必经之路,如何设计通用的奖励模型或者奖励函数
- 一些特殊的形式,比如说 interleave, reasoning, 等
可以遇见的是,在未来客观的一段时间内,全部的主流论文都会在这些内容上进行探索。
总结#
回顾 VLA 的发展史,其实一切才刚刚起步,但是范式已经开始快速迭代并且收敛。由于 VLA 需要的泛化能力,仅凭大量的真机数据,难以达到 VLM 级别的泛化,因此不得已借助 VLM 的能力,而如何利用 VLM 的能力,则是 VLA 范式中最为核心的问题。
OpenVLA-like 以及 Pi-like 的范式是 VLM 在 VLA 中的两种主流范式,而暂时在笔者看来,Pi-like 的范式更具有潜力,并且可以进行更深层次的探索,至于 World Model,则尚且并未完全成熟,但是伴随着视频模型作为基模的不断发展,依然具有不可小觑的潜力。
脚注#
-
Diffusioni Policy: https://arxiv.org/abs/2303.04137 ↑
-
OpenVLA: https://arxiv.org/abs/2406.09246 ↑
-
Unified Video Action Model: https://arxiv.org/abs/2503.00200 ↑
-
Genie Envisioner: https://arxiv.org/abs/2508.05635 ↑
-
Prismatic VLMs: https://arxiv.org/abs/2402.07865 ↑
-
Pi-0.5: https://arxiv.org/abs/2504.16054 ↑
-
TinyVLA: https://arxiv.org/abs/2409.12514 ↑
-
CogACT: https://arxiv.org/abs/2411.19650 ↑
-
InstrucVLA: https://arxiv.org/abs/2507.17520 ↑
-
DinoV3: https://arxiv.org/abs/2508.10104 ↑
-
FiS-VLA: https://arxiv.org/abs/2506.01953 ↑